工研院資通所 粘為博、陳澤民、張雍昌、陳立函、楊宗賢、徐志偉
 近來各國與各大廠商皆致力於無人駕駛車之開發與研究,目前仍有許多技術待克服。
近來各國與各大廠商皆致力於無人駕駛車之開發與研究,目前仍有許多技術待克服。近年來,智慧型機器人與人工智慧蓬勃發展,帶來許多產業效益,結合智慧型機器人與人工智慧最令人矚目之領域為無人載具技術。無人載具指的是無搭載人員的載具,通常使用遙控、導引或自動駕駛來控制其載具位置及方向。無人載具主要可分為五大類,包含無人地面載具(Unmanned Ground Vehicle, UGV)、無人飛行載具(Unmanned Aerial Vehicle, UAV)、無人海面載具(Unmanned Surface Vehicle, USV)、無人水下載具(Unmanned Undersea Vehicle, UUV)及無人太空載具(Unmanned Spacecraft),而本期內容主要聚焦於無人地面載具,以近來相當火紅的議題─無人駕駛車作為技術探討之主題,介紹無人駕駛車之演進、平台與規範、資訊安全性、無人駕駛車上之感測設備、融合感測設備、自動駕駛物件辨識之深度學習模型、及車聯網V2X技術等方向,期望透過本期內容讓讀者更瞭解其技術內容。
美國國家公路交通安全管理局(National Highway Traffic Safety Administration, NHTSA)於2016年提出無人駕駛車之不同等級分類,此定義根據國際自動機工程師學會(Society of Automotive Engineers, SAE)依照自動化的程度不同編修而成,其定義如下:
- 等級0:此等級非常基本,駕駛者完全控制車輛:方向盤、煞車、油門、動力系統。
- 等級1:駕駛輔助等級;代表大部分的功能仍然由駕駛者操控,但特定的功能(例如方向盤控制及防鎖死煞車系統)可以由汽車自動完成。
- 等級2:在等級2含有多項駕駛輔助系統,駕駛人主要控制車輛,但可以減少操作車輛負擔,例如主動式巡航定速(Adaptive Cruise Control, ACC)結合自動跟車和車道偏離警示(Lane Departure Warning, LDW),而自動緊急煞停系統(Autonomous Emergency Braking, AEB)透過盲點偵測(Blind Spot Detection, BSD)和前方防撞系統(Forward Collision Warning, FCW)的部分技術結合。
- 等級3:等級3為無人駕駛階段的開始,駕駛者仍是必要的,在特定條件下司機 可以不須操作車輛進行自動駕駛,但當汽車偵測到需要駕駛人控制時,會立即回復讓駕駛人接管其後續控制,因此駕駛者需要隨時準備好接管車輛駕駛。
- 等級4:在條件許可下讓車輛完整自駕,駕駛人不須介入操控,此車可以依照設定知道路規則行駛,但是無人駕駛技術可能僅限於高速或者車輛較少的路面上使用。
- 等級5:任何情況下皆可以自動駕駛,不受環境所限定。等級5為完全的自動化駕駛,可執行所有與安全有關之重要功能,包括沒有人在車上時的情形,完全不須受駕駛意志所控,可以自行決策,此等級車子內部需要有方向盤、煞車和油門。
誠如上述,不同等級皆有對應之功能特色,本研究將目前工業技術研究院相關團隊所開發之SAE等級列表如下所示。
表1:ISO 26262 V-model架構
|
SAE等級
|
名稱
|
工業技術研究院團隊
|
|
0
|
無自動駕駛
|
✔
|
|
1
|
弱駕駛輔助
|
✔
|
|
2
|
部分自動駕駛
|
進行中
|
|
3
|
有條件全自動
|
進行中
|
|
4
|
高度自動
|
進行中
|
|
5
|
完全自動
|
進行中
|
無人駕駛能快速發展,大部分是仰賴先進駕駛輔助系統(Advanced Driver Assistance Systems, ADAS)之研發成果,由於各大車廠及相關企業早已投入大量資源發展智慧車輛技術,因此透過先進駕駛輔助系統不但能減少車禍發生,亦能促成無人駕駛產業快速發展。
1. 先進駕駛輔助系統演進
交通事故肇事原因大多數來自變換車道不當、未注意車輛周遭環境狀態與未保持行車安全距離等,然而有高達79.1%的交通事故是有機會事先預防發生的,所謂的先進駕駛輔助系統是指依據所搭載的感測器偵測情況回傳給系統,提醒駕駛者提前反應或者回授予車輛,使其自動做出反應,如煞車或方向盤轉向等,系統將能夠根據當下行車環境或是任何突發事件提出警示或者主動式反應,大幅降低交通事故發生率,確保生命財產安全。
影像偵測辨識技術是目前最為廣泛的應用範疇,近年來亦被廣泛使用在車用安全的應用上,除了一般的車輛與行人等動態物件的偵測辨識外,影像裡的顏色資訊和物件結構的細節,其在道路和交通號誌的偵測應用上,相較於其它感測器所能提供的資訊及分析結果相對準確和重要,目前影像感測器在物件辨識上的表現明顯優於其它主動式的感測器,所以對於物件的追蹤也將優於一般的感測器,即使是像車子進入彎道或是在道路上移動的追蹤,也都可以利用影像視訊來判斷。
但是,電腦視覺所需之計算量高,過去單一模組大部分只提供單一功能,並透過硬體設計或軟硬體共同設計的方法實現系統,隨著車用系統晶片規格不斷大步往前邁進,如車用規格多核心系統晶片Cortex A15或Cortex A57,由於計算處理器技術上的純熟,以及相關元件與資訊取得相對容易,這不僅讓高運算需求的電腦視覺得以純軟體實現,並且大大提升高度整合先進駕駛輔助系統軟體解決方案的可行性,將有機會克服效能問題,相較於硬體解決方案,可以有低成本、高產品組合性、場域高適應性等優勢,因此多功能先進駕駛輔助系統將是未來趨勢之一。
就行車環境感知的功能面來看先進駕駛輔助系統的發展,其從駕駛者監控應用如全周影像行車輔助系統,延伸至主動偵測警告或提示駕駛者相關訊息如車道偏移警示系統、前方碰撞警示系統、盲點偵測系統與停車輔助系統,除了一般的行車條件外,亦會逐步考慮不同的天候與道路型態條件,並且回授於車輛控制系統,如夜視系統與主動式定速巡航系統等。
全周影像行車輔助系統是針對兩個以上的視訊來源,各自偵測首張畫面中的特徵點,利用特徵點配對所得之來源坐標的對應關係進行畫面之坐標轉換,依序接合各個畫面,並針對接合的視訊進行動態接縫計算、畫面接合與修補,即使於來源視訊有不同的曝光與白平衡等條件,接合的影像也不會有明顯的接縫瑕疵,提升全景接合視訊的畫質,產生一個具有廣視角之視訊影像,有效消除車輛行駛周圍死角,讓駕駛人能夠充分掌握車輛行駛周圍路況。
