工業技術研究院 資訊與通訊研究所 黃泰惠

在產業實際應用時若能採用生成式AI合成逼真的含瑕疵產品影像,可改善瑕疵樣本蒐集不易的問題。
前言
近年來人工智慧技術快速成長,成為 2023年 ITRI ICT TechDay展出的重點項目。本文延續 2023 TechDay發表的AI議題,將相關技術內容進一步說明以利促進業界合作。當AI技術應用於產業時常面對資料收集標記不易,模型訓練耗費大量時間的問題。因此減少AI技術運用時所需的訓練資料量並能維持技術效能將是AI技術產業應用時必須處理的問題。本文將介紹工業技術研究院(簡稱工研院)多年來與產業合作開發瑕疵檢測應用案例所採用的少量資料學習技術與成果。
精彩內容
1. 工業視覺深度學習技術演進
2. 深度學習技術產業落地應用問題
3. 少量資料解決方案 |
工業視覺深度學習技術演進
人工智慧技術的發展起於1950年代,發展至今的73年過程當中曾有3次的興盛期,在這3次的興盛期技術發展的名稱依序為人工智慧(1950至1980年)、機器學習(1980至2010年)、深度學習(2010年至今)。近年來由於半導體積體電路製造技術進步使得可執行平行運算和具備龐大記憶體可處理大量圖像資訊的GPU卡普及化,更促成人工智慧的深度學習技術快速發展,2015年10月,AlphaGo擊敗樊麾,成為第一個在19路棋盤無讓子情況下擊敗圍棋職業棋士的電腦圍棋程式,人工智慧的發展從此引起世人的矚目,將人工智慧技術導入各行各業的真實應用領域以降低人力成本需求並增進效率成了業界努力的方向。
自2016年8月起,即與自動光學檢測業者合作開發以深度學習為基礎的塑膠電路板瑕疵檢測技術。傳統的自動光學檢測是以生產線上產品影像與標準正常影像做比對,當圖片的差異值大於預設臨界值即當作有瑕疵。在實際運作時由於可能取像位置略有誤差或是出現可接受的小瑕疵導致高的瑕疵誤報率,因此採用自動光學檢測產品的業者必須另外投入可觀的人力複檢產品。然而採用深度學習的影像分類技術,其判斷瑕疵產品的根據是影像分類器對產品影像的類別推論結果,因為深度學習的影像模型是由產品檢測人員執行瑕疵或正常的類別標記後的影像資料所訓練得到,藉由其高度的影像分類正確率的能力使得機器對產品瑕疵與否的檢測結果可以接近人為的判斷。為進一步提升深度學習的影像分類器的正確率和降低整體運算所需時間,工研院在2016年提出一種具有分支架構之類神經網路架構。
