工業技術研究院 資訊與通訊研究所 林炳立 許振嘉 宋哲偉
3D空間稀疏建模與6DoF視覺定位技術是增強(AR)、混合(MR)和虛擬(VR)實境等應用,以及室內自走機器人技術或自動駕駛汽車的關鍵應用技術[1]。影像式3D空間稀疏點雲建模技術是指藉由收集從不同攝影機、不同方位(方向、位置)的有序或無序參考影像中,藉由影像特徵點提取其特徵點位置及描述符(descriptor)、特徵匹配(feature matching)程序,通過解決n點透視法(Perspective-n-Point, PnP) 問題來評估生成的 2D-3D 匹配的幾何一致性,計算出影像對間匹配特徵點對應空間場景點3D空間座標(2D to 3D mapping),並逐步擴建成3D空間的稀疏點雲模型。視覺定位技術主要用於準確估算攝影機6DoF的位置及姿態資訊,同時從該位置及姿態資訊中進一步獲取給定影像相對於參考場景座標。近期以來,3D空間稀疏建模與視覺定位相關技術發展如火如荼進行著,例如,CVPR 2019 - winner of the visual localization challenge及ECCV 2020 Workshop on Long-Term Visual Localization under Changing Conditions[2]。
為了評估相關3D空間建模與視覺定位技術對長時間場景應用的效能,網路上提供許多開源基準數據集,基準數據集包含多樣性環境資料參考樣本,如包含季節性(夏季、冬季、春季等)和不同光照(黎明、白天、日落、夜)條件的情境內容[2]。每個開源基準數據集皆由一組參考影像樣本集及其對應的真實拍攝位姿和一組查詢影像組成。這些開源數據集本身就帶有3D稀疏點雲參考模型,可提供查詢影像推算其6DoF姿態。為確保視覺定位方法比較結果的公平性,查詢影像的真實參考姿勢被官方保留,並提供研究團隊上傳定位模型的評估服務,衡量姿勢準確性。
基於影像的3D空間稀疏點雲建模管道(pipeline),包含(一)對應搜索:執行對所有數據庫參考影像和查詢影像的特徵點偵測、特徵點匹配及對應幾何驗證。(二)使用增量運動重建結構技術(Incremental Structure-from-Motion, Incremental SfM)演算法進行3D稀疏點雲建模。近年來,在基於影像式的3D稀疏點雲建模技術的研發已取得許多進展成果,並且成功應用於包括許多領域如古蹟保護、測繪和導航、虛擬旅遊、混合現實、自主機器人等。然在實作這些影像式3D空間稀疏點雲建模演算法時,其系統實作應用時的強健性(robustness)、準確性、完整性和計算效率等因素仍是相關技術研發的主要課題。
精彩內容
1. 典型的3D稀疏模型重建管道
2. 深度學習影像特徵點檢測及匹配方法
3. 實際場域應用驗證與差異比較 |
典型的3D稀疏模型重建管道
運動重建結構技術(Structure From Motion, SfM)是從一種建構3D場景結構和相機姿態的技術,透過不同視角下拍攝的無序或有序影像中建構3D場景結構和計算相機姿態的技術,將這一系列影像投影重建成3D 空間結構[4]。本章節將以增量式SfM為主,探討如何使用運動重建結構技術得到場景中的相機姿態和表示場景結構的稀疏點雲(圖1)。
COLMAP[5][6]提供一種通用的、端到端的基於影像的典型3D模型SfM重建管道,它提供了多樣廣泛的功能來執行3D空間結構重建。從一組不同視點拍攝同一對象的重疊影像作為輸入端,開始特徵提取、特徵匹配和幾何驗證程序。建構成的場景影像作為重建階段的基礎,使用精心挑選的初始雙視圖為模型重建的初始種子,再逐步註冊新影像、對場景點進行三角測量,和過濾異常值後,對於目標場景構建稀疏的3D點雲圖。由於影像配準(correspondence search) 和三角測量是獨立的計算程序,但整個增量模型建構中間過程會彼此相互迭代相關,其中相機位姿的偏移誤差會傳遞增到三角點計算,反之亦然。額外的三角測量可通過增加冗餘度(redundancy)來改善初始相機姿態(camera pose)資料。光束法平差(Bundle Adjustment, BA)是非線性最佳化的程序,使用3D場景點投影到2D影像空間的計算轉換公式定義損失函數,降低轉換公式權重的異常值來最小化重投影誤差(Re-projection error)。

