前言
永續發展議題(Environment, Social, and Governance, ESG)逐年升溫,建構循環經濟體系與資源再利用模式已成為產業關鍵要素。台灣每年大約產生160萬噸的轉爐石、130萬噸的氧化碴等煉鋼副產物,同時耗用1500萬噸的砂石資源於道路瀝青混凝土的鋪面,產生約1200萬噸的瀝青刨除料,這些都不是廢棄物而是重要的資源,但倘若處理不當,即會形成社會與環境的問題,唯有妥善處理物料並轉化為資源,才可降低環境衝擊並轉化環境效益。然而,實現循環物料過程中需面臨複雜物流監控管理,除了傳統資通訊技術,AI技術可強化輔助物料再利用過程中之監控、防弊與驗證。本文將介紹如何把AI視覺辨識技術應用在貨車載運循環物料的驗證過程,結合影像辨識模型開發與模型維運監控機制,透過對物料類型、狀態及周邊場景的即時掌控,持續監測並更新模型,以滿足循環經濟場域驗證與系統永續之應用效益。
精彩內容
1. 循環物料情境與AI問題
2. AI落地應用關鍵:從技術到服務
3. 技術發展藍圖與驗證展示 |
循環物料情境與AI問題
循環物料情境中常見的物料包括:轉爐石、氧化碴、瀝青刨除料等,如同商品會有商品履歷,循環物料同樣需要一套驗證流程與平台,以確保其在運輸過程中不會發生偷竊、混摻有害物料、隨意傾倒等狀況發生,強化物料從產地至目的地的一致性。典型的資通訊技術,如:定位系統、物流系統等,屬於端對端的資訊傳輸,雖能完成及時定位的功能,但面對即時監控物料狀態的需求容易出現監控死角(追蹤貨車位置並無法真實掌握物料情況),而擅長影像辨識的AI技術可用於輔助監控物料類型與狀態,補足應用情境之技術缺口。
本文將介紹之循環物料應用情境與AI解決方案如圖1所示。情境中主角為運送物料的貨車,貨車從物料產源至應用場域(目的地)的過程,會有不同的辨識需求,如:貨車裝載物料類型(需辨識車斗與物料)、貨車卸料行為(需辨識傾倒中的物料)以及貨車所在場域辨識(需辨識場域工人、大型機具等物件);場域建置則是透過事先佈建地磅站及貨車上多個角度的攝影機(如:車斗、舉斗、前後左右),經由網路傳遞影像資料進行後續監控與辨識,這些AI可以協助解決的問題,將輔助追蹤物料在運輸過程中的足跡,防止弊端產生。在應用整合上,場域驗證端可針對不同應用場景透過應用程式介面(Application Programming Interface, API)將各個階段的影片傳輸至雲端平台中的推論伺服器(Inference Server),由部署過各式AI影像辨識模型(如:EfficientNet, AutoEncoder, YOLOv7等)之推論伺服器接收影片並回傳辨識結果。
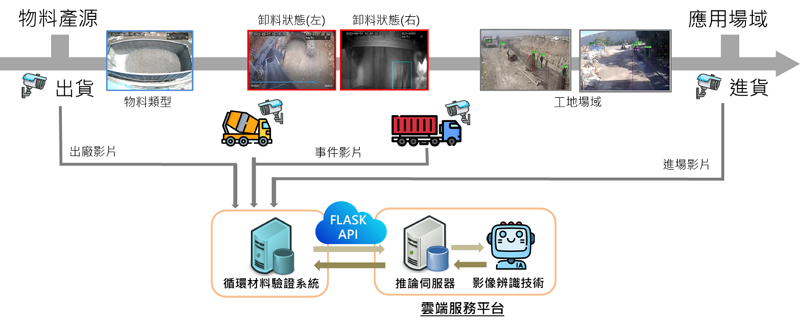
圖1 循環物料應用情境與AI系統架構
AI落地應用關鍵:從技術到服務
