中文摘要
本文回顧工研院LTE小型基地台自有技術在MAC層排程器的軟體架構, 並分析排程器目前架構設計上可能面臨的問題,包括初傳與重傳的延遲、頻譜資源的使用效率,以及軟體實作時面臨的硬體資源限制,如記憶體使用量等。為了改善這些問題,文中提出了以子幀為預排單位的排程器設計,使得初傳和重傳延遲得以大幅下降,同時頻譜資源與記憶體的使用效率也獲得改善。經排程器新架構的實作後,從實際平台的量測數據來看,提供了應用層封包來回時間3成的改善。
Abstract
The scheduler design of LTE Small Cell that is independently developed by ITRI is reviewed in this work. The performance of the scheduler is analyzed, including transmission latency and efficiency of radio resource and memory usage. A new subframe-based scheduling architecture is then proposed to improve the performance of the ITRI LTE Small Cell. Analytically, the transmission latency can be greatly reduced, and the efficiency of radio resource and memory usage can be significantly enhanced. The new scheduling architecture is implemented on TI6670 DSP platform, and the round-trip time measured by the application layer can be reduced by 30%.
關鍵詞(Key Words)
LTE小型基地台 (LTE Small Cell)
排程器 (Scheduler)
媒體存取控制 (Medium Access Control;MAC)
1. 前言
近年來,各種雲端服務應用在智慧手機、穿戴裝置…等各類行動通訊裝置上蓬勃發展的情況下,人們對於行動通訊的服務品質以及連網速率的需求日益增高。目前各大工業國已展開第五代行動通訊的研究與開發, 預計將在2020年左右完成開發,並開始導入市場。目前第五代行動通訊的規格尚未底定, 但從目前學界、業界專家們的討論範疇中,仍可歸納出幾項特徵[1]:(1)支援Gbps的吞吐量;(2)佈建小型基地台以提升用戶支持密度;(3)整合現存通訊技術。從以上特徵可窺見為了達到高吞吐量及高密度用戶, 無線資源的管理和用戶排程技術是其中一項關鍵技術。有鑑於此,本文將探討次世代無線通訊系統小型基地台(Small Cell)的通訊資源管理和即時排程, 以提升頻譜資源的使用效率,提供稠密地區用戶更快速的網路服務。
目前在4G LTE的規範中對於基地台如何調度無線頻譜資源來服務用戶端並無詳細的規範,亦即基地台在什麼時候、分配多少無線資源給用戶端傳輸資料係屬於各家廠商在實作時的考量。因此廠商們組成了Small Cell Forum,討論出一套可行的實作範例,特別由LTE MAC(Medium Access Control)層中切割出獨立的Scheduler模組,並定義Scheduler模組和MAC、RLC(Radio Link Control)、PHY API (Physical Layer Application Programming Interface)之間的溝通介面,負責所有LTE規範中的排程工作,包含了上至高層邏輯通道抽象的QoS