圖1 增量式運動重建結構技術流程圖[3]
典型的3D稀疏模型重建管道
特徵點提取
在電腦視覺研究領域,尺度不變特徵轉換(Scale-invariant feature transform, SIFT)是最典型著名的傳統影像局部特徵提取位置及描述符的演算法。另外學習不變特徵變換(Learned Invariant Feature Transform, LIFT)是卷積網絡版的SIFT。LIFT管道包含特徵點檢測、方向估計和描述符計算。
特徵匹配
經影像局部特徵提取位置偵測及描述符值計算,影像特徵匹配通將採用影像特徵點描述符值進行搜索匹配,而最近鄰居法(Nearest Neighbors, NN)機制是最常被採用的判斷方法。典型的方式採用SIFT特徵參數與Lowe比率測試來過濾不正確的匹配,並相互檢查計算匹配率。
幾何驗證
由於匹配僅基於外觀樣式-即特徵點描述符值,因此不能保證相應的特徵點實際上是否映射到正確的3D場景特徵點(scene point)。由於每一對場景內容重疊的影像,存在幾何映射描述它們空間配置關係,利用幾何投影在影像之間映射特徵點的轉換關係可驗證其匹配正確性。Homography幾何關係描述平面場景的純旋轉或移動相機的變換方程式。對極幾何(Epi Polar)關係通過基本矩陣E(已校準)或基本矩陣F(未校準)描述了移動相機的關係。已有數學方程式被使用證明,在足夠數量的匹配特徵點情況下,則可用幾何驗證方法來推算影像間的移動關係,即可說它們是被認定經過幾何驗證。除外,為補償匹配對應關係受到異常值的污染影響,隨機抽樣一致性(RANdom SAmple Consensus, RANSAC)穩健的估計技術是常被引用於的技巧。
增量式重建
增量式重建是個逐漸增加視角,並進行迭代優化重投影誤差的過程[4],透過一連串無序或有序參考影像輸入,增量式SfM將進行一序列的影像特徵點提取、匹配、幾何驗證、三角量測與稀疏點雲建構運算程序,再通過點雲重新估計相對姿態,並進行局部和全局的BA優化。選擇合適的初始參考影像對增量式SfM重建程序至關重要,因為錯誤初始化重建可能永遠無法得到完善的場域稀疏點雲模型。若從密集影像圖位置選擇初始化影像,因具有許多重疊相機影像,通常會得到更穩健和更準確的重建效果,但因BA在重建過程中累積計算量大較耗時。相比之下,從位置稀疏處初始化會導致運行時間較短,但效果較不準確。COLMAP GUI提供可簡單操作介面軟體[5],點擊COLMAP GUI 中的「reconstruction」中的「start reconstruction」按鍵,可一鍵式自動執行增量式重建程序整個過程。
光束法平差(bundle adjustment, BA)
執行增量式SfM稀疏模型管道過程中,影像配準步驟和三角測量步驟雖是獨立運行的,但是它們運算結果輸出卻交互遞迴當作彼此的輸入參數,因此若是相機位姿計算中有誤差則會傳播到三角測量步驟,反之亦然。另外藉由使用額外的三角測量程序步驟可通過增加冗餘度來改善相機位姿誤差,反之亦然。
深度學習影像特徵點檢測及匹配方法
自監督深度學習的影像2D特徵點檢測和描述符
卷積神經網絡(Convolutional neural network, CNN)已被充分研究及證明在幾乎所有影像特徵工程的任務上都優於手工設計的演算法。這些卷積神經網絡需依賴著由人工註釋標記的2D 地面實況位置的大型數據集。為避免在真實影像中大規模繁雜的人工註釋工作,Daniel DeTone[7]提出了一個使用自我訓練的自監督興趣點檢測和描述符解決方案—SuperPoint。
SuperPoint是一個自我監督全卷積神經網絡(圖2),可在單個前向傳遞中計算類似SIFT的2D 興趣點位置和描述符。SuperPoint CNN神經網絡,使用由合成的三角形、四邊形、線、立方體、棋盤和星組成的合成形狀數據集,每個都有標定真實的角位置的合成數據,預訓練一個初始2D特徵點基檢測器(Base Detector)。與經典檢測器(如Harris, Shi-Tomasi , FAST[12])相比,該基檢測器網絡對噪聲更加強健。但基檢測器會錯過許多潛在的興趣點位置。為了彌合對真實影像的性能差距,他們創新一種多尺度、多變換技術方法Homographic Adaptation。