工業技術研究院 資訊與通訊研究所 王書凡 王慶堯 曾琬婷 吳芷綺

利用AI自然語言模型語意理解與辨識技術進行合約文本審閱,協助法務人員進行合約完整性、合理性與合規性審閱。
前言
在企業商務活動中合約簽訂至關重要且無處不在,法務人員必須處理多方工作內容,包括客戶溝通、檢視歷史合約資料、審閱合約內容與權益分析、合約內容客製化修訂等。此過程除了需要法律專業知識外,亦需人員長時間的高度專注力,因此耗費相當高的人力及時間成本。本技術利用AI自然語言模型語意理解與辨識技術,依據合約文本審閱架構進行合約條款、構成要件與要件情境辨識,可以協助法務人員進行合約完整性、合理性與合規性審閱,除了有效降低合約審查時間與複雜度,同時提升企業合約文本數據化分析能力、清楚掌握企業合約風險。
精彩內容
1. 合約文本審閱架構
2. 合約智能辨識處理流程與技術
3. 應用案例探討與未來發展方向 |
動機與背景
針對商務往來文件與營運管理文件,企業往往需花費大量領域專業人員進行處理與審閱,以合約文件而言,根據 Deloitte 統計[2],企業平均在一份保密協議需八天、委外服務合約需37天、一份授權合約簽訂甚至需74天進行簽訂處理,主要缺乏智慧化合約管理系統來協助企業人員進行文件草擬、審閱、處理與管理。
隨著AI自然語言處理(NLP)技術在文字萃取與語意理解能力長足進展與突破,許多研究紛紛投入發展相關可應用於協助合約審閱的技術,協助降低合約處理作業時間並減少疏漏。然而相關研究成果[1][6]仍著重於合約中相對單純的構成要件(例如:對象、標的物、合約金額、付款日期)資訊辨識與處理、未考慮合約條款與構成要件之間的依存關係[5]、未進一步分析構成要件的應用情境,造成在實務商業導入與落地上存在一定程度鴻溝。
本技術以合約條款、構成要件與要件情境作為合約文本審閱階層架構,以 BERT(Bidirectional Encoder Representations from Transformers)語言模型語意理解技術為基礎[3],分別應用 BERT 在句子分類(sentence classification)、句子序列標記(sequence labeling)等兩種模型作法進行合約條款、構成要件與要件情境等逐層內容辨識解析。除了嘗試辨識文義結構複雜構成要件(例如:損害賠償責任、保密人員規範、合約終止規範),同時適度考量合約條款與構成要件的依存關係,提升構成要件辨識準確度。經由19份委外軟體開發合約實驗數據顯示,本技術在38項構成要件之辨識準確率為81.7%,其中文義結構不複雜構成要件平均能夠達到90%辨識準確度,對於部分複雜構成要件辨識結果內容片段、不完整的情形,也從模型調整、特徵資訊擴充以及大語言模型(LLM)導入等未來技術精進方向進行探討說明。
合約文本審閱架構
商務合約通常用以規範企業雙方或多方之間在特定交易下基於各自利益要求所達成的一種協議,在合約內容中通常會以條款(clause)型式清楚規範雙方交易利益之範圍條件與權責關係,以委外軟體開發服務合約而言,通常會包含「合約標的」、「付款時程」、「交付規範」、「驗收及修正」、「權利歸屬」等條款;同時每個條款內容會明定雙方履行特定權責關係的構成要件(clause element)以確保雙方權益都沒有損失、避免爭議,例如:「付款時程」條款將明定【合約金額】、【付款日期】、【付款方式】等構成要件;此外,法務人員在審閱合約時除了確認合約條款與條款構成要件內容是否有疏漏、不完備之外,在不同應用情境下需確認構成要件內容是否會影響公司權益、不符合公司規定,例如:公司針對委外軟體開發合約通常【付款方式】不會採一次性付款。