DFBN(Deeply-Fused Branchy Network)如圖1所示,有別於一般網路架構,DFBN在主要網路架構上之特定階層上加入分支子網路,每一分支子網路基本上為一分類器,每一分類器內的捲積分層總數並不相同,使得較易判斷的輸入測試樣本可以透過較少層數的網路分支運算即可取得正確的分類結果以降低整體計算時間。此DFBN架構自提出後至今已運用於印刷電路板、半導體晶片、塑膠射出件等多種產品的瑕疵檢測,均可得到合乎廠商需求的檢測效果。
圖1中的Conv1~5_x代表第1~5包含x個捲積分(convolution)層的網塊,同一網塊內的捲積分層長寬大小皆相同,輸入端網塊Conv1長寬與輸入影像相同,隨著網塊層數增加其長寬逐漸縮小,至Conv5網塊將內部每一捲積分層的元素加總後取平均(global average pooling,GAP)即得每一物件類別的分數,因此Conv5_x的x即代表此神經網路分類器(classifier)所處理的物件類別數。DFBN的架構由3個共用輸入層的分類器所組成,在每一分類器內的捲積分層總數並不相同,使得深淺不一的分類器可針對不同輸入特性的影像發揮最佳的效果。圖中的Softmax函數,或稱歸一化指數函數,它能將一個網路輸出的K維實數向量「壓縮」到另一個K維實向量中,使得每一個元素的分佈如同機率分佈範圍,且所有元素的和為1。如此的輸出向量歸一化處理可避免不同分類器結構所造成的運算傾向作用,對於融合(Fusion)3個分類器的輸出結果顯得特別重要。
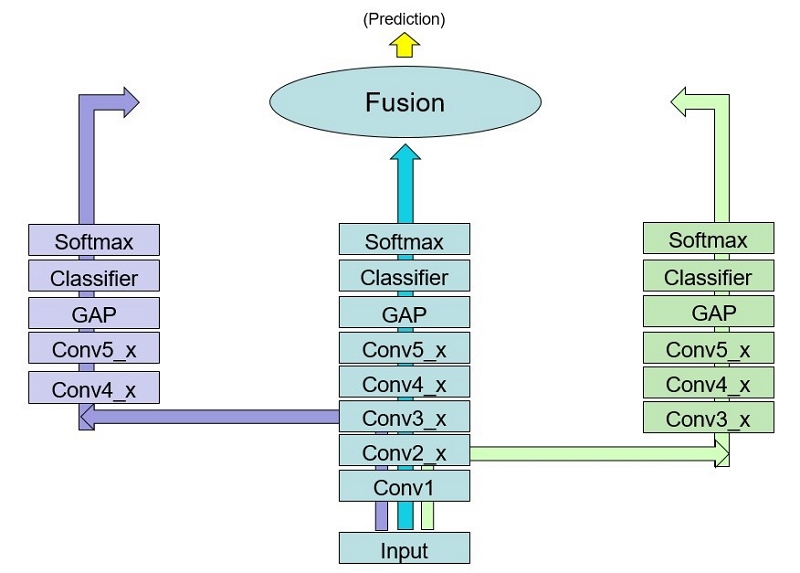
圖1具有分支子網路的DFBN網路架構
DFBN執行物件分類的正確率和執行速度超越當時國際學術界知名的wide residual networks50(WRN50),以CIFAR-100資料集的分類實驗結果來說,中間分類器為50捲積分層、左右分支網路分別為38和18捲積分層的DFBN可得到16.01%的物件分類錯誤率,WRN50的物件分類錯誤率則為17.74%。DFBN執行分類1張圖片的時間只需18.83毫秒,而WRN50則需29.39毫秒。
此外為進一步提升DFBN的影像分類正確率,工研院提出一種具有多裁剪架構之卷積神經網路(One-Pass Multi-Crop Convolutional Neural Networks,OPMC-Net)。DFBN結合OPMC-Net的網路架構如圖2所示,其在每一分支網路輸出端增加一個特徵圖多個局部裁剪切割平均(crop average pooling,CAP)值輸出的網路運算架構。將特徵圖多個局部裁剪切割產生的多個平均值向量經過原本分類器輸出端的全連接網路層(fully connected layer)運算後可得到多個類別機率向量,圖2-1所示即為多個局部裁剪中的左上部特徵圖切割運算。