車道偏移警示系統之主要功能,是經由影像處理演算法確認車輛是否正確行駛於道路上,當駕駛者不經意偏離車道時,能適時給予警訊,以利駕駛者適時修正車輛行駛方向,降低車禍發生的機率;前方碰撞警示系統之主要功能,是當與前方之車距小於安全範圍內時,即發出警示訊號提醒駕駛者煞車減速,避免與前方車輛發生碰撞,以提升行車的安全性;盲點偵測系統之主要功能,是協助駕駛者偵測在車輛兩側之駕駛者無法看見之死角,是否有過於靠近或是即將撞上之車輛,在偵測範圍中如車輛過於靠近,即發出警示訊號提醒駕駛者側方有危險來車,以避免事故的發生;停車輔助系統將偵測地面與四周物件狀態,並提供駕駛者相關資訊與協助,應用方式有提供影像與碰撞警示的引導輔助系統;夜視系統將透過影像辨識技術,偵測夜間行車路徑中之障礙物,而回傳的資料將經由動態計算後,若對行車可能造成危險性,則會對駕駛者提出警告;主動式定速巡航系統是透過前方車輛距離的偵測結果,依據車距數據控制煞車與油門調整車速,以利與前車保持適當的距離,防止追撞的情況發生。
先進駕駛輔助系統將不再是高階車款的專利,過往例如Audi、Volvo、BMW等車款,其要價須上百萬元新台幣才可包含以上配備,然而目前Ford Kuga售價最低的車型1.6 Ecoboost,其約88~110萬元新台幣就具備先進駕駛輔助系統的功能,由此可顯示市場已逐步從高階車款跨入中低階車款,從「Global Automotive ADAS Market Forecast 2014~2024 」市場分析報告指出,2014~2024年先進駕駛輔助系統之複合年均成長率達12.8%,然而身為自駕車先導的先進駕駛輔助系統,仍有許多待克服的困難點,如何完全適應於不同的天候與道路型態,深度學習與異質感測器融合技術將是後續研究開發的重點。
2. 無人駕駛車之平台
由於車上安裝的感測器種類繁多、感測器數量不一,可以預期會有大量資料需要計算與分析。要以一個高性能的計算處理器運算相關的感測分析演算法,幾乎是無法達成的工作。以多個高性能計算處理器進行軟硬體整合之後,將相關演算法依照計算流程切割,分散到多個計算節點進行運算,方能負擔多種感測分析演算法運算量之需求。分散式計算架構之發展由來已久,大多用於超級電腦、資料中心等等應用需求。在車用上,尚未有相關技術探討與發展。針對自駕車需求發展車用感測分析計算平台以及相關技術與設計上的探討,自然成為各家競逐的焦點所在。自駕車感測計算平台除了相關硬體整合外,對於整合影像辨識相關之感測分析演算法,提供符合車載安全性以及可靠性規範之車用感測分析計算平台以及相關軟體子系統等等,為一個軟硬體技術挑戰、突破且整合困難度高的系統平台。整個感測分析計算平台可分為二個主題:硬體架構探討與實現、軟硬整合。在硬體架構面向,著重於探討高效率資料分派架構、多工計算任務控管、計算節點架構以及高速資料傳輸介面。在軟體系統整合面向,探討分散式計算環境建構、異質計算工作分派與融合、資料傳輸排程等核心議題。軟硬體的成熟度、安全性、穩定性為建構感測分析計算平台的基礎。針對成熟度、安全性、穩定性等等面向的探討,成為除了構築感測分析計算平台之外,另外一個重要面向。
A. ISO 26262簡介
ISO 26262 Road vehicles - Functional Safety[1]發表於2011年11月,是目前最新進(state-of-the-art)的車用電子功能安全性規範,ISO 26262是基於IEC 61508的母法上,針對車輛電子及電氣系統應用的安全性來訂立,第一版的標準涵蓋3.5頓以下之一般汽車,2018年第二版預計將摩托車涵蓋在內,並且針對半導體應用有更深入的規範。此標準特色如下:
- 提供一個車輛安全生命週期(設計、生產、運轉、維修、退役),並根據電子/電氣系統的發展類別(新開發、衍生、修改、再使用)在各生命週期階段內支持必要的活動
- 提供汽車的具體風險基礎評估,以確定風險等級(車輛安全完整性等級,ASIL)
- 利用車輛安全完整性等級(ASIL)規範具體項目的必要安全設計要求,以達到可接受的安全等級
- 提供所需的確認措施,以確保能夠達成足夠和可以接受的安全程度
 圖1:ISO 26262 V-model架構
圖1:ISO 26262 V-model架構ISO 26262的內容共包含10個部分,可用上圖的V-model來表示:
Part 1:專有名詞定義(Vocabulary):提供ISO 26262標準內所使用之專有名詞定義
Part 2:功能安全管理(Management of functional safety):包含全公司的安全性管理制度,例如:安全文化、人員能力管理、品質管理、與安全性生命週期管理;計劃管理中的安全性計畫、人員配置、計畫調整、與安全性案例
Part 3:概念階段(Concept phase):此階段定義系統的初始架構(項目定義,Item definition),接著透過風險與危害分析(Hazard analysis and risk assessment),求得系統的車輛安全完整性等級(automotive safety integrity level, ASIL),進而推導出車用安全的需求,也就是功能安全性概念(functional safety concept)
Part 4:產品開發:系統層級(Product development: system level):承接Part 3概念階段的分析結果,探討如何使用軟硬體技術,滿足與達成概念階段所推導出的安全性需求,包含技術安全性需求(technical safety requirement)、系統設計、系統整合與測試、功能安全稽查等
Part 5:產品開發:硬體層級(Product development: hardware level):實現Part 4系統設計時,分配(allocate)給硬體的安全性設計,包含硬體設計、硬體架構量化分析、硬體整合與測試
Part 6:產品開發:軟體層級(Product development: hardware level):實現Part 4系統設計時,分配(allocate)給軟體的安全性設計,包含軟體設計、軟體測試涵蓋率分析、軟體信心度判別、軟體整合測試與驗證
Part 7:量產與製造(Production and operation):規範安全性相關元件/項目之製造流程,包含量產安全性計畫、安全手冊、與安全相關的除役程序
Part 8:支援程序(Supporting processes):包含供應商管理、建構式管理、變更管理、文件管理、驗證計畫、軟體認證等