基於上述合約文本審閱架構,本技術將以必備條款→構成要件→要件情境等有著上下位階層關係來辨識與解析合約內容,相關概念示意如圖1所示。
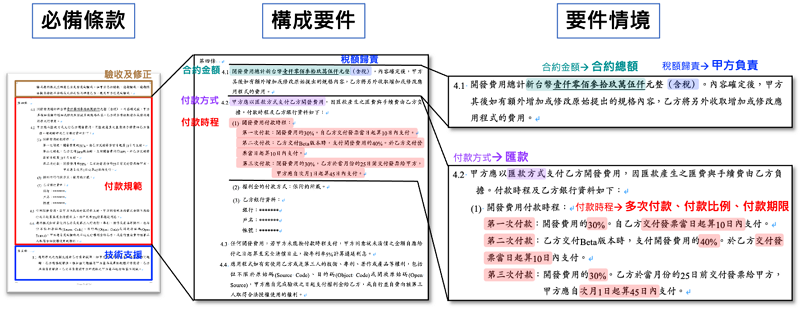
圖1 合約文本解析與辨識架構概念示意圖
當一份合約文本可透過本技術進行逐層辨識解析,將可有效協助法務人員審閱合約內容完整性、合理性與合規性,例如:
- 完整性:辨識出委外軟體開發合約缺漏「權利歸屬」條款、「保密義務」條款中缺漏【保密期間】構成要件。
- 合理性:辨識出【稅額歸責】之要件情境為乙方負責、不符以往都由甲方負責;辨識出【違約金比例】較以往高出許多。
- 合規性:辨識出【違約金規範】構成要件中未載明違約金上限、不符合公司內部規章規定不得簽署任何違約金無上限之條文。
合約智能辨識處理流程與技術
合約智能辨識處理流程
本技術以 BERT 語言模型語意理解技術為基礎,利用 BERT 在句子分類(sentence classification)、句子序列標記(sequence labeling)等兩種模型作法,將合約文本逐層進行合約條款、構成要件與要件情境解析辨識。由於 BERT 語言模型透過深度學習(deep learning)與注意力(attention)機進行自然語言上下文語境雙向學習,可以更全面理解當下詞句語意,使得其在自然語言分類與標記任務中表現卓越,例如:情感分析、文本分類、問答系統等;同時經由規模化資料預訓練後的 BERT,可進一步利用下游特定領域資料進行微調,具備可提高模型在領域任務處理的適應性和準確性。
- 必備條款辨識:利用 BERT 句子分類模型作法,以合約條款為單位,透過合約條款類別標註資料進行微調訓練(fine-tuning),模型透過學習條款內容上下文語意與條款類別關係進行必備條款類別辨識。
- 成要件辨識:利用 BERT 句子序列標記模型作法,以合約條款為單位,透過合約條款中構成要件序列標記資料進行微調訓練,模型透過學習構成要件在條款中的字符(token)序列關係進行構成要件相關文字內容辨識。
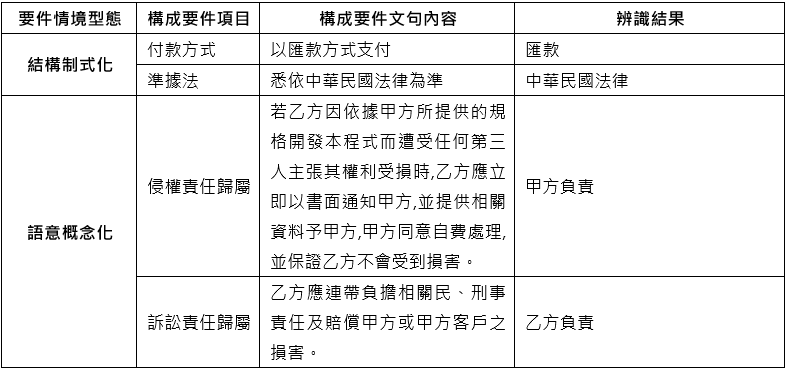
- 要件情境辨識:基於構成要件下的要件情境相當多元,有些偏結構制式化、有些則偏語意概念化,偏結構制式化情境通常句型結構與用字偏制式,可透過字串樣式匹配(pattern matching)進行辨識;偏語意概念化情境通常句型結構與文字表達方式較為複雜,則可同樣利用BERT句子分類模型作法,以構成要件文句為單位,模型透過學習文字上下文語意與情境類別的關係進行要件情境辨識。表1為兩種類型要件情境辨識範例。
表1 要件情境辨識範例