將這些特徵圖局部裁剪的類別機率向量經過融合(fusion)運算產生該分支網路最終的分類輸出。有別於一般多裁剪網路架構需要重複多次正向推論,及事後融合機率之繁瑣計算步驟,本OPMC-Net技術只需要1次正向推論便可完成多裁剪評估,不僅有效降低整體計算時間,且大大降低了多餘之繁瑣計算步驟,讓多裁剪評估變得簡單、易用、有效率。為證實OPMC-Net提升神經網路分類器的效果,我們以國際學術界知名的ResNet-269-v2為主軸網路結合OPMC-Net與原ResNet-269-v2進行ImageNet資料集的物件分類實驗,實驗結果如表1所示。實驗中的OPMC-Net會執行12個區域裁切,的ResNet-269-v2將輸入影像執行12個區域裁切然後分別進行物件分類,從12個分類結果中取類別機率最高者為最終結果的實驗結果如表中Baseline帶有# of crops=12那一列的數據所示,至於表中Baseline帶有# of crops=1那一列的數據則是ResNet-269-v2直接將輸入影像進行物件分類的實驗結果。表1中的實驗結果明確顯示,將輸入的測試影像進行12次區域裁切分類並從中選取類別機率最高者的分類錯誤率(18.25%)比單一輸入影像的測試錯誤率(19.71%)低,不過12次區域裁切分類所需的運算時間就是單一裁切分類運算的12倍。表1中ResNet-269-v2結合OPMC-Net的實驗結果顯示其分類錯誤率(18.18%)比ResNet-269-v2將輸入的測試影像進行12次區域裁切分類的錯誤率(18.25%)低,而且結合OPMC-Net所需的執行分類運算時間只是單一裁切分類運算的1.3倍,明顯比多次裁切和辨識輸入影像所需的時間少。
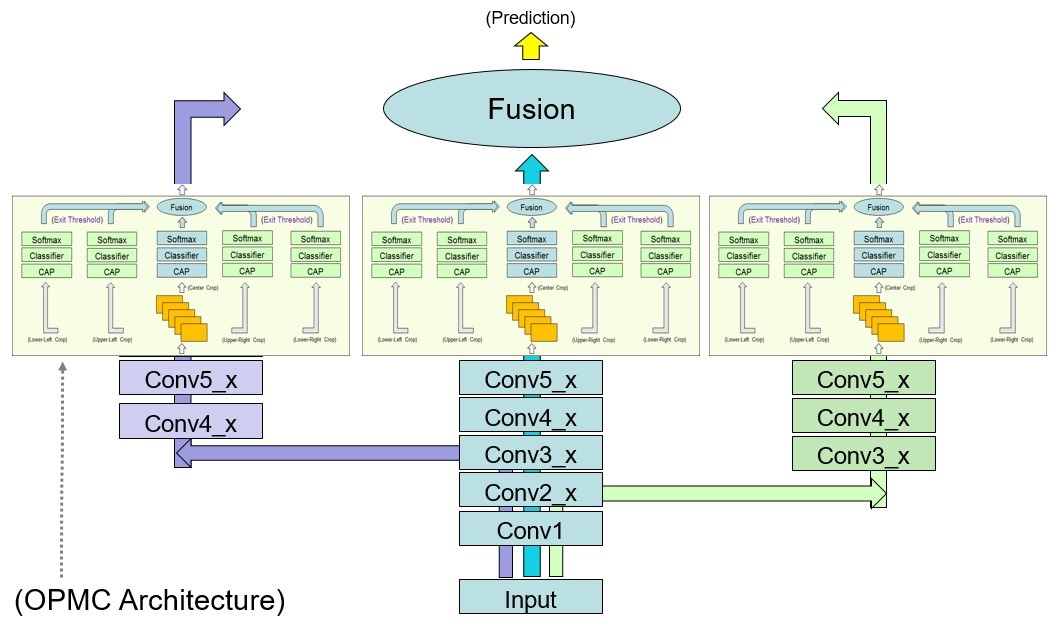
圖2 DFBN結合末端層多裁剪結構OPMC-Net的網路架構
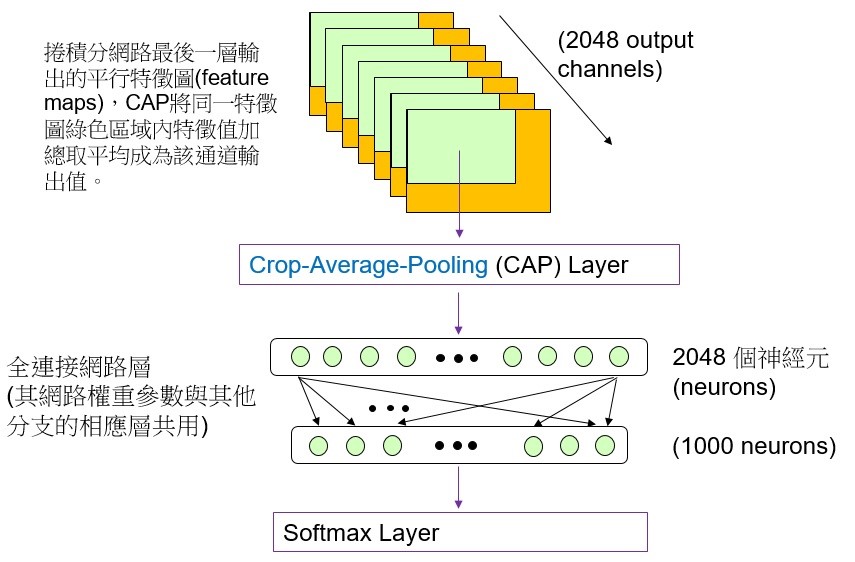
圖2-1 OPMC-Net執行左上部(綠色區域)特徵圖切割平均(CAP)和全連接網路層運算的網路架構
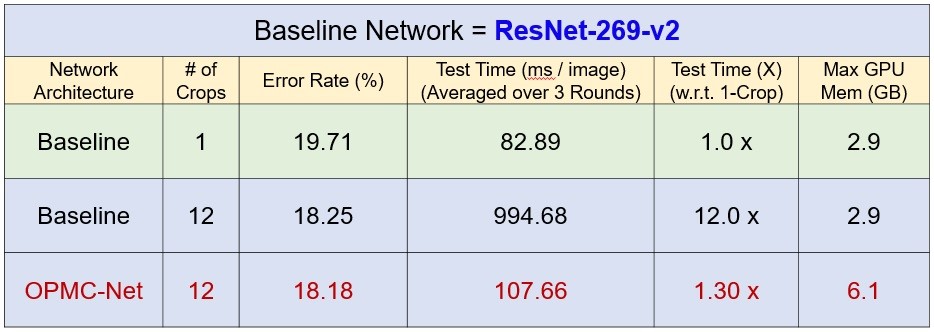
表1 以ResNet-269-v2為主軸網路結合OPMC-Net與原ResNet-269-v2在ImageNet資料集的物件分類實驗結果比較。
