 辨識與合成各種語音單位為人工智慧學習口語交談的基礎。
辨識與合成各種語音單位為人工智慧學習口語交談的基礎。讓機器可像真人一樣用人類語言交談,一直是人工智慧的一個終極目標。因為人類的智慧就是透過語言進行傳遞:從一個人腦中的知識,形成話語傳遞出去,聽到或讀到的人,在自己的腦中以腦神經元的變化建構出新的知識。人類語言的原始形式就是說話—透過語音(voice)進行口耳之間的通訊。研究語音如何透過人類發聲器官來產生、如何藉由空氣介質震動的聲波訊號來傳遞、以及如何藉由耳朵到聽覺神經來接收,這些科學就稱為語音學(phonetics)。任何科學都會針對研究對象進行分析,以求其最基本單位。語音的最基本單位—單位語音、簡稱單音(phone),就是語音學研究標的。不同語言包含不同種類的單音,但語音是用來承載語意的媒介,所以在特定語言中具有分辨語意功能的語音單位,稱為音位或音素(phoneme)。這類從辨義功能來進行語音組合體系與法則的研究稱為音系學或音韻學(phonology)。
音位(phoneme)和單音(phone)的區別與關係很重要。每一種口語都會有一組「具辨義功能的最小語音單位」—即「音位」。音位只是一種根據辨義功能歸納出來的最簡抽象語音單位,其實際上的物理發音單位—即「單音」,可以有多種,稱為同位音(allophone)。例如英語中的雙唇無聲塞音音位/p/,實際上的發音至少有兩種同位單音[pʰ]與[p]1:[pʰ]表送氣音(相當於國語的ㄆ),如pin中的第一個單音;而[p]表不送氣(相當於國語的ㄅ),如spin中的第2個單音。[pʰ]與[p]兩種單音在英語中不具有辨義功能:意即在英語裡面,沒有兩個單字是僅因[pʰ]與[p]的不同發音而成為不同意義的單字。但是,在國語裡面[pʰ]與[p]兩種單音卻具有辨義功能,例如「拼」與「賓」兩個字的發音,只有[pʰ]與[p]的差別,其意義就不同了。所以在國語裡面,[pʰ]與[p]就分屬兩個不同的音位,以注音符號表示為/ㄆ/與/ㄅ/,以漢語拼音表示為/p/與/b/。
當我們想讓機器可以像人一樣用口語交談,最基本的前提就是讓機器能夠像人一樣發出(合成)各種單音、也能分辨(辨識)各種單音。當然要能聽懂說話,絕不是只有分辨語音就足夠,更重要的是整句話語的理解。比如一般人對不懂的外語雖然可能有辦法分辨其單音差別,但還是聽不懂話語內容。不過,所有的話語還是由基本單音組成,而任何語言的音位都是有限且固定的,所以對語音單位的辨識與合成,還是口語辨識與合成技術的基礎。本文的目的就是要探討在臺灣日常生活中最常使用的語言—國語,這個現代標準漢語(Standard Mandarin),其最適於機器學習辨識的語音單位。
1 國際音標IPA (International Phonetic Alphabet)規定以/ /符號表示音位,以[ ]符號表示單音,本文中均遵循此一規範。
精彩內容
1. 國語語音單位
2. 語音單位 - 從機器學習進行分析
|
國語語音單位
每個漢字的發音都對應一個音節(syllable)。一個音節至少包含一個音節核(nucleus),大多為母音、少數情況為響音性子音(如鼻音或流音)。國語音節結構如下表所示:
|
|
國語音節Standard Mandarin Syllable
|
|
傳統漢語音韻學
|
聲母Initial
|
韻母Final
|
|
現代西方語言學
|
音節首Onset
|
音節核Nucleus
|
音節尾Coda
|
|
音位
|
子音Consonant
|
滑音Glide
|
母音Vowel
|
鼻音Nasal
|
傳統漢語音韻學稱母音前的滑音為介音(medial,即國語的ㄧㄨㄩ);國語的音節尾只有鼻聲隨韻母的鼻音/n/和/ŋ/。