在模型技術上主要為遷移式學習(Transfer Learning),遷移式學習能夠將預訓練模型(Pre-Trained Model)應用至特定領域,而本解決方案在AI技術與預訓練模型的選擇上保留彈性,例如:考慮到未來可能部署至邊緣裝置(Edge Device),在運算資源有限的前提下,從眾多預訓練模型中挑選 EifficientNet 輕量化且辨識效能佳的深度學習架構作為影像分類的基礎;選用 DETR 與 YOLOv7 作為物件偵測的核心技術,乃因 DETR 善於偵測影像中的大物件故將其用於監控物料類型與預拌車卸料管之卸料行為,如圖1之卸料狀態(左),而 YOLOv7 相較於 DETR 有著參數量少且辨識效能佳的優勢,故將其用於監控貨車所在之場域,如圖1之工地情境;而圖1卸料狀態(右),由於卸料畫面鑑別度低(例外多、沒有一定形體、畫面占比不確定),難以使用影像偵測與分類技術,本方案結合了影像處理演算法來捕捉卸料狀態機率高的影像,並以自編碼器(AutoEncoder)重建影像特徵編碼,可更準確地篩選出卸料狀態影像。以下將詳細介紹影像辨識相關核心演算法及如何在落地應用時持續精進模型。
影像辨識模型
顧慮到推論伺服器中的硬體資源以及模型架構與辨識情境是否合宜,故選用預訓練模型時會評估模型架構本身的特性如參數量、運算量、辨識能力等面向。AI循環物料情境中採用EifficientNet、 DETR、 YOLOv7 與 AutoEncoder 等架構,以下將說明各項模型架構的特色:
1. EfficientNet
EfficientNet [2] 是Google於2019年提出的卷積神經網路架構(Convolutional Neural Network, CNN),其參考 MobileNet [3] 的架構調整策略與深度可分離卷積(Depthwise separable convolution),使 EfficientNet 的參數量可以大幅減少且保有優秀的辨識能力,如圖2紅色曲線所示,故在上述的地磅站物料辨識的情境中,挑選此模型作為影像分類的模型。(橫軸代表模型參數量,縱軸表示各項模型之 Top-1 準確度;同樣參數量的條件下,EifficientNet 的準確度皆優於其他模型架構)
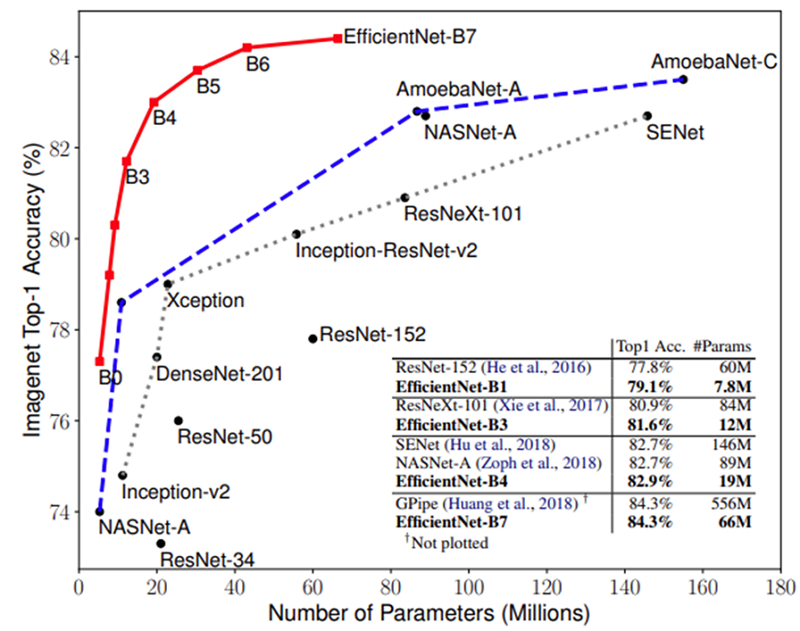
圖2 EifficientNet 與其他模型於 Imagenet 資料集之比較圖 [2]
2. DETR 與 YOLOv7
2020年推出的 DETR [4] 是一種嶄新的物件偵測技術,結合卷積神經網路與轉換器架構(Transformers),如圖3所示。有別於 YOLO 系列的技術,其好處是不需要人工設置後處理的相關參數與閥值,使開發流程中不需要專家的介入進行參數調整。因 DETR 善於偵測大型物件,於圖1物料類型監控與卸料監控,分別偵測車斗與預拌車卸料管之位置。
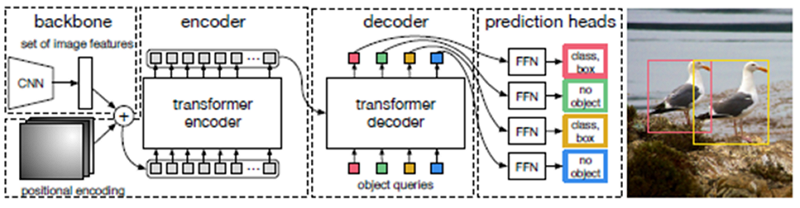
圖3 DETR模型架構圖 [4]