在工業生產過程當中,某些瑕疵類別對於產品所造成的損害特別嚴重,因此必須針對這些重大瑕疵類別,儘可能降低其漏檢率,以免因為不良品而造成巨額損失。所以在機器檢測產品過程當中,如果可以對某些特定的瑕疵類別提高其預測準確率,則能明顯減少作業人員需複檢之成本。然而,現行的神經網路架構,其預測融合之方式(例如,將各個預測值做加權平均),雖然可以降低整體之預測錯誤率,卻無法有效地解決上述之議題。為降低重要瑕疵類別之漏檢率,工研院提出一種神經網路架構在輸出預測的部份,加入特定感興趣類別之預測最大化或最小化融合機制(Multi-Class-of-Interest Maximum or Minimum Fusion,Multi-COIM fusion),只需一次正向推論便可完成多個感興趣類別的預測最大化或最小化融合評測(One-Pass Multi-COIM-Fusions),所增加的計算量非常非常少。本技術提及的最大化或最小化融合方法是指從網路中的多個分支結果選取融合對象的所採用的依據,其設計的目的是COIMax降低感興趣瑕疵的漏檢率和COIMin提升感興趣類別的判斷精準度。已經訓練好之神經網路模型參數,可直接套用本技術,無需再調整。以DFBN為主要架構結合OPMC和Multi-COIMax-Fusions的網路結構如圖3所示。實驗結果顯示,採用6 Crops的Multi-COIMax Fusions 技術的DRAM晶片瑕疵檢測可以把業者認為的重大瑕疵scratch(刮痕)漏檢率從1.89%降低至0.47%。採用6 Crops的Multi-COIMax Fusions技術可以把瑕疵類別判斷的精準度從97.95%增進至99.16%。
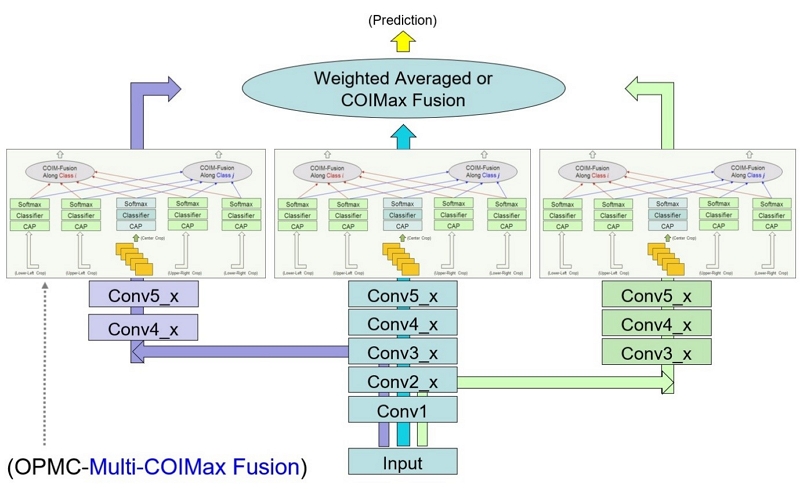
圖3 DFBN為主要架構結合OPMC和Multi-COIMax-Fusions的網路結構
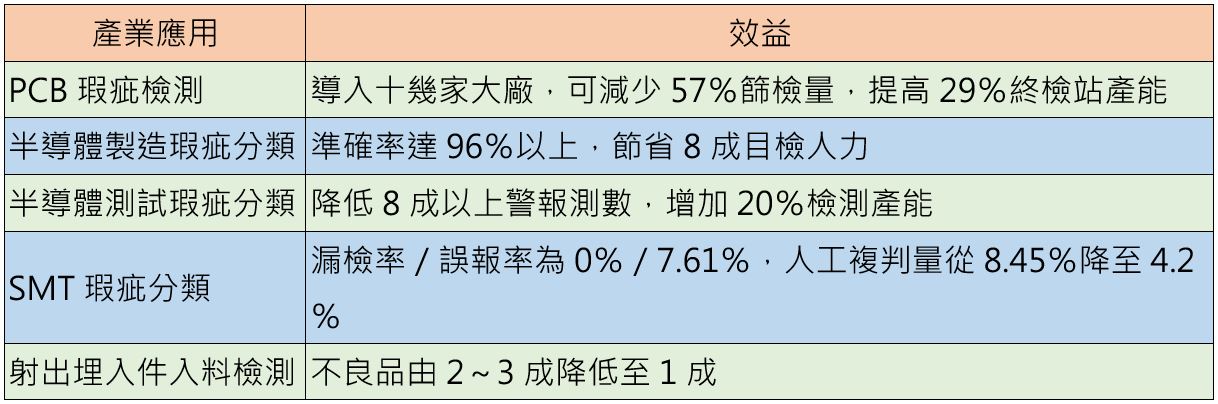
前文提及的工業產品瑕疵檢測技術已取得國內外多項專利並已應用於國內多家產業,產生的效益如表2所示。此外這些AI技術也曾擴散應用於工安防護衣視訊監控,其目標是辨識人員作業中是否正確穿戴防護設備,廠商實際應用後結果顯示辨識準確率超過90%。
表2 工研院工業產品瑕疵檢測技術的實際運用範圍和產出的效益
深度學習技術產業落地應用問題