應用Homographic Adaptation可有效自標記(self-labeling)來自目標場景的未標記影像,主動生成的偽真實標籤,爾後用於訓練全卷積網絡SuperPoint,圖3 展示迭代Homographic Adaptation方法在特徵點提取上的優化,圖3上行說明初始單使用基檢測器結果,難以找到可重複的2D特徵點提取。圖3中間和底行說明使用 Homographic Adaption 的進一步訓練提高了檢測器的性能。圖4為全卷積網絡SuperPoint編碼器/解碼架構,兩個解碼器共享輸入編碼器縮減空間表示的輸出。為了保持模型快速且易於訓練,兩個解碼器都使用非學習上採樣,將縮減空間內插恢復到原始影像大小。相較於其他2D特徵點提取(SIFT, LIFT, ORB),圖5 展示SuperPoint從輸入影像範例中同時提取興趣點和描述符的優越效能(使用NN進行興趣點匹配)。
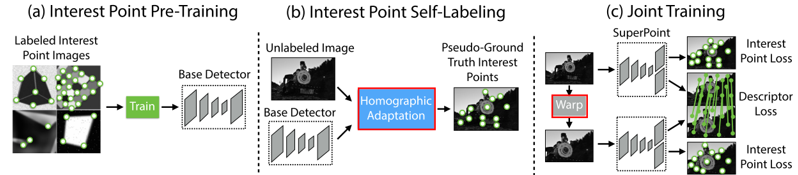
圖2 SuperPoint全卷積神經網絡[7]

圖3 Homographic Adaptation特徵提取優化[7]
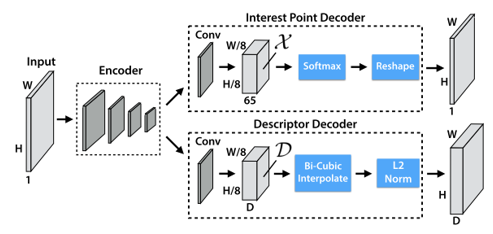
圖4 SuperPoint 編碼器/解碼全卷積網絡架構

圖5 各特徵提取演算法特徵提取與NN匹配結果[7]
SuperGlue-圖神經網絡(Graph Neural Network, GNN)深度學習特徵匹配技術
影像中特徵點之間的匹配關係對於估算SfM中的3D結構和相機位姿至關重要。一個理想的影像2D特徵點匹配模型應該做到,既能找到特徵之間的正確匹配,又可以鑒別錯誤匹配[8]。典型的影像2D特徵點匹配,通常通過所謂的數據關聯技巧來估計匹配局部特徵值(描述符)。但對於多視點和光照變化、遮擋、模糊和缺乏紋理等環境變數都將使2D到2D特徵描述符作為數據關聯時具有挑戰性。近期關於深度學習的特徵匹配技巧通常集中在使用卷積神經網絡,目標在從數據中學習更好的稀疏檢測器和局部描述符。受Transformer學習網絡模型成功的啟發,學習影像特徵描述符匹配問題也被轉化為找到兩組影像特徵之間的局部分配的新解決方案。例如,Sarlin[8]的圖神經網絡學習特徵匹配SuperGlue是一種圖神經網絡,通過聯合尋找對應關係並拒絕不可匹配的點來匹配兩組局部特徵。即使用自我(影像內)和交叉(影像間)注意力(Attention)機制來充分利用關鍵點的空間關係(context award)及其視覺外觀的資訊。注意力機制[10]可通過關注特定元素和屬性來執行全局和數據相關的局部聚合,因此更加靈活。
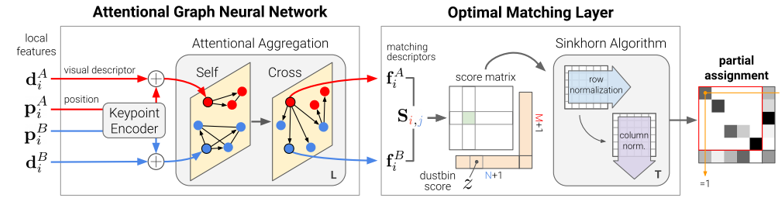
圖6 SuperGlue演算法架構[8]
如圖6所示,SuperGlue圖神經網絡學習特徵匹配架構由兩個主要模組組成,注意力圖神經網絡(Attentional GNN)和最優匹配層(Optimal Matching Layer)。可接收任何形式的影像特徵點(如SIFT、SuperPoint等)提取,注意力聚集(Attentional Aggregation)將特徵點以及描述符編碼成為一個向量(該向量可以理解為特徵匹配向量),隨後利用自我注意力(Self)以及交叉注意力(Cross)來回增強(重複L次)這個向量f的特徵匹配性能,隨後進入最優匹配層,通過計算特徵匹配向量的內積得到匹配度得分矩陣,然後通過Sinkhorn算法(迭代T次)解算出最優特徵分配矩陣第一個組件使用關鍵點編碼器將關鍵點位置及其視覺描述符d 映射到單個向量中,然後使用交替的自我和交叉注意層(重複L次)來創建更強大的表示f。 最佳匹配層創建一個M×N核心矩陣,用垃圾箱對其進行擴充,然後使用Sinkhorn算法(用於 T次迭代)找到最佳部分分配。
透過每對影像的端到端訓練來學習3D世界的幾何變換和規律性的先驗(prior information)。 SuperGlue已驗證其優於其他機器學習方法,在「ECCV 2020 Workshop on Long-Term Visual Localization under Changing Conditions」具有挑戰性的現實世界室內和室外環境中的攝影機姿態估計任務上取得了最先進的獎項。 而且所提出的圖神經網絡學習特徵匹配架構,也可在圖形處理器(Graphics Processing Unit:GPU)上實時執行匹配工作,無縫整合入現代SfM的應用系統中。
