國立中正大學 資訊工程學系 Yared Abera Ergu 阮文齡
國立陽明交通大學 智慧科學暨綠能學院 黃仁竑
國立陽明交通大學 資訊學院 林盈達
前言
無線網路朝著人工智慧(AI)驅動的解決方案快速發展,吸引許多供應商為開放無線存取網路(Open Radio Access Network, O-RAN)建立智慧功能。 然而,除了更靈活和更智慧化的好處之外,原生人工智慧驅動的 O-RAN 功能的開放性也成為安全威脅的目標,例如對抗性攻擊。 這項研究探討 O-RAN 實體層中人工智慧驅動的解決方案的安全問題,並特別針對基於深度強化學習(Deep Reinforcement Learning, DRL)的資源分配機制進行研究。 我們引入了一種新的對抗性攻擊變體,它可以操縱環境參數並在推理階段誤導代理的觀察。 此攻擊可能會導致錯誤的分配決策和資料傳輸速率顯著下降。 評估結果顯示,此攻擊造成用戶資料和資料封包傳輸率分別降低達 40% 和 77.74%,在超低延遲服務中下降特別明顯。此外,DRL 驅動的無線電資源分配的主要弱點是環境觀察階段,其中一組受損害的使用者或干擾器可以產生欺騙的雜訊和訊號功率來誤導環境互動。 研究發現我們所提出的策略滲透攻擊是導致一般用戶網路效率持續低下或吞吐量(Throughput)降低的最有效方法。
精彩內容
1. B5G/6G產業平台發展及O-RAN的作用
2. 人工智慧驅動的 O-RAN 面對通訊安全的威脅
3. 對 O-RAN 中基於人工智慧的資源分配的對抗性攻擊 |
B5G/6G產業平台發展及O-RAN的作用
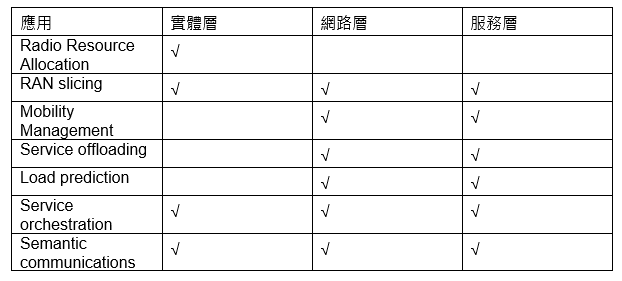
Open-RAN(O-RAN)已成為射頻接入網路(RAN)中最受歡迎的平台之一。O-RAN聯盟包括全球主要的電信營運商和設備供應商,如AT&T、NTT DoCoMo和中華電信。此外,由於其對未來通訊網路應用發展帶來彈性、智慧化和互通性的潛力,O-RAN吸引了通訊產業和研究團隊的注意[1]。O-RAN可以藉由利用大量現成硬體、虛擬化和多供應商環境,降低網路部署和營運的成本。這種新的架構將為小型供應商和新創企業進入市場、推動技術進步並提供多樣化解決方案開啟機會。在人工智慧崛起的同時,許多團隊已開始將人工智慧的強大功能整合到主要的O-RAN功能中(如表1),以實現第六代(6G)蜂巢式網路中自主和自我最佳化網路的願景。
表1 新興的人工智慧應用,以加強 O-RAN 在三個典型層面上的特性
根據[4]的說明,人工智慧(AI)首先將被實施在近即時(Near-RT)的無線電智慧化控制器(xApps)和射頻接入網路服務管理(rApps)中,這是 O-RAN 聯盟工作小組 WG2 和 WG3 的主要任務,如圖1所示。O-RAN中的xApps與rApps是用於增强和自動化網路功能的軟體應用程式,它們運行在O-RAN的非即時(Non-RT RIC)和近即時(Near-RT RIC)智慧化控制器(RAN Intelligent Controller, RIC)上,xApps負責近即時RAN最佳化,而rApps則聚焦於長期網路管理和策略規劃。