深度學習技術雖然可以產生高於以往機器學習技術的性能,然而剛開始發展的深度學習技術通常需要大量有正確標記的模型訓練資料。蒐集大量的產線上產品影像資料需要時間,取得資料之後還須人員進行整理和標記,然後進行模型訓練。在完成以上步驟之前人工智慧的瑕疵檢測無法進行,而且業者須投入相當的人力執行上述工作。如果產線上更換製造新的產品,例如不同設計的電路板,則需重新進行前述資料蒐集、整理、標記和模型訓練工作,不然舊產品的影像模型無法正確判斷新產品的影像是否含有瑕疵。因此深度學習技術若一定需要大量有標記的資料才能訓練模型以維持高準確率的話,將成為產業落地應用的問題。
少量資料解決方案
為降低深度學習技術對大量有標記的資料的倚賴,學術界已提出遷移學習(Transfer learning)、主動式學習(Active learning)、半監督學習(Semi-supervised learning)、和以人工智慧合成圖為訓練資料擴增(Generative artificial intelligence for training data augmentation)等方法以達到少量資料學習但能維持高準確率的目的。工研院也以DFBN為基礎搭配前述少量資料學習方法開發出瑕疵檢測技術以增進合作廠商採用的意願。
遷移學習與自監督學習訓練預訓練模型
遷移學習(transfer learning)就是把已經訓練好的模型或稱之為預訓練模型(pretrained model)、參數,轉移至另外的一個新目標領域(target domain)的模型上,其優點是可以用較少的新領域有標記資料得到新領域測試資料高準確率的模型。前述已經訓練好模型的資料特性若是與新目標領域的特性接近,則所需的新領域有標記訓練資料可以較少。以印刷電路板瑕疵檢測的例子來說,以先前印刷電路板模型當作訓練新印刷電路板模型的預訓練模型,其所需訓練資料量可以比自然影像資料(例如ImageNet)模型當預訓練模型的少很多。為確保預訓練模型所代表的影像資料特性可以包含新印刷電路板的,通常會使用先前的大量電路板影像當作訓練資料。若這些大量資料無標記,則可採用自監督式對比學習(Contrastive Learning)方法訓練此預訓練模型以省下資料標記的負擔。
主動學習
有近似領域的預訓練模型之後進行新領域資料的遷移學習時若採用主動學習(active learning)方法從新領域資料中挑選訓練資料可比隨機挑選的產生更高準確率的模型。主動學習是一種循環式的步驟如圖4所示,開始時先從未標記的資料中隨機抽取少量資料進行標記然後進行遷移學習的模型訓練。使用所得到的模型對所有未標記資料進行測試,然後觀察這些資料測試後輸出的類別機率值,產生最高與次高機率差值低於預設閥值的資料表示目前的模型對於該資料的分辨能力不夠,所以下一階段應該把它們加入訓練資料以提升分辨該類資料能力。