國語子音單位
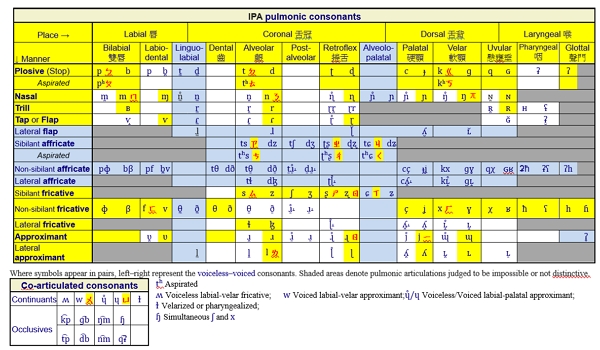
附錄一顯示國語子音在完整IPA子音表中的位置。此表按照發音方式(manner)與發音部位(place)條列。以下將國語子音按發音方式分成三組、每組兩類,分別描述如下。
1.廣義塞音(stop):爆音(plosive)、鼻音(nasal)
|
器官→
|
Labial 唇
|
Coronal 舌冠
|
Dorsal 舌背
|
|
部位→
|
Bilabial雙唇
|
Alveolar齦
|
Velar軟顎
|
|
方式↓
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
|
爆音
|
不送氣
|
ㄅ
|
b
|
p
|
ㄉ
|
d
|
t
|
ㄍ
|
g
|
k
|
|
送氣
|
ㄆ
|
p
|
pʰ
|
ㄊ
|
t
|
tʰ
|
ㄎ
|
k
|
kʰ
|
|
鼻音
|
ㄇ
|
m
|
m
|
ㄋ
|
n
|
n
|
ㄫ
|
ng
|
ŋ
|
註一:表中音位符號分別以ZY(注音)、PY(拼音)、IPA(國際音標)標記,後續各表皆同。
註二:表中「器官」也是發音部位之一,但特指主動(active)發音器官的部份,後續各表皆同。
這一組的發音方式都會將口腔堵塞,故都屬廣義上的塞音。其中爆音(狹義的塞音、故也稱塞爆音)會突然放開堵塞、急速釋放(release)氣流,產生爆裂音效;至於鼻音則是持續堵塞口腔,而讓氣流從鼻腔流出。過程中爆音聲帶不振動屬無聲(unvoiced)子音;鼻音則聲帶振動屬有聲(voiced)子音。此外,爆音又可細分成送氣(aspirated))與不送氣(unaspirated)兩類:送氣音釋放氣流較多較強,因此其後接母音(聲帶振動)的開始時間較晚。最後,根據堵塞部位與器官的不同可分成三群。當中舌背軟顎鼻音/ŋ/,在國語中只出現在鼻聲隨韻母ㄤ與ㄥ的母音之後,故特別以*號標示;但其實在老國音時期(民國21年公布新國音之前),曾經也是聲母之一,並訂有注音符號/ㄫ/。
2.廣義擦音:擦音(fricative)、塞擦音(affricate)
|
器官→
|
Labial 唇
|
Coronal 舌冠
|
Dorsal 舌背
|
|
部位→
|
Labio-dental
唇齒
|
Alveolar
齦
|
Retroflex
捲舌
|
Alveolo-
palatal齦顎
|
Velar
軟顎
|
|
方式↓
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
|
塞擦音
|
不送氣
|
噝聲
|
|
|
|
ㄗ
|
z
|
t͡s
|
ㄓ
|
zh
|
ʈ͡ʂ
|
ㄐ
|
j
|
t͡ɕ
|
|
|
|
|
送氣
|
|
|
|
ㄘ
|
c
|
t͡sʰ
|
ㄔ
|
ch
|
ʈ͡ʂʰ
|
ㄑ
|
q
|
t͡ɕʰ
|
|
|
|
|
擦音
|
噝聲
|
|
|
|
ㄙ
|
s
|
s
|
ㄕ
|
sh
|
ʂ
|
ㄒ
|
x
|
ɕ
|
|
|
|
|
非噝聲
|
ㄈ
|
f
|
f
|
|
|
|
|
|
|
|
|
|
ㄏ
|
h
|
x
|
擦音或稱摩擦音,係由一主動發聲器官緊靠另一發聲部位形成氣流阻礙;但又不像塞音將氣流完全阻塞,仍然讓氣流通過口腔,只是讓氣流受到阻礙而形成摩擦聲響。
塞擦音包含塞音和擦音的雙重發音方式特徵,也可以看成是一種從阻塞開始的特殊擦音:一開始類似爆音氣流被塞住、然後瞬間釋放氣流所形成的摩擦音。與塞音一樣,塞擦音也分成送氣與不送氣兩類:送氣比不送氣的氣流較強而長。但和純擦音相比,塞擦音的氣流長度相對較短;也就是氣流經阻礙器官所產生的摩擦音長度,依序為:擦音>送氣塞擦音>不送氣塞擦音。