整合人工智慧至 O-RAN 的背景因素有很多。首先,AI擅長利用從大量數據學習到的知識來監控管理網路運行,特別是 在複雜動態的通訊環境,例如:網路擁擠、需要同時處理多種無線接入技術(Radio Access Technology, RAT)時,AI能夠更好地理解和預測網路行為,以有效地解決這些複雜問題。傳統的方法,例如使用近似演算法或線性規劃來解決網路中出現的問題,往往難以應對因為使用者數量多或請求種類多樣導致的複雜性。其次,在5G/6G等低延遲關鍵應用場景,例如:自動駕駛,這類型超可靠低延遲通訊(uRLLC)中,無線資源分配和流量管理需要快速作出決策。傳統基於數學建模的方法往往需要較長時間求解,而AI憑藉從巨量資料學習到的知識,能夠快速給出近似最佳解,滿足低延遲要求。
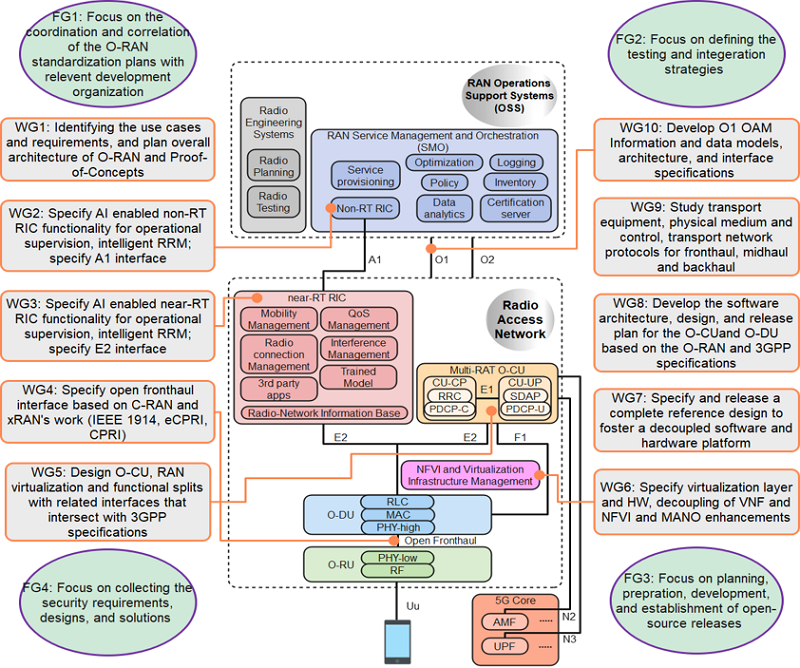
圖1 WG2組和WG3組專注於在智慧型O-RAN中整合人工智慧能力,針對近即時(Near-RT)和非即時(non-RT)的RIC應用[4]。
舉例來說,基地台與眾多高速車輛之間的連接是不確定的,且隨時間變化(例如,受到信號強度和路徑損耗的影響)。運行搜尋/凸函數最佳化(Convex Optimization)演算法以適應環境中所有可能的變化是不切實際且計算量極大的。相比之下,深度強化學習能夠很好地應對這種不確定性,通過與環境的互動,利用獎勵函數和探索-利用(exploration-exploitation)學習策略找到近似最佳解,並在不同目標之間,例如:資源區塊時隙(Resource Block Slots) /數據速率QoS,同時最小化連接損失,取得良好的平衡。
強化人工智慧驅動的 O-RAN 面對通訊安全的威脅
O-RAN AI 提供了許多優勢,如智慧化資源分配和增強用戶體驗。然而,面對AI模型可能遭受的對抗性攻擊以及相關的安全風險,成為了AI系統可靠性中最受關注的重大問題[5][6]。例如,O-RAN 的規範也描述了這種新的威脅[7],即對用於 xApps 和 rApps 推理和控制的 AI/ML 模型的攻擊。在這種攻擊中,對手可以通過操縱上行信號和存儲在 SMO//non-RT RIC 中的最佳狀態觀察,獲得對一個或多個 O-RAN 節點的無限制控制,以生成即時合成數據。這些攻擊可能導致 AI/ML 解決方案輸出不正確的預測或做出不正確的控制決策,從而導致性能降低,甚至更糟的是,網路服務或連接中斷[8]。如果基於 AI 的程序控制網路系統的關鍵部分受到威脅,一旦攻擊成功,可能帶來災難性的損害,導致封包傳輸中斷或允許特定的惡意流量繞過監控。例如,駭客可能進行白箱、灰箱或黑箱攻擊,這取決於他們對機器學習系統的熟悉程度。許多研究[3][4]發現這樣的過程可以被利用來操縱 AI 系統,例如,利用 AI 模型的高線性性質。文獻中描述三種主要針對基於 AI 系統的攻擊[5][6],它們是:(1) 針對插入錯誤標記的數據或更改輸入對象以誤導機器學習演算法的數據污染;(2) 演算法污染影響演算法的分散式學習過程,通過上傳操縱權重到本地學習模型;以及(3) 模型污染,用惡意模型替換已部署的模型。在這三種攻擊類型中,數據污染是一個主要挑戰,因為在大多數室外環境中,輸入對象是可訪問的,攻擊者可以輕易進行複雜的修改。