Part 9:安全等級與安全性導向分析(ASIL-oriented and safety-oriented analyses):包含各種安全性分析,如相依性分析、故障樹分析(FTA)、失效模式與影響分析(FMEA)等
Part 10:ISO 26262使用指南(Guideline on ISO 26262):提供ISO 26262之開發案例分析
B. ISO 26262安全生命週期
ISO 26262將主要的安全性活動(safety activities)劃分為三個主要階段,包含概念階段、產品開發階段、與生產運作階段,如下圖所示:
 圖2:ISO 26262生命安全週期
圖2:ISO 26262生命安全週期I. 概念階段:此階段以Part 3為主,包含項目定義(Item definition)、安全生命週期初始化(Initiation of the safety lifecycle)、危害分析與風險評估(Hazard analysis & risk assessment)和功能安全概念(Functional safety concept)。藉由初步的系統架構,定義出基本系統功能,進而分析系統功能失效時,對於人員所造成的可能傷害,分析的過程使用三個參數:嚴重性(severity)、發生機率(Exposure)、與可控性(controllability)做評估,得到系統的車輛安全完整性等級(ASIL)與安全目標(safety goal),藉此定義出安全機制與功能安全的概念,達成安全目標。
II. 產品開發階段:由Part 4系統層級(System level)、Part 5硬體層級(Hardware level)、與Part 6軟體層級(Software level)三個部分構成,透過上階段之架構分析及安全機制定義之後,藉由系統、硬體、軟體的規格定義、實作、與驗證,進行完整的V-model流程。
III. 生產運作階段:以Part 7量產與製造(Production and operation)為主,規範產品量產、製造之規劃,生產前確認相關功能安全需求皆被設計與實行,組裝與製造之需求發展與執行與產品銷售後續服務的流程。
C. ISO 26262軟硬體安全性驗證
為了實現自駕車高可靠度/安全性的運算平台,勢必要在系統的設計中加入安全機制(Safety mechanism)來避免系統失效時造成危害。ISO 26262透過一套有系統的分析方法來驗證安全機制的有效性,統稱為安全性分析(Safety analysis)。當系統的ASIL要求在等級B以上時,就必須透過安全性分析來驗證是否能夠達成預期的ASIL要求。在ISO 26262規範中建議的系統/硬體安全分析方法主要有FMEA(Failure Mode and Effect Analysis)、FTA(Fault Tree Analysis)以及FMEDA(Failure Mode Effect and Diagnostic Analysis)三種。三種分析方法都有其不同的目的,FMEA主要是由下而上(Buttom-up)的方式,有系統的找出各部元件發生錯誤時,對上面的系統會有何影響;而FTA則是由上而下(Top-down)的方式,先列出導致系統失效的原因,再去探究是由哪個元件失效所導致;而FMEDA主要是用來分析不同的安全機制對於各種不同的元件失效模式的有效性做量化分析。FMEDA在ISO 26262的硬體驗證中尤其重要,它的驗算包含單點錯誤評估(Single Point Faults Metric;SPFM)、潛在錯誤評估(Latent Faults Metric;LFM)、與隨機硬體錯誤機率評估(Probabilistic Metric for Random Hardware Failure;PMHF),這三個量化指標,是用來判定硬體安全設計是否能達到ASIL要求的主要依據之一。
ISO-26262標準對軟體的設計與測試驗證,包含從Model Based Software驗證到原始程式碼的靜態分析(Static Analysis)以及動態分析(Dynamic Analysis)來驗證軟體設計的安全性。靜態分析常用MISRA C/C++,用以檢驗程式碼風格是否違背安全設計法則,動態分析包括白箱測試(White box testing)以及Back-to-Back測試,測試的度量標準要求須符合單元測試涵蓋(Coverage)如語句(Statement)、分支(Branch)、MC/DC(Modified Condition/Decision Coverage以及整合測試(Integration test),如功能涵蓋率(Function coverage)、呼叫功能涵蓋率(Call coverage)。
D. ISO 26262軟硬體安全性驗證
自駕車對安全性要求極高,軟硬體必須達到高複雜度的功能整合,這也使得產品的設計、製造、與驗證的工作更加艱難。為了讓整個開發生命週期更可靠,因此得遵循最先進的車用安全性規範-ISO 26262來開發,為自駕車的安全性把關。
3. 無人駕駛車之安全性
著名分析諮詢公司IHS Markit預測至2025年為止,全球自駕車銷售量將會達到60萬輛以上,而2035年將會達到2100萬輛之譜[2],隨著各家大廠積極搶入自駕技術研發,無人車離行駛於道路上僅剩最後一哩路。而當我們持續嘗試移除車輛中的方向盤、油門與煞車等物件時,首先必須確保車輛在自動駕駛時能夠同時保護車內乘客以及道路行人的安全,現階段眾家廠商的研究資源都集中於車輛的行駛安全,對於車用資通訊平台的資訊軟體防護部分尚未成熟,但伴隨著過去以機械為主的汽車導入了更多的電子設備,民眾對於車載平台上資訊安全的要求也將會大幅增加。
曾經與智慧行動終端市場失之交臂的BlackBerry此次並未忽視車載技術的熱潮,於2016年底建置自駕車研究中心並大量投入研究資源,BlackBerry 所擁有的 QNX 平台目前在車用市場中擁有47% 的市占率,且將於2018年推出自駕車用的資安服務平台[3],該平台預期將可遠端掃描檢測車用軟體是否感染病毒或遭受入侵,並且若在行駛當中發現車載平台異常可能危及行車安全時警告駕駛停車,而QNX更是目前少數符合汽車電子系統安全國際標準(ISO-26262)的作業系統,QNX 在資訊安全方面的領先也將成為 BlackBerry 未來重返舞台的關鍵優勢,也同時彰顯了資安防禦技術於車載平台上的重要性。