除了以最高與次高機率差值的判斷方法外,也可以用輸出機率值分佈的熵值是否低於預設閥值來判斷是否選取該資料供專家標記。如此的資料選取、人員標記、模型訓練、測試未標記資料的循環經過數次後,可以觀察到選取的資料量逐次變少而產生的模型對有標記的驗證資料(validation data)的分辨正確率則逐次變高。當驗證資料的分辨正確率高於期望值後即可停止主動學習。因為主動學習透過逐次選取模型缺乏的新資訊,所以最後累計的總標記數量可以比隨機抽選訓練資料的少,而且以累積的經驗,主動學習訓練的模型可以得到較高的瑕疵影像分類正確率。
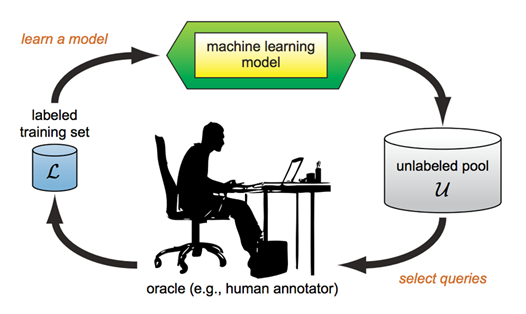
圖4主動學習過程的循環步驟
半監督學習
半監督式學習(semi-supervised learning,SSL)技術即是利用少量標記資料及大量未標記資料訓練模型,藉以達到大幅減少標記資料量的目的,同時又能兼顧產業應用所需的模型準確率。目前最先進(state-of-the-art,SOTA)的半監督式學習技術,例如NeurIPS-2020被高度引用的FixMatch與非監督式領域調適(unsupervised domain adaptation,UDA)2種方法,透過整合虛擬標記(pseudo labeling)與一致性調整法(consistency regularization),在自然影像資料(ImageNet、CIFAR-10/100)上達到很好的分類效果。然而由於垂直領域資料(例如:工業視覺影像、醫學影像)的細微特徵差異及資料類別數量嚴重不均等問題,導致SOTA的半監督式學習技術難以發揮預期效果,因此亟需發展可適用於垂直領域資料的半監督式學習技術,以促進產業應用深度學習技術提升競爭力。為此提出一種基於神經網路模型預標記適應性校驗(AdaMatch)[1]之半監督式學習技術,利用少量標記資料及大量未標記資料訓練模型,藉以達到大幅減少標記資料量的目的,同時又能兼顧產業應用所需的模型準確率。工研院提出基於AdaMatch方法的3階段半監督式學習架構(3-Stage SSL Framework),AdaMatch相較於SOTA的方法,能在垂直領域資料(例如:工業視覺影像)的細微特徵差異及資料類別數量嚴重不均等問題下,達到更高的分類正確率及更有效率的樣本選取標記策略。其特點是針對未標記資料於訓練過程中,以模型輸出機率值是否超過給定的閥值和模型輸出的標記是否匹配模型輸入預標記,以此決定是否用此樣本的資訊做模型參數更新。
生成式AI瑕疵影像生成