擦音與塞擦音都可分成噝聲(sibilant)與非噝聲兩類:噝聲相較於非噝聲有較高的頻率與強度,是由舌冠與齒、齦貼近所造成的一種高頻的噝噝摩擦聲。國語中的塞擦音都是噝聲,三個不同發音部位的塞擦音也都各有一個對應的噝聲擦音,構成三個同部位的噝聲群。當中齦顎(alveolo-palatal)噝聲群ㄐㄑㄒ後面只能接ㄧ或ㄩ兩種介音或母音;而另外兩個噝聲群ㄗㄘㄙ與ㄓㄔㄕ後面只能接ㄧㄩ以外其他的介音或母音。因為ㄧㄩ發音部位接近硬顎(palatal),所以齦顎噝聲群可以視為是齒齦噝聲群ㄗㄘㄙ受到後接硬顎音(ㄧ或ㄩ)的影響,進而產生的一種硬顎化(palatalized)同位音。亦即,國語的單音[ㄐㄑㄒ]也可視為是音位/ㄗㄘㄙ/的同位音,這樣國語子音音位數量就可以再少三個。其實,台語在台羅音標就是如此,亦即只用音位符號/ts tsh s/代表[ㄐㄑㄒ]與[ㄗㄘㄙ]兩群單音。例如台語「煮飯」有漳州、泉州兩種口音:/tsí-pn̄g/、/tsú-pn̄g/;「鼠」也有漳、泉兩種口音:/tshí/、/tshú/。其中/tsi/與/tsu/ 的發音為[ㄐㄧ]與[ㄗㄨ],即同一聲母音位/ts/有[ㄐ]與[ㄗ]兩種同位音;/tshi/與/tshu/的發音為[ㄑㄧ]與[ㄘㄨ],即同一聲母音位/tsh/有[ㄑ]與[ㄘ]兩種同位音。
最後,國語還有兩個非噝聲的擦音/ㄈ/與/ㄏ/,其發音部位與前一組中兩類塞爆音相似。非噝聲相對於噝聲,其波形振幅較小、頻率較低。
3.廣義接近音:接近音(approximant)、邊接近音(lateral approximant)
|
器官→
|
Labial 唇
|
Coronal 舌冠
|
Dorsal 舌背
|
|
部位→
|
Rounded
圓唇
|
Alveolar
齦
|
Retroflex
捲舌
|
Palatal
硬顎
|
Velar
軟顎
|
|
方式↓
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
|
邊音
|
流音
|
|
|
|
ㄌ
|
l
|
l
|
|
|
|
|
|
|
|
|
|
|
接
近
音
|
|
|
|
|
|
|
ㄖ
|
r
|
ɻ
|
|
|
|
|
|
|
|
滑音
|
ㄨ*
|
u*
|
w*
|
|
|
|
|
|
|
ㄧ
|
i
|
j
|
|
|
|
|
ㄩ*
|
ü*
|
ɥ*
|
|
|
|
|
|
|
ㄩ
|
ü
|
ɥ
|
ㄨ
|
u
|
w
|
除了鼻音外,國語所有的有聲子音都在這一組;其聲學特性比較近似於母音,但主動發音器官與被動發音部位之間,相比於母音其距離要更接近,故稱為接近音。其中/ㄌ/在發音時,氣流從舌頭的兩邊流出,故稱為邊接近音,簡稱邊音(lateral)。/ㄖ/是比較特殊的一個子音,傳統語音學將/ㄕ/與/ㄖ/視為一個無聲─有聲對(unoviced-voiced pair),以IPA表示就是/ʂ/與/ʐ/,也就是屬於噝聲擦音。不過觀察/ㄖ/的波形與頻譜並無明顯噝聲的高頻成分,因此在本文中將其與/ㄌ/同列為流音(liquid),也就是氣流在口腔中雖有些阻擋,但仍可順利流動、不至產生擠壓或摩擦的接近音。
除了流音外,還有一類接近音稱為滑音(glide),其特性為:口腔中的氣流只有少許或完全沒有受到阻礙,很像閉(close)母音,故也稱為半母音(semi-vowel);且只會出現在母音前後,發音時很快滑進母音、或從母音滑出,故稱為滑音。在注音符號中將滑音與閉母音合而為一:/ㄧㄨㄩ/既代表滑音/j w ɥ/、也代表閉母音/i u y/。/ㄧ/與/ㄩ/發音時舌頭部位在硬顎、/ㄨ/則在軟顎;但/ㄨ/與/ㄩ/發音時要圓唇,這代表有另一個發音器官在唇部(故於上表中在唇部以*號重複列出這兩個音位)。像這種有多個器官部位同時作用就稱為協同發音(coarticulation)。