鑒於目前惡意攻擊的盛行,可想而知擁有龐大未來市場以及配備高運算資源的自駕車輛必然是下一個攻擊目標,車輛上運行的所有電子系統都有可能成為資安攻擊(如圖3所示)的目標或是攻擊媒介,試想近年掀起軒然大波的勒索軟體 (Ransomware)發作於車載平台的畫面,原先大幅肆虐於網路上的攻擊轉移至道路上時只會造成更加嚴峻的災情。
分析諸多車載資安相關之解決方案(如圖4所示),有71%廠商在產品或是技術發想上採用白名單(Whitelisting)類型的技術,採用方式可分為三大類:(1)在ECU上利用原廠設定建置白名單,不符合原廠設定之程序無法於ECU上執行,(2)建置control-flow白名單,程式控制流程異常時則中止操作,(3)透過機器學習認知駕駛習慣,當操作與駕駛習慣差異太大時則產生警示。6%產品強調利用Hypervisor機制隔離車輛中的重要執行區塊,避免惡意程序透過特權提升取得管理者權限。59%廠商在產品上採用軟體解決方案,41%廠商採用硬體方案,裝置額外硬體需透過與車廠的技術整合,技術成本較高。使用軟體安裝方式較為便捷,但若是直接嵌入於ECU上時,容易因為占用ECU資源而造成ECU執行效能受影響的狀況。41%廠商在產品上自行建置或是透過其他資安廠商的雲端服務,任何通訊或是檔案的下載都會在雲端系統先經過檢測,當檔案安全時才會再從雲端下載至車輛,並且雲端系統會不斷更新目前新發現的惡意檔案或是攻擊行為特徵,此方式可保持防禦機制永遠處於最新更新的狀態。
29%廠商在產品或是技術發想上採用機器學習或是人工智能技術,採用方式多利用機器學習方式分析新型攻擊或是惡意程式特徵,進而產生偵測規則置入防禦偵測系統中。24%廠商在產品或是技術發想上採用金鑰技術,透過公開金鑰簽章與身分驗證確認通訊的對象是可信賴的裝置,各端點間傳輸也可透過金鑰加密,確保機敏資料不會外洩以及傳輸的完整性。其中多數公司為以色列新創公司,以色列政府因為軍政地理關係對於資安產業非常重視,持續以國防需求帶動資安產能,近年車載資安廠商的興起可觀察出其政府對於此領域的重視,因此對於政治與環境關係相對類似的台灣而言,發展車用資安防護技術以確保系統運行的安全性將是一個近期需加速發展的議題。
 圖3:車載資通訊平台惡意攻擊類型
圖3:車載資通訊平台惡意攻擊類型 圖4:車載資安廠商解決方案類型統計圖
圖4:車載資安廠商解決方案類型統計圖A. 技術預期效益
目前發展中的新世代產品皆強調高智能與連網能力,但這些條件也等同於為惡意程式布建了執行環境與攻擊缺口,如果被攻擊的產品為一般智能家電,可能只是導致電力耗損或是使用資料洩漏,但是當受攻擊對象為自駕車輛時,將會引起嚴重的交通事故。另一方面,目前現行車載平台多為車用資訊娛樂系統,無法進行V2V (Vehicle-to-Vehicle)通訊,但未來將進入車聯網V2X第三代技術,將進入包含V2V、V2P(Vehicle-to-Pedestrian)、V2I(Vehicle-to-Infrastructure)與V2R(Vehicle-to-Roadside) 等關鍵技術的時代,自駕車輛將在不久的將來完全進入物聯網的範疇中,只要掛載的車載平台缺乏足夠防禦能量,在「萬物聯網,萬物皆可駭」的概念下,一個指令就可以脅持車輛的煞車與引擎[4],自駕車將成為攻擊者手中最具威脅性的籌碼。
為解決此嚴重的安全隱憂,我們提出一資安強化車載執行平台,透過輕量化布建,在不影響原先車載系統運行效能的前提下,針對未經紀錄之可疑程式予以拒絕執行,避免惡意程式控制車輛。基於上述特點,所提出之資安強化車載執行平台預期將可達到:(一)發展國內車載資訊安全核心技術(二)連結自駕上下游廠商發展產業合作(三)搶先布局國內外車規等級資安專利技術。本技術預期將大幅提升產業界在車載系統資訊安全的技術層次與防護能量,發展符合ISO-26262、SAE-J3061與SAE-J2735等車規標準之車載安全執行平台,避免自駕車輛上之重要資訊被竊取甚至系統遭到滲透、入侵或癱瘓,並且將可配合產業界的實際需求,提供多載體的輕量化設計,在資安防護的同時維持原先系統的運算效能。產業合作方面由於政府將資安產業納入國防產業發展的一環,支持產業研發能量投入,且國內車輛相關廠商擁有車載硬體模組生產經驗,將從上游晶片平台導入並擴散至下游系統廠,合作布局車用等級軟硬體技術市場,提供國內廠商未來更寬闊的發展空間。
B. 資安強化車載執行平台:基於白名單過濾之輕量化資安防護系統
此技術將開發一可運行於自駕車之資安防護系統,該系統為達到安全、高效能等特點將植基於兩大主要技術的實現:(一)輕量虛擬化(二)應用程式白名單,利用虛擬化技術來檢查虛擬機內執行的程式是否在白名單當中,而一般認為在虛擬化環境下執行會有一定的效能負擔,因此需要輕量虛擬化的幫助在輕量化虛擬機部分,透過輕量化虛擬機層級之I/O效能提升,在使用虛擬化技術時也提供高效的硬體使用率,目前在ARM環境下已與國內數家廠商討論合作,並在開發平台上進行系統核心與虛擬機層級的實作研究。另外,於應用程式白名單的部分,如圖5所示,主要透過記憶體為基礎的白名單技術進行更嚴格的程序管控,每個記憶體頁面(memory page)要執行的時候都檢查此頁面是否在白名單當中,避免保護名單外的可疑程序在平台內執行,相關技術研究在國際上已有20餘年的歷史,但綜觀相關產品,目前大多無法有效針對所有可執行程式類型進行有效阻擋,而且更需符合車規標準。
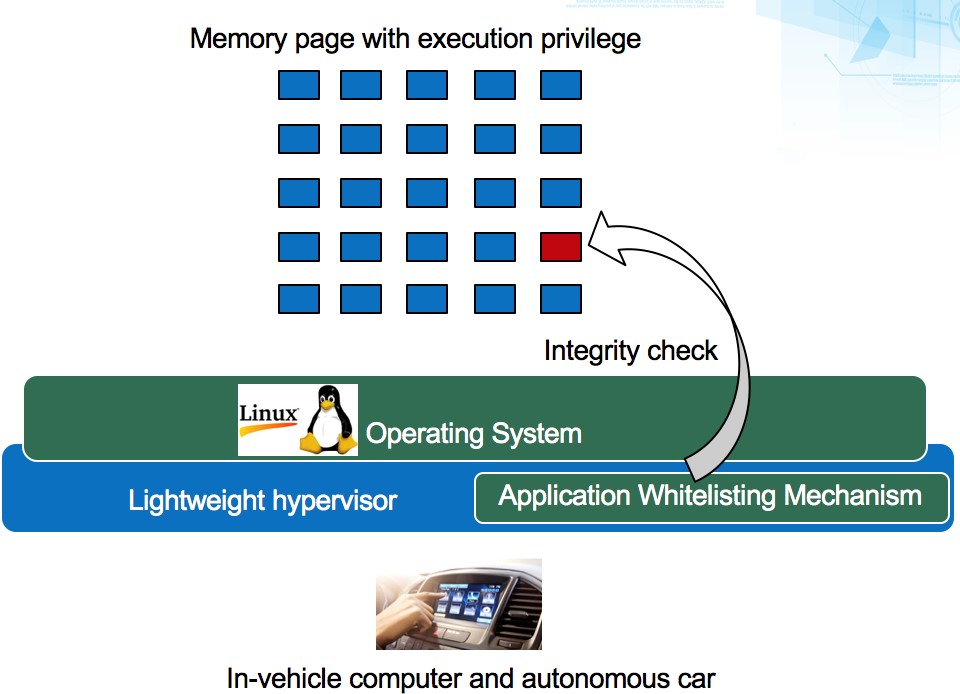 圖5:應用程式白名單程序控管
圖5:應用程式白名單程序控管C. 未來發展
具備資安防禦能力之車載平台是實現自駕技術完全自動化(SAE Level-5)中最為關鍵的防禦核心技術,所提出之車規資安技術在未來自駕車市場逐漸成熟後將可解決自駕車遭受機敏資料竊取、惡意程式入侵等攻擊,也可進一步協助處理車輛失竊等議題。目前全球科技大廠仍處於百家爭鳴、各自研發的階段,於此時投入發展將可與各家車廠站在相同的起跑點上,我國將有機會於未來車載平台資安研究領域位於領先地位。而市場上現階段對於平台的需求多以軟體運算層面為主,目前車用軟體與其運算平台尚處於開發初期,安全方面也相對較重視車輛的行駛安全,對於軟體驗證與平台資安的防護尚未成熟,因此預期將針對車載平台其輕量化、程序驗證、資安防護等演算法與防禦技術提出專利申請,在車規資安防護部分尚未受到普遍重視前,著手研發及布局關鍵專利,未來並將積極與國內車載平台以及Tier-1/2車廠供應鏈廠商共同制定規格,將可於全球車載業界中建置一完整的專利保護網。國內車廠技術品質達國際水準,皆通過歐美地區售服零組件等相關認證,並且擁有完整國際行銷通路,但關鍵技術仍仰賴國外,若透過車載平台專利布局掌握自駕車關鍵技術,將可協助國內車廠在未來居於發展自駕車輛的領先地位。