展示對 O-RAN 中基於人工智慧的資源分配的對抗性攻擊
問題識別
在我們的研究中,我們專注於研究對基於人工智慧的資源分配的對抗攻擊,因為這類攻擊被認為是對AI原生O-RAN能力最嚴重的威脅之一。有幾個理由支持這種說法。首先,來自用戶設備的上行信號模式,這是無線資源分配訓練的來源,可以很容易地被偽造的用戶設備或干擾信號操控。值得注意的是,使用軟體定義無線電裝置可以輕鬆實現偽造用戶設備。其次,資源分配在確保O-RAN網路性能和最佳資源利用方面扮演關鍵角色。對抗攻擊可能操控分配決策,導致資源分配錯誤。這可能干擾網路穩定性,降低整體系統性能,潛在地導致網路擁塞、資源浪費,甚至網路中斷。最後,對抗攻擊引起的資源分配錯誤可能在O-RAN架構的不同層次引起連鎖效應。例如,網路中某一部分的資源分配錯誤可能影響最終用戶體驗,導致對網路品質的不滿或甚至引發整個區域無法正確連接的連鎖效應。本研究選擇業界標準的O-RAN平台和支援AI功能的實作,研究成果將有助於工業技術研究院和本研究團隊增強相關研究動力,足以參與O-RAN訊息安全標準(例如WG11),並進一步影響未來的設計。
研究貢獻
與先前的工作不同,我們的研究聚焦於深度強化學習演算法的政策(Policy)決策滲透,並調整用戶設備的上行信號廣播。目標是創建錯誤的環境(Environment)觀察,以促使基地台上代理(Agent)的分配決策造成混亂。這項研究代表了我們首次嘗試對企業O-RAN平台實體層的對抗攻擊。我們實施了一種對抗性攻擊,以評估基於人工智慧的控制功能的可靠性,並展示模型抵禦細微政策滲透攻擊的能力。本研究對弱點的探討有助於在O-RAN實體層中部署強健且具韌性的AI模型開啟新的研究領域。
執行工作內容
我們將詳細說明系統建模、攻擊模型和我們的解決方案。這項工作考慮了一個具有M個 MIMO基地台(BS)提供服務的N移動單天線用戶設備(User Equipment, UE)的無線通訊環境,具有時間變化的路徑損耗和頻道條件。BS和UE的集合分別表示為 M= {1, 2, ..., m, ..., M}, N= {1, 2, ..., n, ..., N}. 基地台透過O-RAN介面經由E2進行連接,如圖2所示。
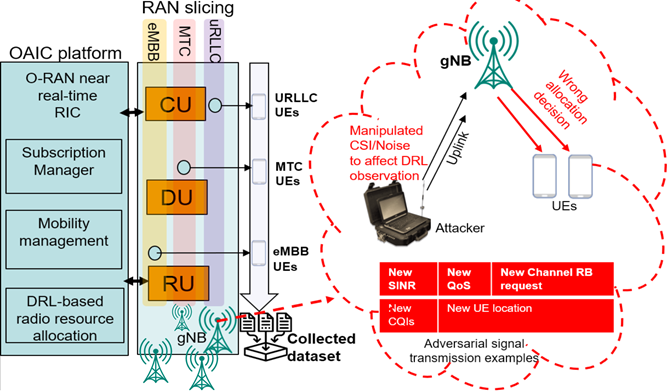
圖2 O-RAN架構和具有對抗攻擊的DRL資源分配,其中攻擊者廣播假的信號請求和雜訊,以污染DRL的狀態空間,影響後續的操作。
攻擊模型
在O-RAN [8] 中,由於時間複雜性,在功能分離選項7.2x(Functional Split Options 7.2x),介面在控制平面上並未加密。這可能導致冒充攻擊和潛在的數據危害。此外,S-Plane容易受到對同步基礎設施的惡意干擾而導致性能下降。在這項工作中,針對預先訓練的基於PPO(Proximal Policy Optimization)的資源分配模型設計了一個基於推論的對抗攻擊代理,該模型在無線網路環境的連續動作空間中使用了一個actor-critic網路。