(Quality of Service) 管理,下至實體層HARQ(Hybrid Automatic Repeat reQuest)重傳資源的分配等等。從軟體實作角度而言,Small Cell所提出的範例仍屬於較大塊的軟體模組,其子模組的分工切割、或排程演算法的實現方法均未闡明, 因此實作功能完整又效能好的排程器十分值得各家廠商投入研發。在學界方面,大部分的論文較著重於抽象的排程演算法分析或數值模擬,對於LTE標準所產生的限制條件考量較少,常因演算法的複雜度較高而不利於實作。
2. 現存排程器架構簡介
本節針對工研院資通所M組在FY103年所開發出來的LTE Small Cell基站端進行軟體架構的回顧,並分析目前軟體架構在排程器(Scheduler)可發生的潛在問題,以提供未來可能改進的方針。
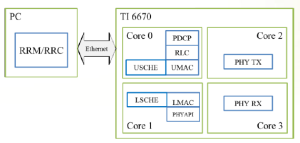 圖1 LTE protocol stack 與硬體計算資源配置
圖1 LTE protocol stack 與硬體計算資源配置2.1 硬體計算資源分配
LTE小型基地台之協議棧分工與硬體計算資源分配如圖1所示。LTE的第三層協議實作於一台x86的PC平台上,其包括RRC (Radio Resource Control)和RRM (Radio Resource Management)的部分。在實作LTE第一、二層協議的硬體平台為德洲儀器(TI)的TMS320C6670 EVM開發板,其所使用的DSP為TIC6670,為一顆四核心的DSP處理器[2]。LTE第三層與第二層模組之間的溝通以UDP socket進行傳送。
考量到LTE第一、二層各模組的複雜度不同與其間的互動關係,而將不同的LTE模組分配至不同的DSP運算核心(Core)。其中Core 0負責PDCP (Packet Data Convergence Protocol)、RLC、Upper MAC(UMAC)、Upper Scheduler(USCHE)及其他系統服務模組(如:System Tick、UDP socket的收送…等);Core 1 的負責Lower MAC (LMAC) 、Lower Scheduler (LSCHE)和與PHY的應用程序接口(PHY API),PHY API的部分依照Small Cell Forum所製定的文件進行實作[3]。Core 2的部分負責基地台PHY層傳送訊號的產生;Core 3的部分負責基地台PHY層接收訊號的解碼。
從LTE協議運作的時間基本單位來看,下層的模組包含LMAC、LSCHE、PHY API,是以子幀(subframe)為單位來運作,一張子幀的長度為1毫秒;而上層的模組,包含UMAC、USCHE、RLC、PDCP、RRC和RRM,是以系統幀(frame)為單位進行運作,一張系統幀的時間長度為10毫秒。會將MAC層切割成上下兩半,並在不同的時間單位上運作,是由於MAC層恰位於上、下兩層之間採用不同的運作時間單位。MAC層對上以UMAC和USCHE為主,以系統幀為單位運作,看的是各UE (User Equipment)和其logical channel的狀態是否滿足QoS的條件,如:最大和最小的吞吐量、封包延遲上限…等,並根據這些統計資料,決定要向LSCHE要求多少的頻寬來進行傳輸。MAC層對下是以LMAC和LSCHE為主,以子幀為單位運作,關注的是如何適當地分配無線頻譜資源(Resource Block;RB)給每支UE,來滿足它們的頻寬需求,以及控制PHY如何進行傳送及解調,使得無線頻譜資源能達最大的利用效率,以提升系統整體的效能,如:高吞吐量和低傳輸延遲。
2.2 MAC無線資源分配流程
圖2說明了整個無線頻譜資源分配的流程,從欲送給UE端的資料被塞入基站端的佇列開始,一直到佇列中的封包被基站端的PHY送出。在整個資源分配的流程中,MAC層一共有8大工作需要執行,USCHE、UMAC、LMAC、LSCHE各司其職,各工作項目內容整理如下:
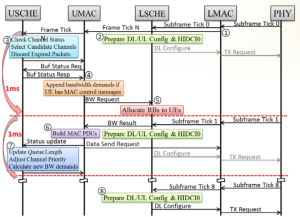 圖2 無線資源分配流程的MSC 圖
圖2 無線資源分配流程的MSC 圖
- 當PHY發送子幀0給LMAC/LSCHE時,子幀0也代表是一張系統幀的開始,因此LMAC會發送系統幀編號給UMAC。(以下將以時間Nn來表示系統幀N,子幀n的時間點。)
- LSCHE在每張子幀開始時會檢查此張子幀有那些程序需要處理,可能的程序包含:(a)向PHY設定2張子幀後的下行傳輸設定。(b) 向PHY設定4 張子幀後的上行資源分配。(c)向PHY設定前1張上行子幀的解調參數。
- 當UMAC收到一個系統幀的事件時,會通知USCHE開始為系統幀N+2的頻寬需求做準備,包括確定那些邏輯通道是處於激活狀態,並預選出要安排頻寬的邏輯通道清單以供步驟7查詢使用。此外USCHE也會檢查各邏輯通道的佇列內是否有超過期限的封包,若有則刪除該封包。
- UMAC向USCHE詢問系統幀N+1 各支UE所預計要傳輸的資料量。USCHE從記憶體中取出在系統幀N-1 時頻寬需求結算的結果並回傳給UMAC(即Buf Status Req/Resp)。由於USCHE只負責邏輯通道的資料量估算,不含MAC層本身的控制訊息,因此UMAC會再檢查每支UE是否有MAC的控制訊息需要傳送。若有,則UMAC會再將控制訊息的大小加入頻寬需求(BW Request)的總量中。
- LSCHE依照UMAC所給的頻寬需求進行頻譜資源的分配。分配的結果會明確指出在系統幀N+1內每一張子幀有哪些UE可進行傳輸,以及每支UE一次可傳送的資料量大小。LSCHE將資源分配結果暫存於記憶體,並在子幀1時將資源分配結果傳送給UMAC。
- UMAC依照LSCHE資源分配的結果為系統幀N+1 內的每張子幀、每支UE組出相對應大小的PDU (Protocol Data Unit)。UMAC會依先前USCHE給各邏輯通道的優先權及需求量依序組出MAC PDU並符合LSCHE所指定的大小。
- 在UMAC組完PDU後,UMAC會呼叫USCHE對各個邏輯通道的佇列長度進行更新,以扣除方才UMAC組出PDU的大小。在邏輯通道的佇列長度更新後,USCHE會依照各邏輯通道的飢餓程度調整預選清單內邏輯通道的優先順序,其中邏輯通道的預選清單是於步驟3.產生的。最後USCHE依照邏輯通道的優先序結算出各支UE在系統幀N+2 所應該傳送的資料量。結算的結果先暫存於記憶體中,等待系統幀N+1時由UMAC呼叫後取出。
- UMAC 在組完系統幀N+1 的PDU 後向LMAC告知記憶體位址。當系統幀N子幀8觸發LSCHE動作時,LSCHE會向LMAC下達系統幀N+1子幀0的下行傳輸設定。在PHY收到下行傳輸設定後的兩張子幀,PDU的訊號就會由天線打出。
在實作上,一項或數項工作必需在一張子幀的時間內完成,否則會延誤到其他由子幀觸發的事件,如:Core 0在每張子幀需搬移無線模組要收送的資料。由於UMAC組PDU和USCHE產生新的頻寬需求需要花較多時間,在上述的設計中,如圖2所示,把步驟1~5規劃在子幀0的時間內完成,而步驟6、7規劃在子幀1的時間內完成,避免步驟1~7一次在子幀0做完而延誤到其他工作項目的時程。
3. 現行排程器效能分析與問題

圖3 MAC 層初傳與重傳的延遲圖3 MAC層初傳與重傳的延遲
基於第2節描述的資源分配流程,本節分析該流程產生的效能限制與問題。在以下的分析中,為了方便說明與容易了解,是以TDD(Time Division Duplex)模式上下行設定2為例子來進行說明,在此設定中只有子幀2和7為上行子幀,其他為下行子幀。
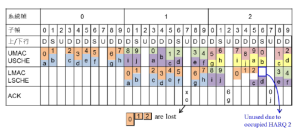 圖4 由於HARQ 重傳造成的無線資源畸零化