4. 無人駕駛車之感測器介紹
有鑑於國際自動駕駛發展趨勢與我國資通訊產業優勢及缺口,發展專用感測器技術並建立車規等級之高可靠度環周感知能力為建立自動駕駛技術之首要任務,透過既有的機器學習之技術能量,在有限的偵測資訊內提供自駕車可靠的視野辨識能力。
A. 感測器的重要性
感測器為發展自動駕駛技術領域中最為重要的回授單元,進年來隨著ADAS系統普遍應用於高端車輛上,並且對於安全、舒適、方便與節能有所改善,使得安裝多個感測器已逐漸成為趨勢,同時成為發展自動駕駛等級SAE Level 5的基礎,透過這些先進的感測器與機器學習軟體演算法的處理,可以讓車輛電控單元完整模擬甚至超越人類在駕駛車輛時所使用的各種感官能力(perception),實現同步即時的全方位環周感測能力,並針對感測結果進行控制決策的判斷,因此感測器的穩定性研究成為目前自動駕駛技術的關鍵任務之一,其中在抗環境干擾能力與辨識精準度上為目前發展的兩個重要指標。
B. 先進感測器之介紹
自動駕駛技術所使用的感測器分為本體感知(proprioceptive)與外部感知(exteroceptive)兩大類,本體感知主要偵測與自車有關之資訊,常見的有輪速感測器(wheel encoder)、慣性感測器(inertial measurement unit, IMU)、定位感測器(Global Positioning System, GPS);外部感知主要偵測與車外環境有關之資訊,依據不同偵測範圍需求而使用,用於收集車輛周圍的資訊,常見的有LiDAR、Radar、Camera、Ultrasound,如圖6所示,以下將針對外部感知分別介紹。
![圖 6 各種感測器之應用定位[5]](https://ictjournal.itri.org.tw/files/file_pool/1/0M269419629441130373/Thumbnail%20%2846%29.jpg) 圖 6 各種感測器之應用定位[5]
圖 6 各種感測器之應用定位[5]I. LiDAR(light detection and ranging)
是一種主動式光學感測器,透過雷射光束撞擊至待測點後反射回感測器之光束飛行時間,可計算獲得與待測物之相對距離,並依照連續多個距離資料的多寡可換算為2D或3D之物理座標,雷束光束常見的有紫外光、可見光以及紅外光,其中以波長600-1000nm最為普遍應用,目前市面上較常見的有2D與3D感測器產品,其中3D又依雷射光束的數量普遍分為8、16、32、64 Beam,並同時進行環周360度高頻掃描,為目前自動駕駛常使用的解決方案,如LeddarTech的固態LiDAR、Quanergy與Velodyne的360度掃描Lidar、Bosch的部分空間掃描3D Lidar..等,這些產品目前在感測資訊安全上還需完整的防駭驗證,以避免遭到惡意性的偽造光學攻擊。
II. Radar(radio detection and ranging)
是一種主動式電磁波感測器,透過電磁波撞擊至待測點後反射回感測器之電磁波飛行時間,可計算獲得與待測物之相對距離,並視連續多個距離資料的多寡可換算為2D或3D之物理座標,優勢在於穿透性與抗干擾力強,能在全天候使用,缺點則是檢測解析度低,常見的車用Radar工作頻率在24GHz、77GH、79GHz三種頻率附近。
III. Camera
原理跟構造與人眼非常相似,是一種被動式光源感測器,主要由四種元件所組成:透鏡、光圈、濾鏡、影像感測器,透鏡控制焦距與視角,濾鏡控制通過的光源種類,光圈控制光線進入的程度,影像感測器則負責最後的感光成像,依照不同等級之產品,四種元件會有不同的控制能力,然而成本上也隨響應時間而有所提升,其優點在於具有高解析度,缺點則是受光影與環境影響大。
IV. Ultrasound
是一種主動式聲波感測器,透過聲波撞擊至待測點後反射回感測器之聲波飛行時間,可計算獲得與待測物之相對距離,然而因音波擴散的物理特性導致取樣點較大,解析度較低,常應用於停車輔助系統的三角測量。
針對不同感測需求,如感測器與待測物的距離遠近、相對移動關係,以及待測物種類的分類程度、移動速度、未來軌跡、語意分析(semantic analysis),加上感測時的環境,如雨滴、霧霾、塵埃,需善用不同感測器之優勢來達到自動駕駛的基本需求,若需執行全盤考量的偵測,也可進行多種感測資訊的融合(sensor fusion),達到各種感測器相輔相成之功效,四種感測器在各種偵測需求條件下的優劣比較如表2所示。
表2:各種感測器之優缺點比較
|
|
LiDAR
|
Radar
|
Camera
|
Ultrasound
|
|
物件分類
|
Fair
|
Poor
|
Good
|
Poor
|
|
物件障礙偵測
|
Good
|
Good
|
Fair
|
Good
|
|
物件邊緣偵測
|
Good
|
Poor
|
Good
|
Fair
|
|
最遠距離估測
|
Good
|
Good
|
Fair
|
Poor
|
|
車道線追蹤
|
Poor
|
Poor
|
Good
|
Poor
|
|
可見範圍
|
Good
|
Fair
|
Fair
|
Poor
|
|
惡劣天氣下之偵測能力
|
Fair
|
Good
|
Poor
|
Good
|
|
惡劣光源下之偵測功能
|
Good
|
Good
|
Poor
|
Good
|
C. 感測器之應用案例
I. 自動駕駛車應用
基於各種感測器之優缺點考量,現有常見的自駕車技術[6]會使用Camera與Lidar進行搭配,Camera的高解析度在物件辨識上有很好的辨識度,而在天候環境不佳時則會使用Lidar來進行輔助,如圖7所示。
 圖7:基於Camera與Lidar之fusion感測應用於自動駕駛技術
圖7:基於Camera與Lidar之fusion感測應用於自動駕駛技術II. 路口流量偵測應用
一般常見的市區交通流量感測器使用Radar或是Camera,然而針對高密集度的量測案例,如機車瀑布的數量偵測,因Rada之取樣解析度不足,以演算法進行處理時,容易將密集度高的群體辨識為一體,而Camera雖然可以透過機器學習來達到高準確度的分辨能力,但在惡劣環境下如雨天及光影變化,容易辨識錯誤,而近年來隨著3D Lidar量測技術的成熟,精準度與抗環境干擾已逐漸提升,因此可創新結合路側端設備,解決現有車流偵測產品無法辨識的問題,並傳送辨識結果如交通流量資訊給相關需求者。