此外,必備條款與構成要件通常存在一定程度依存關係,例如:「付款規範」條款下通常會規範【合約金額】、【付款方式】、【付款時程】等構成要件、而不會規範【損害賠償責任】、【違約金】等構成要件,因此當某一條款被模型辨識為「付款規範」時,其構成要件辨識結果應該會是【合約金額】、而非【違約金】。因此本技術在處理流程上會額外利用上階辨識結果來限縮並篩選該階辨識結果之後處理步驟,以提升各層級辨識準確率,相關處理流程示意如圖2所示。
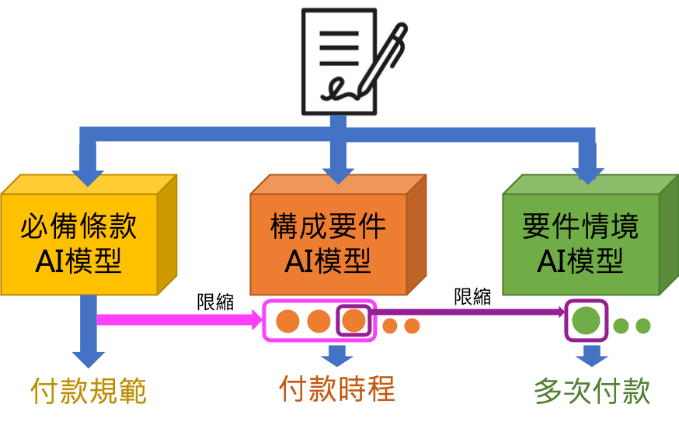
圖2 合約智能辨識處理流程示意圖
必備條款與要件情境辨識模型訓練作法
必備條款模型訓練上以合約條款為單位,透過標註合約條款類別資料進行 BERT 句子分類模型作法微調訓練,模型主要是基於 BERT 語言模型輸出層上再疊加一層類別分類器用以分類〔CLS〕類別(〔CLS〕為 BERT 語言模型之輸入字串開頭字符),當模型訓練與驗證完成後,即可針對以條款為單位的輸入資料進行取得其〔CLS〕類別資訊。同理針對偏語意概念化之要件情境則以構成要件文句作為訓練資料單位,模型訓練後同樣透過取得其〔CLS〕類別資訊來辨識其要件情境。以圖3例為某一條款輸入模型後被分類為「權利歸屬」此必備條款,而該條款中的【侵權責任歸屬】構成要件之要件情境分類結果為〔甲方負責〕。
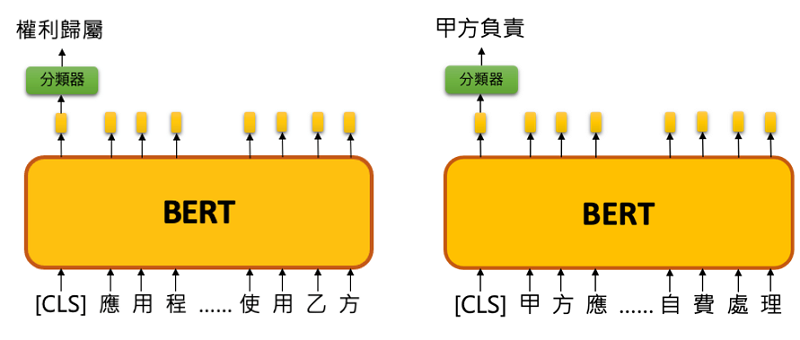
圖3 必備條款與要件情境辨識示意圖
構成要件辨識模型訓練作法
以合約條款為單位,透過標註條款中相關構成要件 BIO 序列資料進行 BERT 句子序列標記模型微調訓練,其中 B(beginning)表示該構成要件文字段落開頭字符,I(inside)表示構成要件文字段落中間字符,O(outside)表示非該構成要件字符,使得該模型具有辨識構成要件相關文字段落的能力。以「付款規範」條款中【合約金額】構成要件經標註後之 BIO 序列資料如下所示。
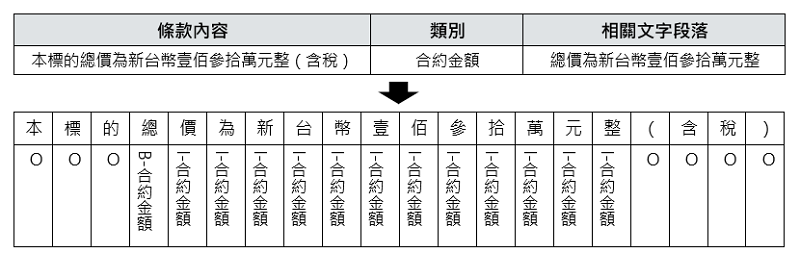
BERT 句子序列標記模型是基於 BERT 語言模型輸出層上再疊加一層用以分類各構成要件 B、I、O 分類器,當模型訓練與驗證完成後,即可針對以條款為單位的輸入資料進行逐字符作分類(各構成要件B、I及O分類),再從模型輸出的 BIO 序列結果中取出非 O 類別的文字段落。以圖4例為某一條款輸入模型後被辨識出有【合約金額】構成要件。
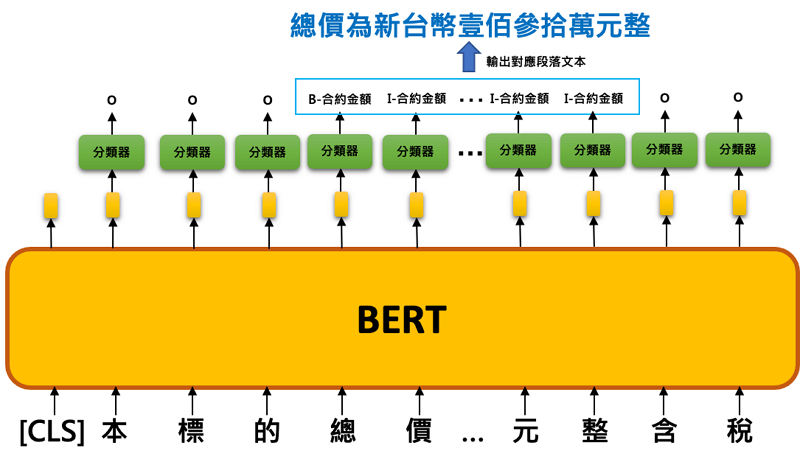
圖4 構成要件辨識示意圖
應用案例探討
應用案例背景說明
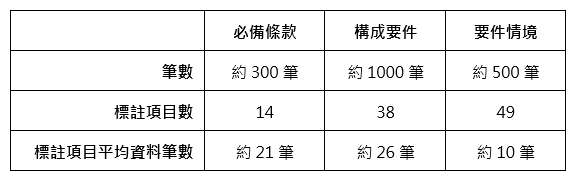
本技術透過與某一軟體資訊公司專案合作,共取得該軟體公司受委託之19份委外軟體開發合約、共307條合約條款,其中包含14項必備條款、38項構成要件及49項要件情境等標註項目,標註資料統計如表2所示。因合約標註資料蒐集不易,本應用屬於低資源自然語言處理,在辨識上有相當大的挑戰。
表2 標註資料統計表
實驗結果說明
受限於期刊篇幅,實驗結果將以構成要件辨識成果作說明與討論。以構成要件實驗結果而言,本技術整體辨識準確率為81.7%,其中文義結構不複雜、普遍性構成要件平均能夠達到90%辨識準確度,例如:表3範例所示【付款時程】、【付款方式】辨識結果均為正確;然而有些文義結構複雜構成要件辨識結果內容片段、不完整,例如:表4範例所示【合約終止規範】(底線粗體字部分)僅部分文字段落被辨識出來。