圖4 由於HARQ 重傳造成的無線資源畸零化3.1 初傳與重傳的時間延遲
在此定義的初傳延遲為從USCHE計算頻寬需求到MAC PDU移送給PHY層的時間差。搭配圖2的流程,以圖3的例子做說明,圖中最上面兩列表示系統幀和子幀編號,1張子幀為1ms;第3列表示上/下行(U/D);第4、5列中的上色方塊表示傳送PDU的HARQ process編號。UMAC在時間00向LSCHE提出時間10~19預計使用的頻寬要求,LSCHE在時間01回覆UMAC無線資源配置結果,UMAC依資源配置的結果組好10~19要送的PDU。PDU被安排由HARQprocesses 0~7分別在時間10~19送出,當時間10時,LSCHE會產生時間10的下行傳輸設定送給LMAC,使得PHY傳送時間01組好的PDU。也就是說UMAC在系統幀0組好的PDU會在系統幀1被LSCHE下令送出,因此初傳的延遲約為1張系統幀(10毫秒)。初傳的時間延遲基本上是由於UMAC和LSCHE預排資源和預組PDU所造成的,預排和預組提早的時間恰為1張系統幀。
3.2 頻譜資源的畸零化
所謂「頻譜資源的畸零化」指的是在MAC預排了一些PDU至頻譜上的資源後,剩餘的頻譜資源不足再容納其他的PDU而空下。換言之,畸零化的現象愈嚴重,則頻譜資源被浪費得愈嚴重,系統整體的最高吞吐量就會減少。
一個可能發生資源畸零化的狀況是在HARQ重傳時。圖4描述兩支UE在同時進行資料傳送時,其中一支UE發生重傳時的案例。圖4中的一個彩色方塊表示一個MAC PDU,彩色方塊的大小表示該PDU佔用頻譜資源的多寡,方塊上的文字表示傳送該PDU 時所使用的HARQ process ID,其中第一支UE以阿拉伯數字表示,而另一支以英文字母表示。在資源完全利用的狀況下,兩支UE的彩色方塊(PDU)需恰填滿白色的空格。若有留白,則表示有資源未完全利用。假設UE 1在時間17回報HARQ process0~2中有PDU發生遺失。依據LTE規範,基站端最快可在收到NACK後的第4個子幀進行重傳[4],即時間21後的下行子幀。由於一條HARQ process只能在完成重傳後才能傳送新的PDU,為了避免無HARQ process可用的情況,重傳的時間須由LSCHE 盡快安排,不由UMAC 和LSCHE之間的預排來處理。在例子中,LSCHE在時間17得知需重傳後,把重傳的時間點安排在23~25。在這些重傳的PDU佔用掉頻譜資源後,UMAC在時間11預組好給UE 2的PDU並無法完整塞入剩下的頻譜資源, 因當時還不知會有重傳發生。因此只能推遲傳送這些過大的PDU,部分頻譜資源也就被閒置。相反地,預組好的小PDU雖然可以完整放入,但仍可能留下空白的頻譜。因此不管PDU大小,只要不符合重傳後剩餘的頻譜資源大小,就會產生頻譜資源畸零化的現象,使資源發生閒置和浪費。
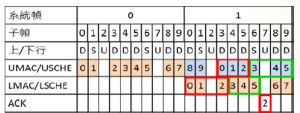 圖5 LMAC 和UMAC 在1 張系統幀內讀寫相同 的HARQ Buffer
圖5 LMAC 和UMAC 在1 張系統幀內讀寫相同 的HARQ Buffer3.3 雙倍記憶體或減半的吞吐量
一筆PDU由一條HARQ process負責傳送,當有遺失要進行重傳時,會從HARQ的Buffer(記憶體)中取出前次傳送的PDU。圖5說明一個例子當HARQ Process的數量小於兩倍LSCHE和UMAC之間的預排和預組週期時,LMAC和UMAC 會在同一系統幀內讀寫相同的HARQBuffer,造成MAC送出的PDU不完整或是變成錯誤格式的PDU。圖5的例子是TDD模式上下行設定2,在此設定下下行的HARQ process一共有10條,而當前基站端的LSCHE和UMAC是以一張幀為預排和預組PDU , 使得10 條下行HARQ數量小於2張系統幀內的16張下行子幀數。因此在此例中LMAC和UMAC會在同一系統幀內讀寫相同的HARQ Buffer,例如:時間11時,UMAC會在HARQ buffer 0~5組出時間23~29要送出的PDU,但LMAC會在同一時間(10~16)將HARQ buffer 0~5內的PDU送出,但其內容可能被UMAC在時間11竄改。