深度學習方法在實際場域應用驗證與比較
以典型的3D稀疏模型重建方法(SIFT +NN +COLMAP)進行實際場域建模實測
工研院資通所團隊以國立海洋科學博物館船舶廳為場域應用目標,利用Samsung S20錄製連續影片,再從中以1920×1080解析度,每秒3幀取樣2859張的參考影像資料庫。再採用COLMAP GUI以增量SfM技術進行稀疏重建。
首先針對輸入影像偵測並截取SIFT特徵點,接著進行特徵點匹配(NN Feature matching), 圖7中展示兩張圖之間兩影像的特徵點匹配結果。

圖7 兩圖的特徵點匹配,包含289個匹配點
接著利用上述特徵匹配結果進行稀疏模型重建。任意選取兩張作為起始圖片,估測其座標位置,之後逐漸迭代入新的視角圖後,以三角定位測量方式估測其應有的座標位置,再進行全局BA,優化整體相機6DoF與3D稀疏點雲座標,最後得到如圖8稀疏重建模型結果,圖中左下角有一塊明顯空缺,分析該區塊為出口位置,含有一大面落地窗,光線直射不易取樣,附近牆面多為金屬材質直接反射光線,且牆上並無任何掛飾缺少明顯SIFT特徵點,導致該區塊建模結果不完整。

圖8 船舶廳稀疏重建模型結果
以深度學習方法(SuperPoint + SuperGlue +COLMAP)進行實際場域建模實測
同樣以國立海洋科學博物館船舶廳為場域應用目標,利用GoPro Hero9錄製場域影片,以1920×1080解析度,每秒3幀取樣3114張的參考影像資料庫。再以深度學習方法(SuperPoint + SuperGlue)搭配COLMAP增量SfM技術進行稀疏重建。
圖9是SuperPoint影像特徵提取範例,產生1702個特徵點,其中幾何驗證步驟後剩1144個有效的特徵點。圖10展示使用SuperGlue對兩張影像間兩進行特徵匹配結果,範例中有229個有效匹配點,特徵匹配效果很好。

圖9 SuperPoint影像特徵提取範例

圖10 SuperGlue 特徵匹配範例
接著利用特徵匹配結果,使用Pycolmap(colmap的Linux python版本)進行稀疏模型重建。先選取兩張作為起始圖片,估測其座標位置,之後逐漸迭代入新的視角圖後,以三角定位測量方式估測其應有的座標位置,再進行全局BA,優化整體相機6DoF與3D稀疏點雲座標。圖11為稀疏重建模型結果。
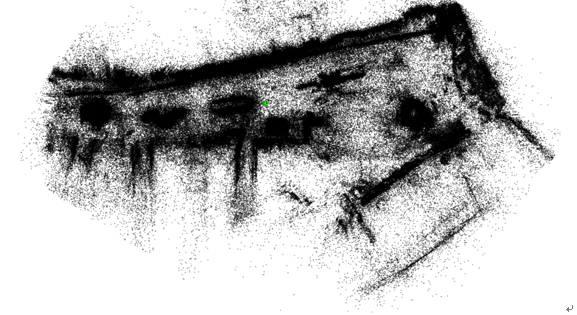
圖11 應用深度學習方法SuperPoint+SuperGlue+COLMAP稀疏點雲建模範例
為驗證視覺定位效能,以海科船博館時所拍攝影帶部分選取影像時,其他位置影像的照片輸入進先前建完的稀疏點雲模型進行6DoF位姿估算,如圖12展示,綠色相機位姿的位置是採用PnP、RANSAC演算法所計算出拍攝該照片所在位置位於模型中的位置。
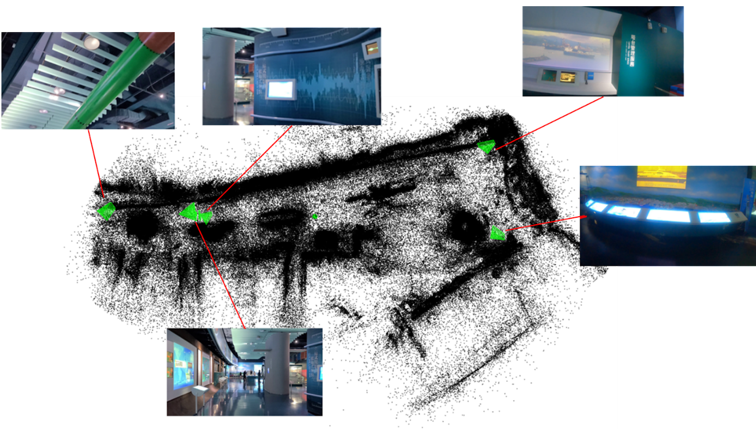
圖12 6DoF視覺定位效能驗證
從本實例可看出此演算法對室內稀疏模型重建有不錯的結果,可應用於元宇宙中將現實世界環境進行虛擬模型建構,提升沉浸式體驗效果。即便往後新的影像輸入後,可在辨識其中的特徵點後,與之前影像匹配計算新的影像於模型中的6DoF資訊,有助於後續虛擬物件建構與定位擺放,讓成像的視覺效果容易與環境融為一體,更加擬真。
結論
目前對靜態的室內外環境物體,應用典型或深度學習的3D空間稀疏點雲建模與6DoF視覺定位技術,大都可以得到滿意的應用效果。然而,在室內場景應用驗證時,由於空間內相對幾何距離近,在視覺定位取向時視點的微小變化也會導致影像內容發生很大變化,同一場景特徵點所得對應不同視角影像特徵點參數的變化量大,典型方法中唯一使用影像特徵點符做為匹配的參考資訊,容易因錯誤匹配結果或有效匹配點數太少問題,無法得到準確的視覺定位效果。面對部分室內場景是無紋理的區域,傳統影像處理技巧的特徵點偵測及匹配效能差,也會導致視覺定位姿態估計不穩定。因此,室內視覺定位方案必須處理實際還就變異情況下查詢影像和參考影像之間明顯的外觀變化。同時,相較於室外建築立面的整體外觀不易隨著時間的推移而發生大變化,而室內場域卻較易隨家具和大物品在環境中移動而需高頻率修正點雲模型。本文所提到的深度學習影像特徵點提取及特徵點匹配方法即是因應上述問題的創新解決方案。3D空間稀疏點雲建模與6DoF視覺定位技術的完整性和強健性議題,相信持續會是相關研究的努力方向。