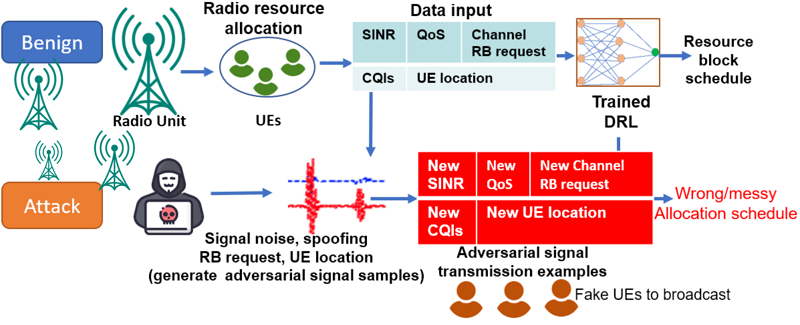
圖3 對O-RAN中基於DRL的資源分配模型的對抗攻擊,攻擊者干擾通道狀態估計並擾亂資源分配決策。
在圖3中,我們以視覺化呈現對O-RAN框架內基於DRL的資源分配模型的對抗攻擊。一個xApp利用DRL根據環境因素為用戶分配無線資源。然而,攻擊者的目標是通過引入假的用戶設備來廣播對抗性信號,故意導致代理生成錯誤/混亂的分配決策而擾亂通道狀態估計。
基地台傳輸一組資源塊組(RBG),這是分配給用戶的最小資源單位,由12個連續的子載波組成。每個基地台都有一組G個RBG,表示為G, G = {1, 2, ..., g, ..., G},狀態空間包含了隨時間t觀察的多個關鍵元素,包括傳輸速率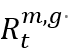 ,傳輸功率
,傳輸功率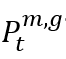 ,相關的通道品質資訊(CQI)幅度CSI數據為
,相關的通道品質資訊(CQI)幅度CSI數據為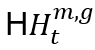 ,緩衝區中排隊數據的長度為
,緩衝區中排隊數據的長度為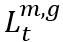 。我們正式定義資源分配問題的狀態為
。我們正式定義資源分配問題的狀態為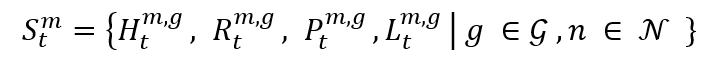 。行動空間,表示為
。行動空間,表示為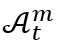 ,包含了在時間t對於BS m,代理人可以採取的可能行動集合。每個行動
,包含了在時間t對於BS m,代理人可以採取的可能行動集合。每個行動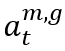 都是代表對資源分配參數進行調整的向量。獎勵是對於每個使用者設備(UE)切片由基地台 m 分配的整體吞吐量的綜合度量。
都是代表對資源分配參數進行調整的向量。獎勵是對於每個使用者設備(UE)切片由基地台 m 分配的整體吞吐量的綜合度量。
1)Fast Gradient Sign Method (FGSM) attacks又稱為Universal Perturbation Attacks
FGSM是一種一步對抗攻擊技術,以更有效的方式最大化損失函數L [17]。在資源分配中,FGSM被設計成擾亂從CSI Hx中提取的RBG,以生成導致更高損失L的對抗性通道矩陣,誤導模型引發不正確的決策。對抗攻擊的目標是通過扭曲狀態空間的操作,損害系統性能,從而影響資源分配的選擇。代理使用切片輸入作為觀察,修改策略設定,並通過錯誤的信號資訊巧妙欺騙代理,以做出不正確決策。