自駕車的技術發展關鍵在於整合各類型感測器之優勢,以達到高可靠度的智慧機器全方位視覺。
 圖8:基於Lidar感測技術應用於車流偵測
圖8:基於Lidar感測技術應用於車流偵測 5. 異質感測器融合技術
行車環境感知技術可應用於先進駕駛輔助系統與自動駕駛車等應用,然而如何適應於各種天候與道路型態,如大雨、大雪 、霾害、大霧、路面結冰、逆光、低照度、複雜陰影、人車混流、市區複雜場域與其它相關的移動物件,都考驗著系統設計上的困難度。Google無人車行駛了200萬英里,遭遇了17起不同的事故,而特斯拉Model S在自動駕駛模式下撞上重型卡車,造成不幸損傷,再再顯示行車環境感知技術尚有許多努力的地方,然而近年來異質感測器融合技術,是其中最被關注的解決方法之一,藉由感測融合的結果,物件偵測辨識的感測空間範圍、感測精確度以及感測速度都將會獲得相對提升。
各種感測器皆有其優缺點,聲納可以提供足夠的空間解析度,但是方向性差,極易受到溫度、濕度與風速影響,使得距離產生誤差,而毫米波雷達雖然不易受到氣候影響,且適用於長距離物件偵測,可是對於物件辨識不易。光達感測器具備量測距離長且精準度達公釐等級的特性,但是天候差時,雷射光穿透力變差,進而影響偵測辨識結果,而影像感測器雖然擁有高密度影像畫素資訊,提供最完整的路況資訊,但是影像處理技術需完全模擬人類視覺,極易受到天候與光影等因素影響影像品質,造成偵測辨識的誤判。由此可知採用單一感測元件容易受到自身技術的限制以及外在環境干擾進而影響其偵測辨識能力,因而採用多感測器的複合式系統架構,藉以提高系統正確率與可靠度,將成為未來的趨勢。
舉例來說,目前各車廠之前方碰撞警示系統,如Toyota、Lexus、Ford、Skoda與Volkswagen等,皆已開始採用毫米波雷達與影像感測器或者光達與影像感測器融合系統的解決方案,而Delphi RACam為全球第一個結合24GHz和77GHz毫米波雷達感測器並融合Mobileye影像感測技術的先進駕駛輔助系統,另外,Delphi與Mobile 2019版的「Centralized Sensing Localization and Planning」系統,其感知模組亦會整合Eye Q4/5視覺處理晶片和Delphi的雷達、光達軟體以及雙方合作開發的融合軟體,由此趨勢分析,可預期未來將會整合更多異質感測器如V2X、IMU與GPS等,強化自駕車應用所需之行車環境感知技術。
異質感測器間相輔相成,異質感測器的感測區域不同,透過異質感測器的偵測辨識區域不重疊,如一個向前看的雷達與一個向後看的雷達,各自負責的區域不同,可增加整體感測區域,此為互補式融合技術。另外,各種感測資訊將有助於了解物件的識別以及物件的位置等完整面貌,於系統面還需考慮車輛周遭的路況、當下天候條件、駕駛行為模式與車子動態特性等,藉由兩種以上的感測器重疊辨識範圍,善用各個感測器的特性,將可強化物件偵測辨識結果及物件偵測的完整性,而競爭式融合技術即表示異質感測器的偵測辨識範圍是相同的,透過兩種以上的感測器增加整體系統偵測辨識的準確率與可靠度,或是異質感測器對於感測物件能夠提供相同或不同的物理量描述,如物件距離與類別等,可增加感測物件物理量描述的精確度與完整性。
除互補式融合與競爭式融合技術外,合作式融合技術是目前研究發展重點之一,其代表異質感測器的偵測辨識範圍重疊,且異質感測器對於感測物件能夠提供相同或不同的物理量描述,但是單一感測器若要完成偵測辨識的功能,除了靠自我能夠提供資訊外,尚須參考另一感測器所提供的資訊才能達成,舉例來說毫米波雷達提供感興趣區域予影像處理單元,使得影像處理可以動態設定決策樹,提供更準確的偵測辨識,亦可透過感興趣區域來減少待處理的像素量,進而提升偵測辨識速度,除此之外,若在影像原始資料層級即進行深度融合,即早採用深度資訊,提早移除不必要之雜訊,將可以有效提升後續計算的精確度與速度。
於安全法規嚴格要求的自動駕駛應用中,是需要車輛自動介入操控的,如自動煞車等,因此自駕車之行車環境感知技術需要適應於全天候與全路況,並且保有高準確率與低誤判率,提升系統整體可靠度是勢在必行的,若想要克服使用單一種類感測器所造成的限制,如偵測的範圍、物件重疊與各種行車條件下的精確度,異質感測融合將比使用單一感測器系統更具有優勢與競爭力。
6. 自動駕駛物件辨識之深度學習模型
A. 自動駕駛之挑戰
參考國際深度學習架構介面(如:Tensor Flow、Caffe)設計影像辨識演算法,並輔以影像深度資訊,在不同天氣情況及光影變化下進行道路物件辨識,期以透過深度學習技術進行各式道路物件影像辨識,以提升辨識準確度及辨識速度。辨識模型需要實際道路資料庫,以提升道路物件辨識研究開發成果水準。因此需要收集道路物件及事件訓練資料庫,包含晴天、雨天、起霧及不同光影環境下之道路物件資料。提供影像感知技術開發及國內道路物件感知產業鏈廠商研發使用,期以促進國內影像感知次系統產業廠商研發能量及產品品質升級。
B. 目前深度學習的發展
在此分項中將介紹自動駕駛車物件辨識所需之技術,包含深度學習、捲積類神經網路(Convolution Neural Network)及深度學習之物件辨識(Object Detection)三部分介紹。
I. 深度學習
深度學習為機器學習的其中一項分支,深度學習比傳統類神經網路深度較深,需要仰賴大量資料訓練類神經裡每個參數。其基本的三個步驟如下:
定義一組適合的模型,包含類神經網路結構、權重以及激發函數(Activation Function)算法。
計算目前定義模型的結果,例如與訓練目標比較其優略度(Goodness)程度。
調整網路參數與權重,直到找出最好的一組模型
最後將訓練好的模型與網路參數用在實際推論的場域,即可得出深度學習後的成效。
以手寫數字為例,整個過程在深度學習中是持續學習,也就是定義錯誤含式(Loss Function),透過逆向傳導(Back-Propagation)調整網路參數,找出最小錯誤的一組結果,即為最終可作為推論用的深度學習模型。
- Input Layer:手寫在256x256維度的數字,其中若有墨水,則x值為1;反之為0
- Hidden Layer:很多層次的類神經網路會根據有無墨水的數值,透過激發函數計算出一個數值
- Output Layer:根據前面計算的數值結果分出10個數字的辨識機率,最後取其最高者即是輸出結果
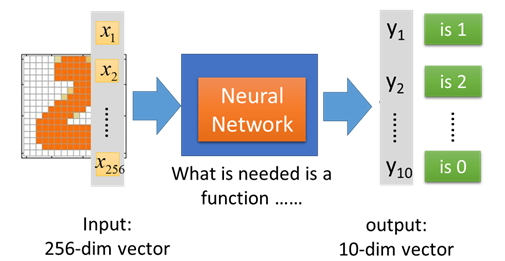 圖9 深度學習模型流程圖.