YOLOv7 [5] 於2022年6月問世,憑著多項優化技術如擴展高效層聚合網路(Extended Efficient Layer Aggregation Networks, E-ELAN)、模型縮放(Model Scaling)等,讓其辨識效能領先其他技術如 DETR、YOLO 系列,且與 DETR 相比參數量減少約10%,因工地場域辨識需要偵測四個方位的影片來源如圖4所示,且需要偵測較小的物件如工人,故在工地場域辨識情境中導入 YOLOv7 作為物件偵測的模型架構。
3. AutoEncoder與影像處理演算法
在舉斗卸料辨識的情境中,採用影像處理演算法偵測傾倒中的物料,並使用 AutoEncoder 重建影像能力加以驗證有無卸料行為,此 AutoEncoder 是使用具卸料行為的影像進行訓練,在實際應用當中,若接收到的影像不具卸料行為,則 AutoEncoder 無法順利重建影像,反之則可重建之,利用此項特點結合影像處理演算法輔助監控卸料行為,如圖4所示。
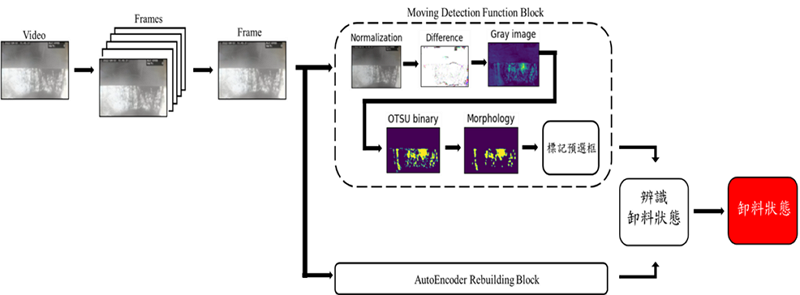
圖4 舉斗卸料辨識流程圖
模型維運:落地應用、持續學習
循環經濟屬於特殊應用場域情境,無法使用開源的資料集建置模型,面臨的問題是資料數量有限,無法微調模型到位,在應用至實際場域初期並非採用大量資料進行遷移式學習的方式,而是改以少量資料且多次微調的策略。如圖5所示,雖初期的模型辨識準確度容易不穩定,但隨著模型服務於實際場域的時間拉長,開發人員逐步累積實際場域資料,搭配持續學習的維運流程使模型辨識效能回復至穩定狀態。
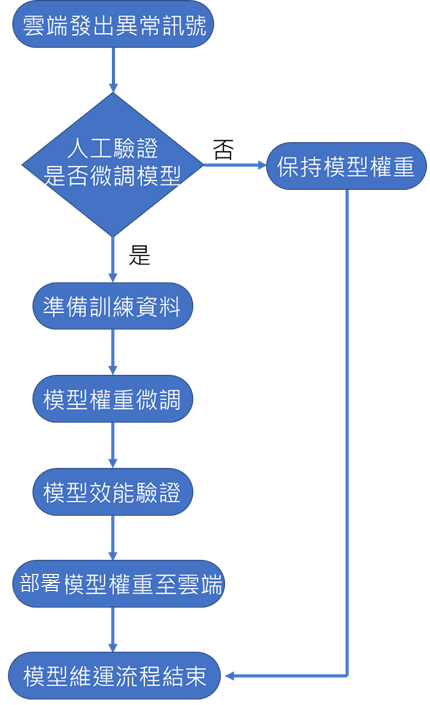
圖5 持續學習維運流程圖
圖6為雲端辨識服務與模型維運流程,透過地端開發人員與雲端維運人員的協作架構,讓模型從初始開發階段、上線維運監控階段乃至於模型持續學習優化階段,皆可依照標準流程進行,即便初始影像資料不足的循環物料辨識情境,亦可逐步實踐AI應用落地。此過程至少涉及到:監控模型辨識效能有無異常(模型效度監控模組)、蒐集實際場域資料用於持續學習流程、部署優化的AI影像辨識模型持續監控。
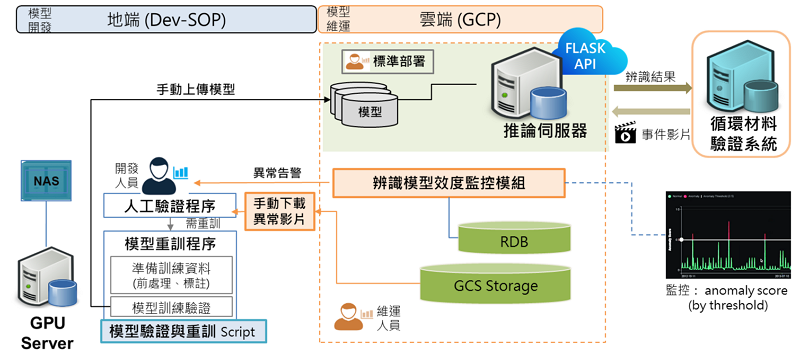
圖6 雲端辨識服務與模型維運流程
技術發展藍圖與驗證展示
工業技術研究院AI團隊,長期投入AI視覺辨識技術於循環經濟領域之研發與落地應用,發展歷程如圖7所示。在技術應用面,從初期的系統建置整合示範驗證(地磅/車機事件之物料類別監控),到中後期的驗證量能擴大,不斷延伸多元辨識場景(物料行為狀態),包括邊緣運算和手持辨識等技術驗證;持續深化AI視覺辨識模型相關量能,以支援場域應用端逐步擴大驗證範圍(工地場域情境辨識),穩定扮演智慧 IoT 防弊監視鏈系統中不可或缺的科技輔助與技術提供角色。