Algorithm 1展示了FGSM演算法的偽代碼。

2)Policy Infiltrator Attack (PIA)
這項技術利用一個熟練的對抗攻擊代理,精心設計以滲透指導用戶設備吞吐量需求和可用資源區塊(RBs)的策略。我們的策略使用難以察覺的隨機雜訊 ϵ 來擾亂狀態空間,有效地利用模型中的弱點,阻礙其實現預期目標的能力。與廣泛使用的FGSM不同,PIA的目標是模仿預先訓練模型的行為。其次,PIA通過逐步調整輸入進行創建,將梯度資訊納入每個步驟,並僅在擾動超過預定閾值時才中斷迴圈。第三,當需要更複雜且持久的攻擊,以及具備突破單步防禦攻擊能力時,這種策略顯得尤為適宜。
Algorithm 2展示了PIA演算法的偽代碼。

3) Projected Gradient Descent (PGD)
此攻擊手法擴展了FGSM的單步策略,突破了在觀察環境和滲透PIA政策中的攻擊方式。這種攻擊類型包括一種強大的多步梯度攻擊,具有小的步長α,控制迭代的改變量,以一種選擇的方式將操縱的輸入投影到原始輸入上。 Algorithm 3展示了PGD演算法的偽代碼,其目標是以有限數量的樣本滲透並模仿預先訓練模型的行為。
Algorithm 3展示了PGD演算法的偽代碼。

發起對抗性攻擊的可能原因
第一種攻擊策略是針對通道狀態資訊(Channel State Information; CSI),透過精心設計的廣播雜訊水準進行操控,同時不對gNB(Next Generation Node B,3GPP 對於5G 基地台的稱呼)或AI模型本身造成損害。因此,實際上這種攻擊有更高的發動機會,並且無需強烈的預設條件。同樣地,第二種攻擊試圖了解DRL模型的運作方式,通過干擾功率傳輸幅度來操控政策。第三種攻擊是為了減少第二次攻擊的滲透時間。表4總結了三種攻擊策略的主要區別和特點。請注意,最後兩種攻擊可以藉由UE執行,這比基地台更容易進行偽裝/破壞(因基地台具有強大的身份驗證演算法)。三種攻擊的共同目的在於識別並影響學習模型的輸出參數,進而控制決策過程,這是通過操縱DRL狀態觀察中的環境要素實現的,而非像許多傳統假設中那樣對整個系統造成損害。這代表了首次在基於DRL的無線資源分配問題上,嘗試發起此類攻擊。
表4 三種攻擊類型支援特徵的比較
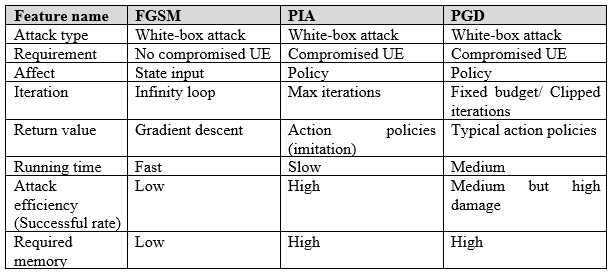
此外,如表4所整理的,所有三種攻擊都可以歸類為白箱攻擊。在這些攻擊中,攻擊者對系統擁有完整存取權,例如對模型的全部資訊,包括模型的梯度、模型參數、超參數和訓練數據集的整個訊息。白箱對手可以被視為最強大的對抗性攻擊,即對手可以適應攻擊並直接製作針對目標模型的對抗樣本。儘管白箱攻擊需要強烈的假設,即我們可以破壞UE,但這種攻擊類型允許我們建構一個強大的對抗性訓練DRL-資源分配模型,可以抵抗任何對抗性攻擊。請注意,若我們的模型能在最強大的攻擊下倖存,那麼對付那些效果較弱的攻擊形式,例如黑箱攻擊,便顯得輕而易舉。在黑箱攻擊中,攻擊者對目標模型的架構、參數或內部運作僅有限制的或根本無法獲得存取權限。