圖9 深度學習模型流程圖.II. 捲積類神經網路
捲積類神經網路(Convolution Neural Network, CNN)為深度學習在影像辨識的應用上,常利用捲積類神經網路作為深度學習的基本模型,而捲積類神經網路與一般全連接網路(Fully Connection)之差異,在於經過運算後之每個資訊是否影響到下一層的每個位置,若是影響到部分區域,則為捲積類神經網路;若影響到下一層的每個位置,則為一般全連接網路,如下圖所示。
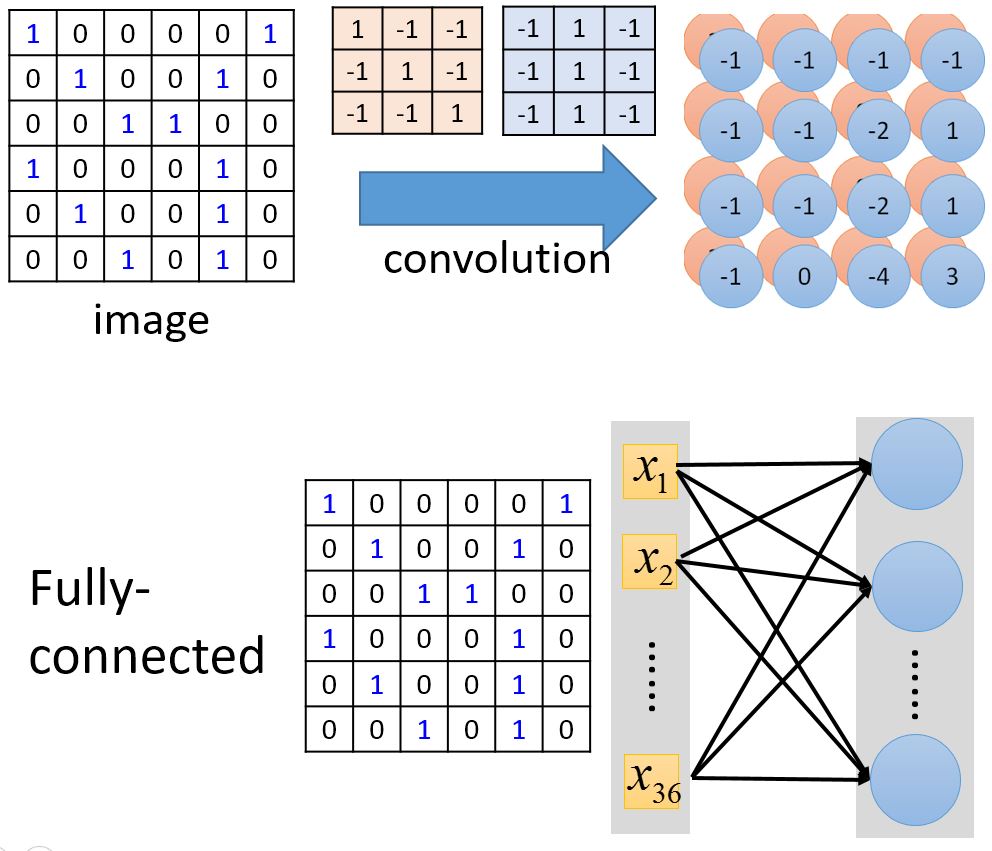 圖10:上方為捲積類神經網路網路;下方為全連接網路
圖10:上方為捲積類神經網路網路;下方為全連接網路全連接網路在影像處理上是將每一個輸入都對應到後續的每一個神經元,所以每個神經元可參考到前一層的所有計算結果;捲積類神經網路表示會透過一些過濾器(Filter),如圖中的3x3有色方形,過濾出一些只想要找到的特徵,藉此算出一些特色圖(feature maps)如圖中的4x4有色方形。
顯而易見的是,透過捲積的過濾可大幅減少深度學習的運算量;而藉由全連接網路可得到全部的資訊。這兩種連接方式各有其特色,而通常文獻當中也都會搭配使用,例如先透過捲積類神經網路擷取影像特徵,最後幾層再利用全連接網路進行整合與推論結果。
III. 深度學習之物件辨識
深度學習之物件辨識(Object Detection)主要可分為圖像與影像兩大派系,前者的技術看似已發展得很成熟,後者則是近一兩年來的火熱話題。目前圖像基礎的物件辨識方法,主要佼佼者有Faster R-CNN以及YOLO,YOLO在2016年的CVPR發表會上直接拿出效能比較圖,如下:
 圖11:物件辨識演算法比較
圖11:物件辨識演算法比較由上圖可看出YOLO很適合即時性的應用場景,但準確率仍有待提升,而這也正是目前面臨的一個取捨,這張圖比較的只是YOLO第一代,YOLO第二代已經推出,宣稱速度與準確率都提升了。YOLO具有快速即時性、高準確率,適合用在自動駕駛應用中之物件影像辨識,因此期盼自動駕駛物件辨識透過YOLO為基底之物件辨識演算法之精進。
C. 深度學習模型應用於自動駕駛可能之方法
物件之即時視訊分析引擎,透過發展一深度神經網路模型,整合YOLOv2等深度學習影像辨識技術建立深度學習模型,開發之系統應於不同天氣環境下偵測物件,且須透過場域實際驗證其正確性,能提供辨識結果予自動駕駛車之決策應用。為了提升系統效能及提升辨識率深度神經網路模型,將發展物件切割與物件追蹤技術,物件切割技術為條件導向及基礎影像處理技術,能快速切割可能含有偵測物體之大範圍影像,以增加效能。
I. T-CNN
T-CNN(Tubelets Convolution Neural Network)[7]為物件辨識中採取後處理(post-processing)的技術,如下圖的T-CNN,其概念主要是在傳統圖像基礎方法做完後,在經過一些後處理的技巧進行優化。而T-CNN的優化技巧主要有二:其一是基於時間(Temporal)資訊減少動態模糊影像(Motion Blur)的潛在問題;其二是基於情境資訊(Contexture)傳遞已知的內容,減少誤判的情況發生。
 圖12:T-CNN架構圖
圖12:T-CNN架構圖透過T-CNN的架構可將YOLO作為靜態圖像辨識(Still-image Detection)區塊之演算法,對於即時性應用有較好的偵測速度,但其準確度仍有待提升。透過此T-CNN之架構概念能進一步改良YOLO機制,期盼能同時兼顧速度與準確度之演算法架構。
一般來說,物件辨識主要可分為圖像與影像兩大派系,傳統作法大多採用圖像基礎概念來達到物件偵測的目的,然而在影像基礎之辨識上會面臨到一些挑戰,如下圖所示。
 圖13:影像基礎之辨識遭遇之問題
圖13:影像基礎之辨識遭遇之問題其一是因為不同時間軸上所偵測到的信心程度(Temporal Fluctuation)會有所不同,如圖片上方代表不同時間影格(Time Frame)的信心程度高低指數。這種情況可能也會發生在模糊圖像(Motion Blur)的時候,因為影像中的每張影格不見得都很清晰;其二是物件誤判(False Positive)的情況,如圖片下方代表前幾張影格有偵測到一隻烏龜,然後到後面幾張影格則不認為那是烏龜,因此造成誤判的情況。 因此,倘若能根據前後影格的資訊,一定區間內的影像影格即可能提升物件偵測的信心程度,甚至節省不必要的重覆運算,藉此提升偵測速度與辨識度。 II. YOLO YOLO(You Look Only Once)[8, 9]為端到端(end to end)之影像辨識演算法,將圖片輸入至模型中即可算出物件的位置及類別。YOLO擁有良好的運算速度及辨識率,透過深度學習之回歸方法預測出影像中物件之位置及目標類別,是目前學術界相當受人矚目之模型。
 圖14 YOLO之辨識流程圖
圖14 YOLO之辨識流程圖上圖為YOLO針對圖像辨識之流程圖:
- 給模型一個圖像當作輸入,並將圖像畫分成7x7的網格(cell)。
- 對於每個網格,類神經系統會預測兩個邊框(Bounding box),每個邊框包含目標的信心度及各種類別的機率。
- 根據預測出的7x7x2個邊框,根據不同的閥值(Threshold)去除可能性較低的目標邊框,最後以NMS (Non Maximum Suppression)方法去除重複的邊框。
YOLO之運算步驟相當容易,不需要產生中介之邊框,即可完成辨識物件的位置及其類別。
 圖15 YOLO的模型網路架構圖