表3 構成要件辨識正確案例
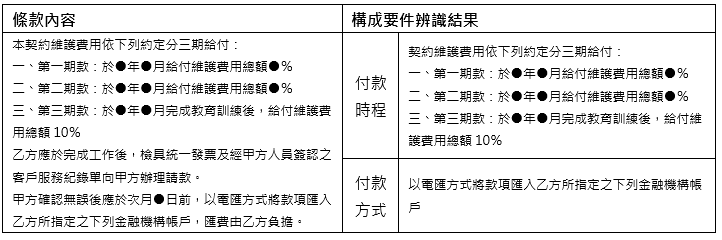
表4 構成要件辨識不完整案例
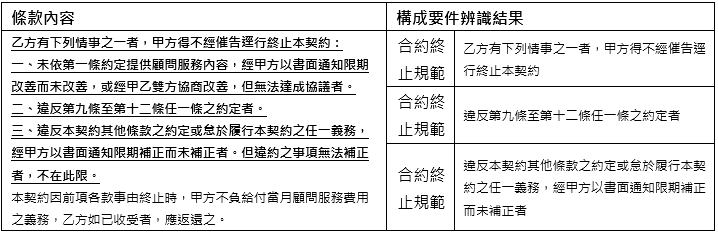
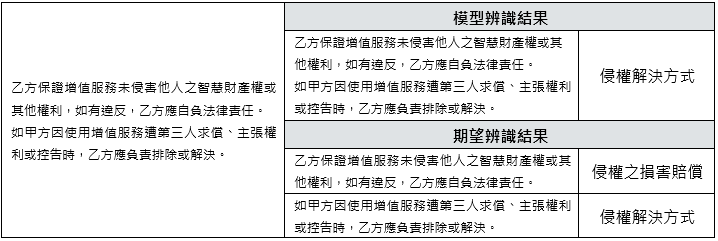
另外,較複雜構成要件在僅有少量標註資料訓練下會有語意混淆、無法正確辨識出應有的要件項目,例如:表5範例所示「權利歸屬」條款中僅辨識出【侵權解決方式】、未正確辨識出【損害賠償責任】。
表5 構成要件應辨識而未辨識案例
未來發展方向
針對構成要件辨識實驗結果,除了增加標註資料量體與提升標註資料品質(部分資料有標註標準不一)以降低語意混淆情形之外,有幾項後續可以再嘗試改善並強化的技術發展方向。
調整資料標註方式與採用QA模型
由於實驗數據中構成要件在序列資料標註時是採以句子為單位,當複雜構成要件包含多個句子時將產生多個 BIO 序列資料,應當將其整併成同一個 BIO 序列資料,讓模型可以運用到充分資訊量並學習到完整上下文關係,應可降低辨識結果內容片段、不完整之情形。另外,BERT 句子序列標記模型普遍應用於單一句子為單位之命名實體識別(NER)辨識任務上,對於合約中跨多個句子、較複雜構成要件辨識上,似乎無法整體性考量句子內以及跨句子資訊量;相對而言,問答(QA)模型作法在本質上相對能考量長段落文字整體資訊量進行辨識[3][4]、而不會拘限於單點式字符辨識,因此可以將訓練資料轉換為 Q-A 對的問答形式來進行模型訓練,應可以有效提升構成要件辨識結果完整性,例如:
Q:條文「……乙方應於完成工作後,檢具統一發票及經甲方人員簽認之客戶服務紀錄單向甲方辦理請款。….…以電匯方式將款項匯入乙方所指定之下列金融機構帳戶……」中的付款方式為何?
A:以電匯方式將款項匯入乙方所指定之下列金融機構帳戶
納入必備條款參考資訊
雖然利用必備條款辨識結果來限縮構成要件辨識範圍可以提升辨識準確度(precision),但另一方面也將受限必備條款類別辨識結果、影響構成要件召回率(recall)。在兩者利益權衡下,作法上可以改採將必備條款類別預測結果作為構成要件辨識模型預測時的參考特徵,該特徵權重於構成要件辨識模型訓練時一起被訓練,達到參考必備條款資訊來輔助辨識構成要件目的。為能納入必備條款特徵資訊,構成要件辨識模型選用上更顯得問答(QA)模型比 BERT 句子序列標記模型更有優勢,可以直觀地在 Q 句中加入必備條款資訊,例如:
Q:以下付款規範條文「……乙方應於完成工作後,檢具統一發票及經甲方人員簽認之客戶服務紀錄單向甲方辦理請款。…….以電匯方式將款項匯入乙方所指定之下列金融機構帳戶……」,則其付款方式為何?
大語言模型與生成式AI作法