參考文獻
[1] The Visual Localization Benchmark, available:https://www.visuallocalization.net/
[2] ECCV 2020 Workshop on Long-Term Visual Localization under Changing Conditions Available:https://sites.google.com/view/ltvl2019, https://sites.google.com/view/ltvl2020/home
[3] Johannes L. Schönberger, Jan-Michael Frahm et al., Structure-from-Motion Revisited. Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
[4] Johannes L. Schönberger., Robust Methods for Accurate and Efficient 3D Modeling from Unstructured Imagery. PhD Thesis, 2018.
[5] COLMAP document:https://colmap.github.io/index.html
[6] 3D Reconstruction with COLMAP, CMU online webpage, available:https://www.cs.cmu.edu/~reconstruction/colmap.html
[7] Daniel DeTone, Tomasz Malisiewicz, Andrew Rabinovich, SuperPoint:Self-Supervised Interest Point Detection and Description, SuperPoint:Self-Supervised Interest Point Detection and Description, 2018 CVPR workshop paper.
[8] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, Andrew Rabinovich. SuperGlue:Learning Feature Matching with Graph Neural Networks, 2020 CVPR paper.
[9] Paul-Edouard Sarlin, hloc - the hierarchical localization toolbox , available:https://github.com/cvg/Hierarchical-Localization
[10]Ashish Vaswani etc., Attention Is All You Need, Advances in Neural Information Processing Systems 30 (2017)
[11] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperPoint:Self-supervised interest point detection and description. In CVPR Workshop on Deep Learning for Visual SLAM, 2018
[12] Haydar A.Kadhima, Waleed A.Araheemah, A Comparative Between Corner-Detectors (Harris, Shi-Tomasi & FAST) in Images Noisy Using Non-Local Means Filter, Journal of Al-Qadisiyah for Computer Science and Mathematics Vol.11 (3) 2019.