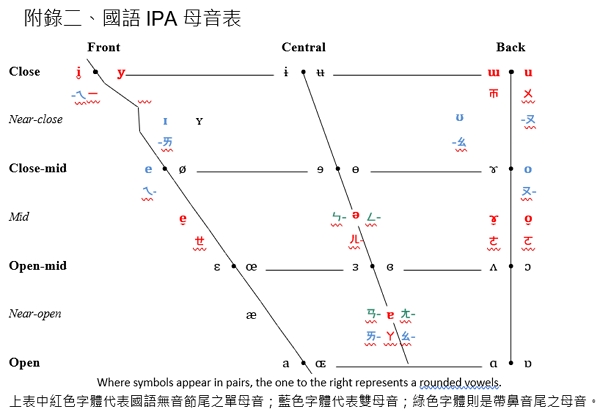
國語母音單位
附錄二是國語母音在完整IPA母音表中的顯示。下圖則是國語韻母總表。
國語韻母表
|
Nucleus
|
No Medial
|
Medial /j/
|
Medial /w/
|
Medial /ɥ/
|
Coda
|
|
vowel
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
ZY
|
PY
|
IPA
|
IPA
|
|
close
|
ㄭ
|
i
|
ɯ
|
|
|
|
|
|
|
|
|
|
|
|
ㄧ
|
i
|
i
|
|
|
|
|
|
|
|
|
|
|
ㄨ
|
u
|
u
|
|
|
|
|
|
|
|
|
|
|
ㄩ
|
ü
|
y
|
|
|
|
|
|
|
|
|
|
|
open
|
ㄚ
|
a
|
ɐ
|
ㄧㄚ
|
ia
|
jɐ
|
ㄨㄚ
|
ua
|
wɐ
|
|
|
|
|
mid
|
ㄛ
|
o
|
o̞
|
ㄧㄛ
|
io
|
jo
|
ㄨㄛ
|
uo
|
wo
|
|
|
|
|
ㄜ
|
e
|
ɤ̞
|
|
|
|
|
|
|
|
|
|
|
ㄝ
|
e
|
e̞
|
ㄧㄝ
|
ie
|
jɛ̝
|
|
|
|
ㄩㄝ
|
üe
|
ɥɛ̝
|
|
ㄦ
|
er
|
ɚ
|
|
|
|
|
|
|
|
|
|
|
open
|
ㄞ
|
ai
|
aɪ̯
|
ㄧㄞ
|
iai
|
jaɪ̯
|
ㄨㄞ
|
uai
|
waɪ̯
|
|
|
|
/i̯/or /j/
|
|
mid
|
ㄟ
|
ei
|
ei̯
|
|
|
|
ㄨㄟ
|
ui
|
wei̯
|
|
|
|
|
open
|
ㄠ
|
ao
|
ɑʊ̯
|
ㄧㄠ
|
iao
|
jɑʊ̯
|
|
|
|
|
|
|
/u̯/or /w/
|
|
mid
|
ㄡ
|
ou
|
ou̯
|
ㄧㄡ
|
iu
|
jou̯
|
|
|
|
|
|
|
|
close
|
ㄧ
ㄣ
|
in
|
in
|
|
|
|
|
|
|
|
|
|
/n/
|
|
ㄨ
ㄣ
|
un
|
un
|
|
|
|
|
|
|
|
|
|
|
ㄩ
ㄣ
|
ün
|
yn
|
|
|
|
|
|
|
|
|
|
|
open
|
ㄢ
|
an
|
an
|
ㄧ
ㄢ
|
ian
|
jɛn
|
ㄨ
ㄢ
|
uan
|
wan
|
ㄩ
ㄢ
|
üan
|
ɥɛn
|
|
mid
|
ㄣ
|
en
|
ən
|
ㄨ
ㄣ
|
un
|
wən
|
|
close
|
ㄧ
ㄥ
|
ing
|
iŋ
|
|
|
|
|
|
|
|
|
|
/ŋ/
|
|
open
|
ㄤ
|
ang
|
ɑŋ
|
ㄧ
ㄤ
|
iang
|
jɑŋ
|
ㄨ
ㄤ
|
uang
|
wɑŋ
|
|
|
|
|
mid
|
ㄥ
|
eng
|
əŋ
|
|
|
|
ㄨ
ㄥ
|
weng
|
wəŋ
woŋ
|
|
|
|
|
-
ㄨ
ㄥ
|
-ong
|
ʊŋ
oŋ
|
ㄩ
ㄥ
|
iong
|
jʊŋ
joŋ
|
|
|
|
- 本表中的IPA欄位採用精細注音(narrow transcription)標記最精確語音發音。