階段性成果
在我們的攻擊測試中,我們採用了一個預先訓練好的模型,該模型在一個擁擠城市區域內,利用先進5G技術以及採自真實世界並參考OpenCelliD的Colosseum O-RAN數據集,對複雜的網路模擬情景進行了評估。該模型在7GB的訓練數據上進行訓練,包括各種性能指標(吞吐量、位元錯誤率)、系統狀態資訊(傳輸佇列大小、SINR)和資源分配策略(切片和調度策略)。這些訓練數據是透過世界上最大的無線網路模擬器Colosseum [18]上進行89小時實驗收集的。在本研究的最佳化過程中,我們採用了基於UE QoS需求的比例公平(Proportionally Fair, PF)、瀑布(Waterfalling, WF)和輪詢(Round-Robin, RR)等調度策略。這些範例模擬了目標網路切片中的多功能調度和自適應資源分配的過程。此方法同時確保了與實際狀況下各個網路切片的獨特特性相匹配的細緻靈活的最佳化。並且DRL代理的實現整合成為xApp,運行在近即時RIC中。本研究使用的Open AI Cellular平台的結構如圖4所示。我們主要進行了基於軟體平台的模擬(利用近即時RIC的應用程式),而UE則是透過基於軟體的UERANSIM外掛來模擬。
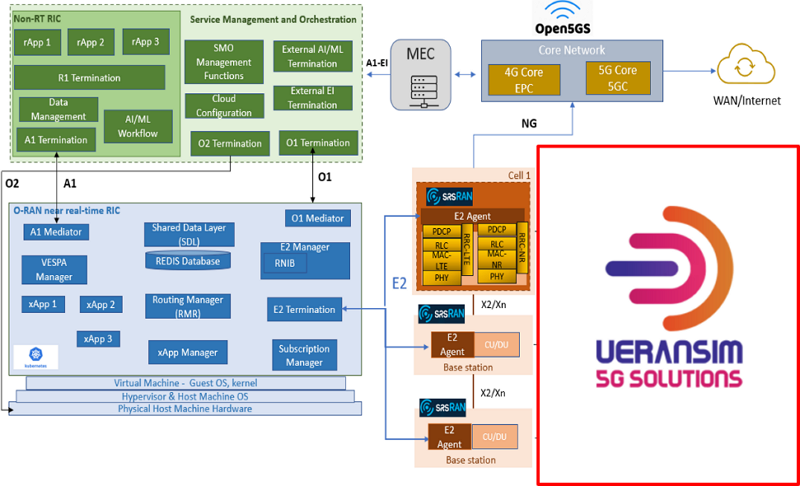
圖4 Open AI Cellular平台的結構
攻擊測試
我們實施了基於梯度的攻擊模型並測試了內建的基於DRL的無線電資源分配。如圖5、圖6和圖7所示,如果AI模型受到攻擊,獎勵累積會隨時間明顯降低。這再次證實了我們的攻擊導致基於DRL的無線電資源分配模型做出許多錯誤決策。獎勵是基於切片中所有UE的總數據速率計算的。請注意,在模擬期間,每個UE的實際吞吐量低於設定值。
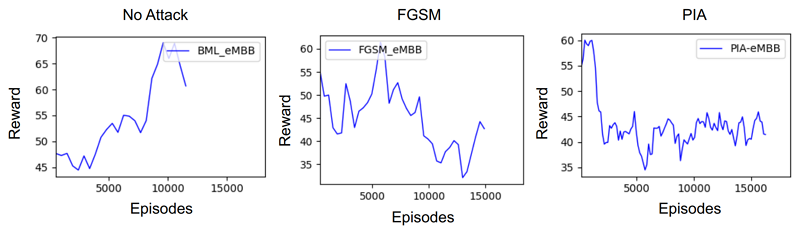
圖5 在eMBB切片上攻擊前和攻擊後的獎勵累積
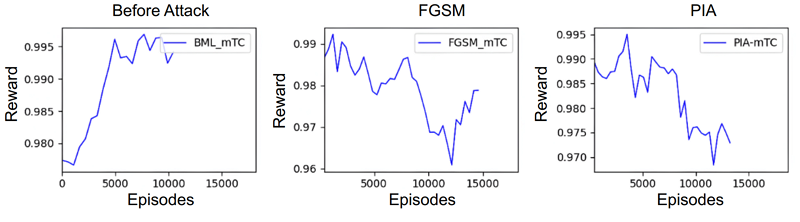
圖6 在MTC切片上攻擊前和攻擊後的獎勵累積
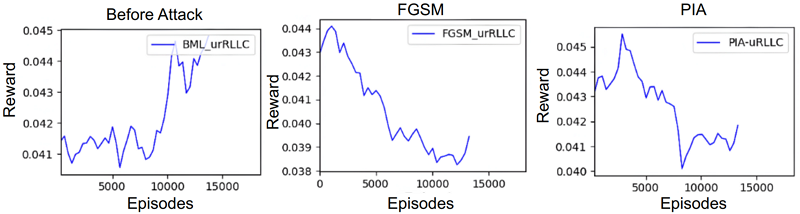
圖7 在uRLLC切片上攻擊前和攻擊後的獎勵累積
為了量化對不同服務的攻擊效能,我們使用切片。我們解析日誌文件數據,提取每個切片的相關指標到列表中,並計算每個UE的平均數據速率。表5中的結果是經過平均化的數值。
表5 對基於DRL的無線電資源分配的對抗攻擊的性能結果
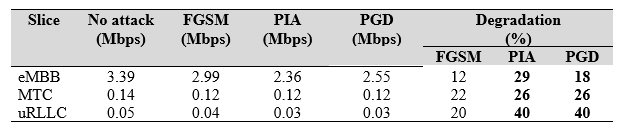