相關應用建立在不斷疊加的技術研發上,例如:以 CNN 技術為基礎的物件偵測模型(DETR、YOLO 系列)與影像辨識模型(VGG、EfficientNet)、影像擴增技術、非監督式自編碼器AI模型(Auto Encoder)以及邊緣運算等技術;而用於支撐線上系統服務的技術則包括:雲端技術(虛擬化執行環境)、分散式任務框架、API 驗證以及各種維運監控與模型持續強化等機制。未來將持續深化循環經濟AI應用技術,包括引入自動化建模技術(Automated Machine Learning, AutoML),從資料整備(標註)、訓練參數調整、模型訓練至效能驗證,透過自動與標準化流程來進行,以最佳化演算法取代人工調整參數以及辨識模型的挑選,預期將再次降低影像辨識模型的開發與維運效率。
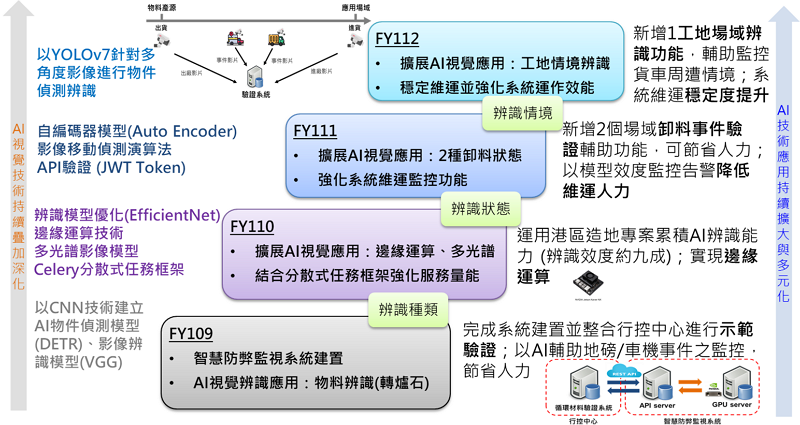
圖7 循環經濟AI視覺應用發展藍圖
以下概述幾個AI於循環物料情境的實例:
地磅站物料辨識
圖1中監控物料類型以道路上的地磅站作為檢查點,透過預先架設的攝影機捕捉影像並辨識車輛貨斗內的物料。此地磅站物料辨識服務採用兩階段的辨識流程,如圖8所示,先透過 DETR 偵測並裁切出影像中的車斗物件,再由 EifficientNet 辨識車斗中的物料為何。設計辨識流程的過程中,考慮到若採用一階段的 DETR 完成車斗偵測與物料分類,隨著物料種類的增加可能會造成辨識效能的下滑,故將辨識流程設計為兩階段,由 DETR 負責偵測車斗位置,而當物料類別有更動時,只需微調 EifficientNet 即可。

圖8 地磅站辨識流程圖
上述技術解決方案已實際落地並持續維運中。圖9左圖則為循環經濟於台灣創新技術博覽會(TAIWAN INNOTECH EXPO, TIE)中,用於模擬地磅站物料辨識情境之驗證模型,結合地磅站場景設計與邊緣運算設備,建置可模擬地磅站場域之實體模型,以驗證辨識流程。結合攝影機、可調色溫LED燈,模擬不同光源條件的辨識情境,由AI監控可即時偵測玩具卡車模擬過磅的過程,並於過磅中擷取影像、辨識物料類型,隨後播放與之辨識結果相符的材料介紹影片,實體展示如圖9右圖。

圖9 TIE展覽參展照(左)與模型實際展示畫面(右)
貨車舉斗卸料辨識
貨車舉斗卸料辨識屬於卸料行為的監控,為預防貨車行駛中私自傾倒或置換物料,於車斗後方裝設攝影機,以即時監控貨車是否有卸料行為。因傾倒中的物料會造成影像中的物料模糊且物料外觀輪廓不固定,若採用深度學習之偵測模型,難以定位出畫面中物料的位置。藉由影像處理演算法如:大津二值化(OTSU Binary)、開運算(Opening Operation)如圖10所示,計算幀數之間差異並使用 AutoEncoder 重建影像的能力加以驗證。(由左至右,由上至下,依序為原始影像、正規化、灰階影像、像素差異、開運算與大津二值化,透過這一系列的前處理流程,過濾掉影像中較為碎小的地方,使模型專注於大面積的區塊。)

圖10 舉斗卸料影像之視覺化
工地場域辨識