- 本表中以綠色字體代表實際很少用到的韻母。若這些罕用韻母不算,則國語中半開閉(mid)母音音位可以只算一個,其他都可以視為同位音,因為不會出現在相同的前後音中(例如:各種介音後都只有一種母音;無介音後雖有ㄜ與ㄦ兩個,但ㄦ可視為後接一捲舌流音/ɹ/的音節尾)。
- /ㄧㄢ/與/ㄩㄢ/兩個結合韻母,其本來的母音在韻母/ㄢ/中為開母音/a/,但在結合韻母中受閉母音/ㄧ/與/ㄩ/的影響,變成半開(open-mid)母音/ɛ/。
- 雙母音的第二個母音,即非音節母音/i̯ u̯/,與滑音/j w/非常近似。因此也可將雙母音的後半部視為第一個(主要)母音後接的音節尾(coda)。尤其國語的雙母音之後不會再接鼻音,所以這樣可形成一種鼻音或滑音的音節尾分類體系。
- 紅色字體表達/ㄨㄣ/這個韻母的兩種可能發音:一種是[un](後閉母音+鼻音),歸在無介音欄;另一種則是[wən](介音+央母音+鼻音),歸在介音/w/欄下。
- 藍色字體顯示另外有兩種可能發音的韻母群:/ㄨㄥ/與/ㄩㄥ/兩個結合韻母,分別由兩個圓唇閉母音ㄨ與ㄩ後接韻母ㄥ所構成。其中/ㄨㄥ/又分成前有聲母的情形(以/-ㄨㄥ/代表);以及前無聲母的情形(以/ㄨㄥ/代表)。
語音單位 - 從機器學習進行分析
相同音位、不同單音
真正輸入機器的語音物理訊號分類為單音;但從辨義的目的來看,辨識的標的分類為音位。這就產生一個問題:機器應該學習辨識不同單音、還是不同音位?例如同位音就是相同音位存在不同單音,這樣機器應該先辨識出不同單音、再歸納同位音為相同音位;還是機器應該直接學習同位音而辨識出音位來?這個問題牽涉機器學習所需語音訓練數據的標記精細度:單音的標記稱為「精細注音」(narrow transcription)或「語音注音」(phonetic transcription);相對的「音位注音」(phonemic transcription)也稱為「概要注音」(broad transcription)。前面「國語韻母表」中的ZY與PY都是音位概要注音;而IPA則是語音精細注音。其實注音的精細程度是相對的,但是沒有受過語音學訓練的人其實是很難做到很細的精準標記;反之,一般人透過辨義判斷要進行音位注音就比較簡易明確。因此大部分的錄音語料都只有音位注音,故而監督式機器學習就只能直接學習音位分類。
為了處理相同音位具有多種同位音變異的問題,有兩個面向的解決手法:
- 提升語音聲學模型複雜度:同位音之間的聲學變異差距通常不大,所以只要採用的聲學模型複雜度足夠涵蓋這些變異,就能同時代表同一音位的不同單音。傳統GMM (Gaussian Mixture Model)聲學模型就是透過多個高斯分布來代表模化(modelling)不同聲學特徵向量的單音。近年的深度類神經網路則透過多層類神經網路來模化更多樣的輸入變異特徵。
- 提升語音單位分類精細度:相同音位的不同發音變化往往都是跟其前後音有關,因此可依據前後連音(CD: Context-Dependent)來定義更精細的語音單位,以達到區分實際單音變異的目的。例如語音辨識中常用的三連音(triphone)就是根據前後一個音位不同而定義。另外,藉由隱藏式馬可夫模型HMM(Hidden Markov Model)將語音進一步再細分成多段狀態(state)的模型來表達,也等於是將語音單位進行更精細的分類。
相似單音、不同音位
音位是以辨義功能出發所定義的一種「抽象」語音單位體系,所以也存在不同音位的實際發音,其聲學物理特性很接近,在聽覺上幾乎是難以分辨。最明顯的就是子音中的滑音,如國語中的介音/j w ɥ/,聽起來太像閉母音/i u y/了,所以也被稱為半母音。因為在音節的結構中,ㄧ個音節中只能有一個母音音位,而滑音又都緊鄰母音前後。