我們觀察到,資源區塊(RBs)在嘗試數次傳送失敗後,無法成功分配給UE,因而導致UE遭受負面影響的嚴重程度,與資源分配未能滿足UE指定的延遲要求成正比。這種關係是由對抗攻擊導致的延遲增加引起的,導致無法滿足資源分配請求。因此,由於超時,資料封包被迫丟棄。這種影響在低延遲服務中特別關鍵,例如uRLLC,在這些服務中,延遲的增加可能導致嚴重後果,例如在高速公路上涉及高速車輛的事故。此外,值得注意的是,與FGSM攻擊相比,PIA攻擊在降低UE數據速率方面表現出更高的效率,如表6所示。這種效率差異可以歸因於PIA對DRL策略的直接影響(有針對性的攻擊),而FGSM需要時間通過DRL觀察影響過程(暴力攻擊)。由於PGD是一種選擇性攻擊,因此成功率低於PIA,這是由於專注於一個政策範圍而不是掃描所有政策所致。
表6 三個測量指標下的攻擊模型性能
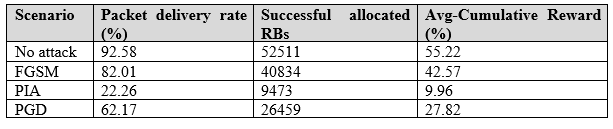
在我們對各種模型場景的性能評估中,我們分析了關鍵指標,如封包送達比率(PDR),它表示成功分配資源區塊(RB)與代理器嘗試總體RB分配的比率。平均累積獎勵(Avg-CR)表示隨時間的推移UE數據速率的滿意度,強調在所有模型生成的獎勵均符合預設最低比特率(bit rate)要求。我們同時檢視每個切片成功分配RB的情況,這是代理器回應請求時所用的一個衡量標準,以每個切片成功分配的RB數量來進行計算。此外,我們透過用戶數據速率評估了對資源分配模型的整體性能影響。表6的評估結果,「無攻擊(No attack)」情境展示了基於DRL的資源分配模型有良好性能,具有高的封包送達比率和成功RBG分配。然而,在攻擊情境下,PIA攻擊導致封包送達比率下降77.74%(即= 100-22.26),顯示了顯著的服務品質下降。成功的PRB分配也下降,導致數據傳輸速率下降40%。PGD導致PDR下降37.83%,並且相對於FGSM攻擊,RBA和Avg-CR大幅下降,影響了效率。值得注意的是,PIA攻擊在效率上證明比FGSM攻擊更有效,但不及PGD,如圖5、6、7所示(顯示三個流量切片下的結果)。
結論
在這項研究中,我們對AI驅動的資源分配進行了對抗性攻擊測試,這是基於AI的O-RAN系統中公認的重要威脅。我們研究了一種對O-RAN平台實體層上基於深度強化學習(DRL)資源分配進行對抗攻擊的方法。透過這些攻擊,我們發現了DRL-based資源分配模型存在的漏洞,顯示其對被損害的用戶設備(UE)在狀態空間中進行的擾動具有高度敏感性。這些發現證實了在部署AI驅動功能之前解決這些問題的必要性。未來可能的一個研究方向是結合常規攻擊(例如,DoS信令)以破壞AI驅動的無線資源分配功能。此外,防禦這些對抗威脅的有效對策將是未來非常重要的研究主題。
致謝
本研究計畫為工業技術研究院資訊與通訊研究所學研合作計畫支持,資通系統與資訊安全組卓傳育組長、楊惠國資深工程師參與本計畫執行管理,並協助中文稿內容調整。
參考文獻
[1] A. Garcia-Saavedra and X. Costa-Pérez, "O-RAN: Disrupting the Virtualized RAN Ecosystem," in IEEE Communications Standards Magazine, vol. 5, no. 4, pp. 96-103, December 2021, doi: 10.1109/MCOMSTD.101.2000014.