當下行HARQ的數量不足於2倍預排預組週期內的下行子幀數時,只要UE持續有資料需要傳送,LMAC與UMAC之間同時讀寫相同的HARQ Buffer的狀況會持續發生。為了避免同時讀寫相同的記憶體,HARQ記憶體的使用量必需變成2倍,或是當無可用的記憶體可用時,直接令UMAC不組PDU,這將使得系統的吞吐量大幅減少。在圖5的例子中,兩張系統幀內的16個下行子幀,只有10個Buffer可使用,因此UE的吞吐量只剩正常量的60%左右,少了40%的吞吐量。在FDD模式下,由於HARQ的數量只有8個,吞吐量只達正常量的50%以下。
4. 排程器架構改善方案
本節將對第三節所提出來的問題進行改善方案的提案,包括提案的內容本身、採用提案後所帶來的好處。
4.1 以子幀為預排的排程器設計
在MAC執行一次排程工作時必需預估未來一段時間內的頻寬需求與頻譜資源變化,當預估的時程愈長,估算的結果就愈不準,造成第三節中描述的問題。因此應該儘量把預估的時程縮短,同時顧及硬體處理速度,因此會有一下限。以目前的硬體平台及軟體架構而言,PHY層的處理時間需預留2張子幀,而MAC層(含無線資源分配及組PDU)的時間需預留1張子幀。因此總體而言,進行無線資源分配及組PDU的時間點至少必需提早3張子幀的時間開始運作。換言之,預排時程的長度至少需為3張子幀。
就LTE協議本身而言,有部分下行方向的訊息需要即時插入頻譜資源,如隨機接取程序的訊息2(Msg2)或是HARQ重傳的PDU。就訊息2而言,其最長的時間延遲為10毫秒,在UE送出Msg1(preamble)後,訊息2延遲超過10毫秒則表示隨機接取程序失敗。為了確保訊息2可以及時傳送,MAC的預排和預組週期必需小於一半的訊息2時間延遲限制,即5毫秒。如此才可以確保訊息2在過時之前至少會遇到一次完整的MAC預排和預組PDU流程。對於HARQ重傳而言,從初傳到收到HARQ回饋,至少需要4張子幀的時間。換言之,從一筆PDU佔用一個HARQbuffer到確定該筆PDU可從Buffer抹去(可讓新的PDU寫入)的時間間隔至少需4張子幀。因此只能確定一個HARQ Buffer在4張子幀內的狀態,超過4張子幀後,HARQ Buffer可能得裝的是重傳的PDU或是新傳的PDU。MAC預排和預組的時間長度不應超過最短的HARQ回饋時間長度, 否則可能會發生重傳的PDU必需插入取代新的PDU,造成頻譜資源畸零化的現象。
總合以上考量,MAC層預排和預組PDU的時間長度(週期)應小於4張子幀的時間,且應大於3張子幀的時間。以TDD模式上下行設定2為例,表1列出在預排長度為3張子幀下,各模組在每張子幀內各需處理相應子幀號碼的對照表。以實際上子幀3的時間點為例: 1) LSCHE需計算子幀6的RB分配; 2) UMAC跟據RB分配的結果組出子幀6的PDU;3) LSCHE 向PHY 下達子幀5的下行傳輸設定;4)PHY傳送子幀3的PDU。對於同一包要傳送的資料而言,如:子幀3要送出的資料, 在各個模組被處理的時間點為: 1)LSCHE 在子幀0 時安排子幀3 的RB 資源; 2)UMAC在子幀0組出子幀3要傳送的PDU; 3)LSCHE在子幀1時下達子幀3的下行傳輸設定給PHY; 4) PHY在子幀3時送出該筆PDU。
4.2 以子幀為預排的優勢
本節是以在3張子幀為預排長度的前提下,重新檢驗第三節所描述的問題是否均已解決。
4.2.1 至少減半的初傳和重傳延遲