上圖中為四段詞語:「顧阿義、掛意、故愛、怪」的語音波形與頻譜。以IPA標示,分別為三音節:/ku.a.i/,兩音節:/kwa.i、/ku.aj/,以及單音節:/kwaj/。可以發現除了長短變化外,其聲學特性都很相似。尤其前二者/ku.a.i/、/kwa.i/頻譜相似、後二者/ku.aj/、/kwaj/頻譜相似,皆更為明顯。從此例的觀察中,可以獲得幾個結論:
- 空聲母—可有可無之音節間停頓音:以前語音辨識常會假設傳統音韻學提到的空(零)聲母是一特殊聲母音位。例如第一段/ku.a.i/的後兩個音節都沒有聲母,但有些時候因漢語的音節段落很明顯,故認為在韻母前應該存在類似喉塞音/ʔ/的單音,也就是應該標成/ku. ʔa. ʔi/。但觀察上面實際的波形與頻譜,就可發現在連續語音中並沒有任何塞音的頻譜空白特徵出現,可見所謂的空聲母實際上並不必然存在。至於漢語音節的段落明顯,主要應是藉由音節韻律特徵來產生,而非有空聲母之故。最明顯的韻律特徵就是音節間的停頓,只是這停頓可有可無、可長可短,但至少不像音節內是不容許有任何停頓。所以空聲母可視為當音節間存在停頓時,受前後音影響產生的發聲特性。在機器學習中可設計一停頓音模型,受前後連音不同而有不同特性;與其他音位模型的差異,就是有可能出現在音節間、但又不必然出現,且無法從文字與注音標記中得知,而必須透過語音訊號處理方法如「強制對齊」(forced alignment)來進行自動標記。
- 介音—將母音前滑音視為獨立子音:在注音符號中將介音/j w ɥ/與閉母音/i u y/視為發音相同,給予相同符號/ㄧㄨㄩ/。上例中前二者的/ku.a/與/kwa/,後二者的/ku.aj/與/kwaj/,都是閉母音/u/與介音/w/的對比。從波形與頻譜可看出/ㄨ/在當介音/w/時較短外,與當母音/u/之特性並無差異。漢語音韻學把具有/ㄨ/的韻母(不管是母音還是介音)歸為同一群稱為「合口呼」。介音為傳統漢語音韻學的定義,但以現代語言學的觀點應視之為與母音有別的滑音,應賦予不同音位,這樣才能分出/ku.a/與/kwa/兩種不同語詞的語意。這就是典型相似發音對應不同音位的情況。
- 雙母音—將母音後滑音併入母音:上圖中從頻譜特性來看,後兩者與前兩者的差異比較明顯,其主要的音位差異就是兩個母音分立(hiatus)形成兩個音節/a.i/(阿義、掛意),以及在同一音節中有母音加滑音兩個音位/aj/(愛、怪)的對比;尤其是當後者兩個音位合併成一個雙母音(diphthong)音位/ai̯/更能凸顯這種差異,也就是變成兩個母音音位/a.i/與一個雙母音音位/ai̯/的對比。注音符號就是定義了雙母音音位符號/ㄞ/,而不是以兩個音位/ㄚㄧ/來表示;這就與介音接母音/ㄧㄚ/的情形不同。前面國語韻母表中,也是以一雙母音音位/aɪ̯/來標記/ㄞ/,其中的非音節母音/ɪ̯/採用精細注音表達為近閉(close-mid)母音/ɪ/,比閉母音/i/口腔更開一些。
- 三母音—將母音前後滑音都併入母音:例如可將上圖中最後的「怪」/kwaj/變成/ku̯ai̯/,也就是原本「子母子」三個音位/waj/,變成一個單一母音音位/u̯ai̯/,稱為三母音(triphthong)。若只是將母音前滑音併入母音也會產生更多的雙母音,例如上圖中的/wa/變成/u̯a/即是一例。不過在注音符號系統中,並未將母音前滑音併入母音中。
語音單位的同化與分化
從前述三小節的分析可知,一些相近音的同化或分化有很多種選擇。一種選擇是極端同化—將滑音全部同化為閉母音。以前述範例而言就是變成了/u.a.i/、/ua.i/、/u.ai/、/uai/四種情況,結果其三連音都一樣。這樣的好處是可減少語音單位的種類數量,相對減輕訓練語料不足的問題;但缺點很明顯就是無法區分範例中四種不同音節類別,這對識別語意極為不利。