[2] L. Bonati, S. D'Oro, M. Polese, S. Basagni and T. Melodia, "Intelligence and Learning in O-RAN for Data-Driven NextG Cellular Networks," in IEEE Communications Magazine, vol. 59, no. 10, pp. 21-27, October 2021, doi: 10.1109/MCOM.101.2001120.
[3] P. H. Masur, J. H. Reed and N. K. Tripathi, "Artificial Intelligence in Open-Radio Access Network," in IEEE Aerospace and Electronic Systems Magazine, vol. 37, no. 9, pp. 6-15, 1 Sept. 2022, doi: 10.1109/MAES.2022.3186966
[4] B. Tang, V. K. Shah, V. Marojevic and J. H. Reed, "AI Testing Framework for Next-G O-RAN Networks: Requirements, Design, and Research Opportunities," in IEEE Wireless Communications, vol. 30, no. 1, pp. 70-77, February 2023, doi: 10.1109/MWC.001.2200213.
[5] V. -L. Nguyen, R. -H. Hwang, P. -C. Lin, A. Vyas and V. -T. Nguyen, "Towards the Age of Intelligent Vehicular Networks for Connected and Autonomous Vehicles in 6G," in IEEE Network, doi: 10.1109/MNET.010.2100509.
[6] V. -L. Nguyen, P. -C. Lin, B. -C. Cheng, R. -H. Hwang and Y. -D. Lin, "Security and Privacy for 6G: A Survey on Prospective Technologies and Challenges," in IEEE Communications Surveys & Tutorials, vol. 23, no. 4, pp. 2384-2428, Fourth quarter 2021, doi: 10.1109/COMST.2021.3108618.
[7] O-RAN Working Group 11, “O-RAN security threat modeling and remediation analysis 4.0,” O-RAN, O-RAN.WG11.O-RAN-Threat-Model-v04.00 Technical Specification, Jul. 2022.
[8] M. Polese, L. Bonati, S. D’Oro, S. Basagni and T. Melodia, "Understanding O-RAN: Architecture, Interfaces, Algorithms, Security, and Research Challenges," in IEEE Communications Surveys & Tutorials, vol. 25, no. 2, pp. 1376-1411, 2023.
[9] Alireza Bahramali et al., “Robust Adversarial Attacks Against DNN-Based Wireless Communication Systems,” Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Nov. 2021.
[10] Meysam Sadeghi and Erik G. Larsson, “Adversarial Attacks on Deep-Learning Based Radio Signal Classification,” IEEE Communications Letters, vol. 119, 2018.
[11] B. R. Manoj, Meysam Sadeghi, Erik G. Larsson, “Downlink Power Allocation in Massive MIMO via Deep Learning: Adversarial Attacks and Training,” IEEE Transactions on Cognitive Communications and Networking, Vol. 8, No. 2, June 2022.
[12] Feng Wang; M. Cenk Gursoy; Senem Velipasalar, “Adversarial Reinforcement Learning in Dynamic Channel Access and Power Control,” 2021 IEEE Wireless Communications and Networking Conference (WCNC).
[13] Rajeev Sahay; Minjun Zhang; David J. Love; Christopher G. Brinton,” Defending Adversarial Attacks on Deep Learning-Based Power Allocation in Massive MIMO Using Denoising Autoencoders,”. IEEE Transactions on Cognitive Communications and Networking, 2023;
[14] K. Sadeghi, A. Banerjee, and S. Gupta, “A system-driven taxonomy of attacks and defenses in adversarial machine learning,” IEEE Transactions on Emerging Topics Computational Intelligence, vol. 4, no. 4, pp. 450–467, Aug. 2020.
[15] K. Ren, T. Zheng, Z. Qin, and X. Liu, “Adversarial attacks and defenses in deep learning,” Engineering, vol. 6, no. 3, pp. 346–360, 2020.
[16] H. Zhang, H. Zhou, and M. Erol-Kantarci, “Team learning-based resource allocation for open radio access network (o-ran),” in ICC 2022 - IEEE International Conference on Communications, 2022, pp. 4938– 4943.
[17] N. N. Sapavath, B. Kim, K. Chowdhury, and V. K. Shah, “Experimental study of adversarial attacks on ML-based xapps in O-RAN,” https://arxiv.org/abs/2309.03844, 2023.
[18] L. Bonati, M. Polese, S. DOro, S. Basagni, and T. Melodia, “Open RAN Gym: AI/ML development, data collection, and testing for O-RAN on pawr platforms,” Computer Networks, vol. 220, p. 109502, 2023.