圖15 YOLO的模型網路架構圖上圖為YOLO的模型網路架構圖,前面網路架構與GoogLeNet的模型比較類似,主要是後面兩層的結構不同,捲積層之後接了4096維的全連接層,再透過一個7x7x30維的張量。所區分之7x7的網格中預測兩個不同的目標物件位置之信心度及類別,代表每個網格預測兩個目標,每個目標的資訊有四個訊息(物件之中心點座標、物件之長度、物件之寬度),一個是目標的信心度,還有類別數目20類。總共為(4 + 1) x 2 + 20 = 30維度的向量。這樣可以利用前一層4096維的全圖特徵直接在每個網格上回歸產生出目標之位置及其類別。
YOLO的錯誤函數(loss function)計算公式如下,主要分為三部分:目標座標、有無物件、類別種類。
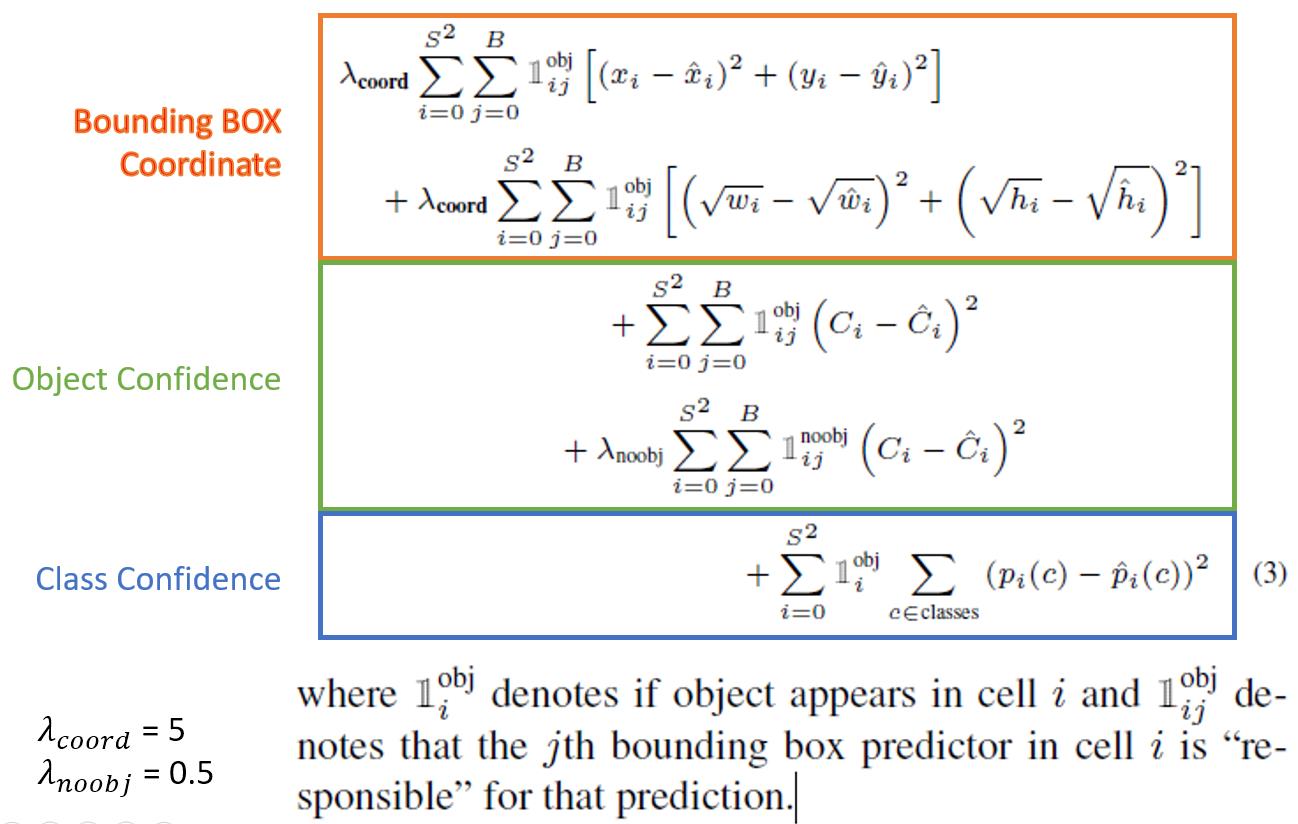 圖16 YOLO之錯誤函數公式
圖16 YOLO之錯誤函數公式其中藉由λ給予不同的權重值,但如何給權重就是一個問題,目前可看出此錯誤函數希望多訓練一些物件的精確位置;此外,第一版的非物件設為0.5,主要是避免大多數的非物件影響整體的錯誤加總值;然而第二版卻變為1,這使得物件與非物件相等;總的來說,從計算方式來看,若將類別拆分出去計算,或許就會有另類的訓練模型方式,甚至推論出更快的解法。
D. 未來深度類神經網路模型應用於自動駕駛
未來深度類神經網路模型,能透過T-CNN架構及YOLOv2影像辨識技術建立深度學習模型,初期能使用開放資料集訓練模型以辨識基礎物件。透過條件導向及基礎影像處理技術建立物件切割技術,能快速切割可能含有偵測物體之大範圍影像,以增加效能。
於整體架構圖中,進行多感測器結合深度資訊協同即時視訊分析之車道線辨識以提升可行走區域、車道線之辨識率;提供自駕車路徑規劃所需可行走區域及車道維持駕駛之必要資訊;並協助即時定位圖資提升區域路段定位速度之提升,以產出如上之特定區域偵測項目,且於透過第一階段、第二階段與第三階段之物件辨識,提供捲積類神經網路必要之物件分群位置資訊,透過此二技術整合進一步增強物件之即時視訊分析效率,期盼透過深度學習網路模型能讓自動駕駛的物件辨識更為準確,且擁有好的效能以利決策部分有充足的時間控制車輛。
7. 車聯網V2X技術
車聯網V2X技術則是應用車間、車路與基礎建設資料傳輸,提升行車安全自動化的解決方案。V2X關鍵技術為串聯人、車、路與平台,強化行車安全,透過WAVE/DSRC(Wireless Access in the Vehicular Environment/Dedicated Short Range Communications)短距無線通訊技術,達到兩輛車相距100公尺範圍內,單向傳輸延遲維持在0.002秒內,WAVE/DSRC亦是目前唯一滿足主動式安全應用低延遲需求之技術。回顧車聯網V2X技術發展演進,第一代為獨立運作之系統,如娛樂、獨立導航系統,缺乏或僅有少部分無線通訊功能;第二代透過手機向駕駛傳遞應用服務,以GPS(Global Positioning System)為基礎提供駕駛行車安全及vehicle centric support應用服務,如GM OnStar、KDDI G-Book;第三代其關鍵技術為V2X整合V2V (Vehicle-to-Vehicle)、V2R (Vehicle-to-Roadside)、V2I (Vehicle-to-Infrastructure)與V2P (Vehicle-to-Pedestrian),提供自駕車行車安全、便捷與舒適,可運用無線寬頻多樣性應用服務,達到自駕車聯網的功能,未來自駕車只要能裝備具WAVE/DSRC通訊之OBU(On-board Unit)車機,將可大幅提升自駕車的安全性。
◎參考文獻
[1] International Organization for Standardization, “ISO 26262 road vehicles – functional safety part 1-10,” November 2011.
[2] https://www.ihs.com/country-industry-forecasting.html?ID=10659115737
[3] http://fortune.com/2016/12/19/blackberry-autonomous-vehicle-research-center/
[4] http://blog.trendmicro.com/is-your-car-connected-or-protected/
[5] Beyond The Headlights: ADAS and Autonomous Sensing September 2016
[6] 3D Object Tracking using RGB and LIDAR Data, 2016
[7] Kang, K., Li, H., Yan, J., Zeng, X., Yang, B., Xiao, T., & Ouyang, W. (2016). T-cnn: Tubelets with convolutional neural networks for object detection from videos. arXiv preprint arXiv:1604.02532.
[8] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 779-788).
[9] Redmon, J., & Farhadi, A. (2016). YOLO9000: better, faster, stronger. arXiv preprint arXiv:1612.08242.
相關連結: 171期 無人載具技術專輯