除了監控物料類型與卸料行為外,亦監控貨車所處之場域,防止貨車未按照規定駛離預定路線。圖11為工地場域辨識流程,經影像處理後,採用 YOLOv7 偵測四個方位影像中的特定物件如:工人、大型機具等,最終依據偵測結果辨識貨車所處場域為何。因需要快速偵測四個方位的影像,故在挑選物件偵測模型時,採用參數量少於 DETR 且辨識效能較佳的 YOLOv7 作為技術核心。

圖11工地場域辨識流程圖
基於上述應用情境,落地服務的AI輔助驗證解決方案必須要解決以下問題:挑選影像辨識模型,需要從眾多預訓練模型中挑選適宜的模型架構、模型維運,如何讓辨識模型能夠處理實際應用場域的變化如物料類別更新,以及藉由持續學習的流程讓辨識效能穩定。
結論
循環經濟與AI技術皆是當代熱門的議題,本文提出兩者結合的實際落地應用案例,以呈現AI作為輔助科技角色時所需克服的議題,除了不斷疊加的AI技術,實務上的系統架構與永續維運亦為關鍵,如本文案例中結合了雲端技術與持續學習維運流程,讓模型從初始研發到維運過程不斷優化並趨於穩定。此外,未來將朝導入自動化建模(AutoML)方向前進,預期可在技術與維運上進一步強化(節省維運與人力資源),提升AI影像辨識技術於循環經濟場域的落地應用價值。
參考文獻
[1] "從物質流分析到道路鋪面的改革," 台灣循環經濟與創新轉型協會, Jun 2023. [Online]. Available at: https://www.ceita.org.tw/從物質流分析到道路鋪面的改革/.
[2] M. Tan and Q. Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks," in International Conference on Machine Learning, Long Beach, California, USA, 2019.
[3] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, H. Adam and M. Andreetto, "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision," arXiv, Apr 2017.
[4] C. Nicolas, M. Francisco, S. Gabriel, U. Nicolas, K. Alexander and S. Zagoruyko, "End-to-End Object Detection with Transformers," in Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science, 2020.
[5] C.-Y. Wang, A. Bochkovskiy and H.-Y. M. Liao, "YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.