自從2022年底生成式AI崛起,大語言模型(LLM)在各個領域中展現出卓越的文字語意理解與生成推論能力,對於缺乏大量標註資料而難以運用遷移學習(transfer learning)、微調預訓練模型達到理想辨識準確度的特定領域應用而言,透過提示工程(prompt engineering)與提示微調來引導大語言模型進行領域問題理解與辨識是另一突破性作法。因此以中文開源大語言模型(例如:TAIDE, Breeze)為基礎來重新調整合約辨識處理流程與作法是相當值得期待的方向,目前本技術團隊已經著手進行相關模型測試以及企業內部導入作法設計,同時將進一步搭配檢索增強生成(Retrieval-Augmented Generation, RAG)架構,除了可以有效降低大語言模型產生幻覺並增強生成結果可控性與可溯性,同時將降低需為不同合約審閱需求反覆調校辨識模型以及投入標註與確保資料品質的人力。
參考資料
[1] Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, and Ion Androutsopoulos. 2019. Neural Contract Element Extraction Revisited. In Workshop on Document Intelligence at NeurIPS 2019.
[2] Deloitte. 2020. Tech Bytes part 4: Intelligent Contract Life Cycle Management. Available at: https://www2.deloitte.com/content/dam/Deloitte/us/Documents/about-deloitte/us-about-deloitte-tech-bytes-part-4.pdf.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 4171–4186.
[4]. Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. 2020. A Unified MRC Framework for Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 5849–5859.
[5] Zihan Wang, Hongye Song, Zhaochun Ren, Pengjie Ren, Zhumin Chen, Xiaozhong Liu, Hongsong Li and Maarten de Rijke. 2021. Cross-Domain Contract Element Extraction with a Bi-directional Feedback Clause-Element Relation Network. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1003–1012.
[6] Ruixue Zhang, Wei Yang, Luyun Lin, Zhengkai Tu, Yuqing Xie, Zihang Fu, Yuhao Xie, Luchen Tan, Kun Xiong, and Jimmy Lin. 2020. Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents. arXiv preprint arXiv:2002.01861 (2020).