在以子幀為預排單位後,初傳和重傳延遲大幅下降。以圖6為例,UMAC在時間09時根據LSCHE對時間10的無RB分配結果組出PDU,LMAC在時間10時將下行傳輸設定及PDU送至PHY。MAC層的初傳時間延遲為1毫秒。對照以系統幀為預排的圖3, 可以發現MAC的初傳延遲由10毫秒降至1毫秒,有10倍的進步空間。對於重傳的時間延遲而言,受限於TDD模式的規範,其包含4~13張幀的HARQ回饋延遲、2~4張的上行子幀時間、1張子幀的預排長度,重傳的時間延遲應可在20毫秒內完成,以圖6為例,PDU0在時間10進行初傳,在時間17得知遺失,在時間22預排重傳,時間23將重傳的PDU送至PHY,一共花了13毫秒。對照以系統幀為預排的圖3,可以發現MAC的重傳延遲由36毫秒降至13毫秒,約有3倍的進步空間。
4.2.2 無畸零化的頻譜資源
在HARQ發生重傳下,以子幀為預排的排程器可由圖6來說明其行為。假設UE 1和UE 2分別在系統幀1用HARQ 0~7和a~h傳送了8個PDU,結果UE 1在時間17回報PDU發生遺失。依LTE規範最快可在收到NACK後的第4張子幀開始進行重傳,即在時間21之後的下行子幀。假設LSCHE 在時間17 得知需要重傳後,把HARQ 0~2重傳的時間點安排在時間23~25,則LSCHE 只需分別在時間22~24 時,在向UMAC回報頻譜資源分配結果中把重傳的頻譜資源預先空下來。這使得UMAC在時間22~24組UE 2在時間23~25要送的PDU (HARQ a~c)時,可組出適當的PDU大小,剛好符合在UE 1HARQ 0~2重傳PDU插入後頻譜資源剩下可用的空間。在時間23~25時,LMAC正好就可以把UE 1重傳的PDU和UE 2新傳的PDU一起送出,沒有PDU大小與剩餘空間不匹配的情況發生。因此即使有HARQ重傳, 以子幀為預排單位的排程器不會發生頻譜資源畸零化的現象。
4.2.3 減半的記憶體使用量
以系統幀為預排單位的排程器會因為一次需要組出一張系統幀(10張子幀)內的PDU, 會一次佔用多達10個HARQ Buffer,造成Buffer數量不足的問題,或是使得UMAC和LMAC之間需各自獨立的Buffer,耗費兩倍的記憶體。 在預排和預組PDU改成以子幀為單位後,UMAC一次只會組出一張子幀所要送出的PDU,即一次只會佔用一個HARQ Buffer。而LMAC一次也只會去抓取另一個HARQ Buffer的PDU來傳送。如圖6所示,同一時間內UMAC和LMAC存取的HARQ Buffer是錯開的。以目前LTE的規範,下行的HARQ Process數量至少會大於兩個[4],是足夠讓UMAC和LMAC之間交替使用的。以FDD模式為例,有8個下行HARQ Process可使用;在TDD模式上下行設定2中,則有10個下行HARQ Process可使用。
5. 數據量測
本節將第四節以子幀為預排單位的排程器實作到TI DSP的系統上,並進行時間的量測,數據量測的結果如下呈現。
5.1 傳送資料時的執行時間
首先測量16支UE與基地台建立連線成功後,其中一支UE進行下行資料傳輸動作所花費的時間。使用Iperf當作應用層的資料封包產生器,封包大小為500Bytes,使用UDP協議來傳送封包,傳送的資料量由500 Kbps、1000 Kbps,依序到3Mbps。目的是測量各模組在有不同資料量傳輸時執行時間上的變化,評估未來增加系統頻寬時可能面臨的風險。
 |
 |
| 圖7 以系統幀為預排單位的排程器之執行時間 |
圖8 以子幀為預排單位的排程器之執行時間 |
圖7和圖8分別表示以系統幀為預排單位的排程器,和以子幀為預排單位的排程器,之各功能模組的執行時間隨下行傳輸的資料量增加而變化的情形。其中X軸表示一支UE下行傳輸的資料量,以kbps為單位;而Y軸表示DSP執行某一功能模組所花費的時間,以微秒(us)為單位。「LSCHE (Sf+RB)」代表圖2中步驟2和步驟5的時間總和;「UMAC Frame Tick」代表圖2中步驟4的執行時間;「USCHE Frame Tick」代表圖2中步驟3的執行時間;「UMAC Building PDU」代表圖2中步驟6的執行時間;「USCHE BW Demand」代表圖2中步驟7的執行時間。
