ITRI Application Whitelisting
技術簡介
提供從NN模型到AI加速器硬體的端到端編譯環境與優化技術,可以針對硬體特性進行運算優化,讓不同深度學習框架所開發的NN模型可以在不同硬體平台上達到更佳的執行效能,為AI晶片廠商提供了編譯器框架的基礎,大幅降低了自行研發深度學習編譯器的門檻,減少開發者把深度學習模型部署到不同硬體設備的複雜度,也是AI應用與晶片產業快速發展的重要關鍵之一。
舉例自駕車輛即已完全進入物聯網範疇中,在「萬物聯網,萬物皆可駭」概念下,如掛載的車載平台缺乏足夠防禦能量,自駕車將成為攻擊者手中最具威脅性的籌碼,一個指令就可以脅持車輛的煞車與引擎,將會引起嚴重的交通事故。
技術特色
- Frontend Parser:定義Relay IR格式的深度學習運算定義,可以將各種模型格式轉譯成Relay IR統一的表示方式,再從Relay IR開始進行各種編譯優化。
- 支援Pre-Quantization模型與Post-Quantization機制。
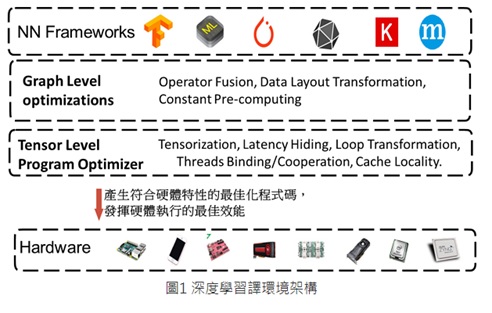
- 支援各種硬體後端的計算圖優化(Computational Graph Optimization)和張量計算優化(Tensor Level Optimization),從深度學習框架模型導入高階數據流程圖,轉化成深度學習編譯器本身的計算圖表示方式(Relay IR),再進行各種編譯優化程序,並產生適合硬體後端計算特性的優化後低階程式碼,不僅能支援CPU、GPU的深度學習編譯,更能支援FPGA、AI晶片等的編譯流程,。
- Runtime模組: 可於各種不同硬體上執行深度學習編譯後模型程式碼。
技術規格
- Frontend Parser: 支援的NN模型格式包括了MxNet、CoreML、Keras、ONNX、Pytorch、Tensorflow、TFLite等,幾乎包括了各種目前主流框架的格式。
- Quantization功能: 支援int4/int8/int16的 Post-Quantization功能與int8的Pre-Quantization模型輸入功能。
- 計算圖優化(Graph Optimization),包含: 運算融合(Operator Fusion)、資料佈局轉換(Data Layout Transformation)、常數運算簡化(Constant-Folding)、運算轉化(Simplify Inference));接著依據晶片特性開發優化編譯技術,進行張量計算優化(Tensor Level Optimization),包含: 迴圈轉換(Loop Transformation)、跨執行緒記憶體複用(Thread Binding、Thread Cooperation、Cache Locality)、張量化(Tensorization)。
- Runtime模組: 支援Bare-Metal硬體、RTOS、Linux、Windows環境的執行。
- 支援多晶片後端之異質執行與平行執行功能。
應用範圍
將NN模型編譯到各種硬體後端:
- CPU
- GPU
- FPGA
- DSP
- AI Accelerator
- 兩種以上IP的AI SoC晶片(例如: CPU+DSP+AI Accelerator)