另外一種選擇是將同一音節內的所有類母音合併成一個母音音位,也就是前述三母音的作法:/u.a.i/、/u̯a.i/、/u.ai̯/、/u̯ai̯/。這樣除了原來/u/、/a/、/i/三個單母音外,又衍生三個多母音音位:/u̯a/、/ai̯/、/u̯ai̯/。這樣的作法跟把整個韻母當成一個單位幾乎無異,只差在音節尾鼻音沒有併入母音中。這個作法的缺點就是新增較多的母音音位類別,但至少能夠區分各種音節。
在能夠分辨各種音節的前提下,另外有兩種折衷的作法。一是分化母音前滑音、合併母音後滑音為雙母音:/u.a.i/、/w a.i/、/u.ai̯/、/w ai̯/,其中/u/與/w/分化。這可以說是目前注音符號的作法。另一種是所有滑音跟閉母音都分化,且前後滑音之間也必須分化:/u.a.i/、/w a.i/、/u.a J/、/w a J/。這裡以大寫/J/來代表母音後的滑音,以分別母音前滑音/j/,如此分化母音前後滑音才能分辨/a.j a/(阿呀)與/a J.a/(愛啊)兩種音節情況。這兩種折衷作法都可不同程度的減少多母音音位種類的數量,但這些各種語音單位體系對於機器學習辨識應用上的優劣,還需要進一步分析並配合實驗才能有最後的評判。
參考文獻:
[1] V. Fromkin, R. Rodman, and N. Hyams, An Introduction to Language (7th Edition), Thomson Heinle, (2003)
[2] 謝國平:語言學槪論,臺北,三民書局(1985)
[3] 楊劍橋:漢語現代音韻學,上海,復旦大學出版社(2012)
[4] https://en.wikipedia.org/wiki/Standard_Chinese_phonology
[5] https://zh.wikipedia.org/wiki/現代標準漢語音系
[6] Lee, Wai-Sum(李蕙心); Zee, Eric(徐雲揚)(2003). "Standard Chinese (Beijing)". Journal of the International Phonetic Association. 33(1): 109–112
[7] CHAO, Y.-R.(趙元任 1968). A Grammar of Spoken Chinese. Berkeley: University of California Press
[8] KARLGREN, B.(高本漢 1915–1926). Etudes sur la phonologie chinoise. (French of “Studies on Chinese phonology”) Leyde: E.-J. Brill
[9] Duanmu, San(2000). The Phonology of Standard Chinese. Oxford: Oxford University Press
[10] Kuo, Chih-Chung (2007).“Phonetic and Phonological Background of Chinese Spoken Languages” in Advances in Chinese Spoken Language Processing, Chapter 2, World Scientific.
[11] IPA Chart https://www.internationalphoneticassociation.org/content/ipa-chart
相關連結: 回178期_智慧零售與照護專輯