在圖7中由於LSCHE和UMAC之間是以系統幀為單位進行無線頻頻譜資源的分配和組PDU,因此當要傳送的資料量變多時,LSCHE要分配頻譜資源的次數就會增加,同時UMAC也需組出更大的PDU而花費更多的時間。但當LSCHE把一張系統幀內的所有子幀都拿出來分配時,執行時間就飽和,不會再隨資料量變多而上升,如圖7中的2600 kbps和3000 kbps。不過UMAC在組PDU的部分還是會隨傳送的資料量增加而拉長執行時間。對於其他功能模組,如:UMACFrame Tick、BW Demand的更新,及USCHE Frame Tick,因和傳輸資料量的大小沒有直接關係,所以執行時間對於傳輸資料量的大小呈現不敏感的狀況。
在圖8中由於LSCHE和UMAC之間是以子幀為單位進行資源分配和組PDU,因此當要傳送的資料量增加時,各功能模組在每張子幀由閒置變成忙碌的比率就會上升,但一旦一張子幀被用來傳輸資料時,其花費的處理時間大約是固定的,例如:在500kbps時,可能只有2張子幀被用來傳送資料,而在1000kbps時,則可能有4張子幀。因此原本在圖7中的LSCHE分配無線頻譜資源和UMAC組PDU都會隨著傳輸的資料量增加而增加執行時間,在圖8中兩者變為水平線,對於資料量的增加變得不敏感。另外,圖8的結果是挑選各張子幀中最忙碌的子幀來進行量測。
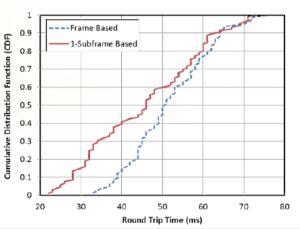 圖9 封包來回時間的累積機率分布圖
圖9 封包來回時間的累積機率分布圖5.2 傳送資料時的執行時間
為了驗證排程器在由以系統幀為預排單位改成以子幀為預排單位後,應用層封包的傳輸延遲是否確實有改善,在16支UE與基地台連線的狀況下,令其中一支UE發送Ping至一台遠端的伺服器,再由伺服器回應給UE,UE端測量發送和接收的時間差當作是封包來回的時間。
圖9顯示測量結果,X軸表示封包來回時間,以毫秒為單位; Y軸表示累積機率函數值, 以0~1表示。由圖可看出以子幀為預排單位的排程器之封包來回時間的分布大部份皆位於以系統幀為預排單位的排程器的左側, 表示以子幀為預排單位的排程器之封包來回時間大部份皆小於以系統幀為預排單位的排程器。從最小的封包來回時間來看, 以系統幀為預排單位的排程器需費時33毫秒左右,而以子幀為預排單位的排程器之最小的封包來回時間只有22毫秒左右,縮短了11毫秒,進步了33%。從平均封包來回時間來看, 以系統幀為預排單位的排程器需費時51毫秒,以子幀為預排單位的排程器僅需45毫秒,有6毫秒差距,約12%的進步。
6. 結論
本文首先回顧FY103年工研院在LTE小型基地台自有技術在MAC層排程器的軟體架構,接著分析當前排程器設計可能面臨的問題,包括10毫秒的初傳延遲、40毫秒的重傳延遲、頻譜資源的畸零化、雙倍記憶體使用量等。為了改善這些問題,我們提出了以子幀為預排單位的排程器設計,使得初傳延遲得以下降至1毫秒、重傳延遲下降至20毫秒以下,同時解決了頻譜資源畸零化與雙倍記憶體的問題。在將新排程器設計實作後, 從實際平台的量測數據來看,應用層封包的最短來回時間也降低了3成。
作者簡介
林佑恩
現任工研院資通所新興無線應用技術組軟體設計部工程師,負責次世代無線媒體接取層之開發。 2006年取得交通大學電機與控制工程學士, 2013年取得台灣大學電信工程研究所博士。 E-mail:You-En.Lin@itir.org.tw
王淑賢
現任工研院資通所新興無線應用技術組軟體設計部工程師,負責LTE小型基地台媒體接取層之開發。 2013年畢業於清華大學通訊工程研究所。 研究領域為無線通訊系統的MAC-PHY跨層式傳輸機制設計。 E-mail:itriA30049@itir.org.tw