在產業實際應用時所蒐集到的瑕疵樣本通常較少,因此可能影響模型訓練後的準確率。如果可以採用生成式AI合成逼真的含瑕疵產品影像,應該可以改善瑕疵樣本蒐集不易的問題。生成式AI的擴散模型(diffusion model)為目前人工智慧生成高品質圖片的主流方法,最近在文獻上已經可以看到塞梅維斯大學醫學院用diffusion model所生成的皮膚病例圖結合真圖訓練皮膚病分類模型的實驗結果[2]。另外也有一篇文獻發表用diffusion model生成含瑕疵的繩索產品影像做為訓練模型的資料擴增方法[3],其實驗結果顯示75%的訓練資料用diffusion model合成圖取代後仍能維持原圖模型的分類結果。工研院參考前述文獻方法也採用diffusion model來生成PCB瑕疵分類的模型訓練資料。合成圖片的方式有「以圖生圖」和「以文生圖」2種,以圖生圖是由給定的參考圖當作合成時的限定條件,所產生圖的跟參考圖的變異較小,通常是維持背景但瑕疵的樣態有變化或消失,此變化大小的程度可由調整合成程式中的denoising strength參數做改變。以文生圖則是由給定的提示詞(text prompt)為合成時的限定條件,所產生圖的背景和瑕疵會有較大的變化。運用PCB合成實驗產生的圖例如圖5所示。不過因為有可能產生背離PCB資料特性的合成圖或是如前所述的瑕疵消失或瑕疵類別改變的現象,所以產出的合成圖必須經人員或程式檢查篩選步驟才能當模型訓練資料用。我們目前結合原圖和合成圖的瑕疵分類實驗結果顯示,分類錯誤率減少比例可達20%,證實diffusion model合成技術有助於提升工業產品的人工智慧瑕疵檢測效能。
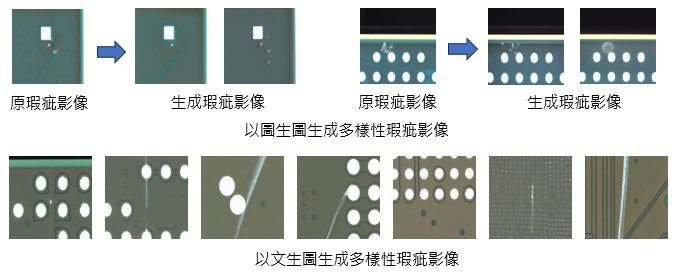
圖5 使用stable diffusion model產生含瑕疵的PCB圖片
結論
工研院經過7年來的努力,從提出適合工業產品瑕疵檢測的DFBN網路架構、並因應廠商降低瑕疵漏檢率需求提出深度學習網路改良技術(OPMC與Multi-COIM fusion)。為減少深度學習所需的標記資料量,採用自監督學習訓練預訓練模型的主動學習挑選關鍵的模型訓練資料,提出基於AdaMatch方法的3階段半監督式學習架構(3-Stage SSL Framework),和以生成式人工智慧合成含瑕疵的工業產品影像達成資料擴增。藉由這些方法使得少量資料也能發展AI,讓國內產業能廣泛運用AI技術而提升國際競爭力。近年來工研院也投入生成式AI技術開發,相關技術除了應用於本文中提及的產品瑕疵影像生成外,還有賀卡生成系統、主播表情及姿態生成技術、和輔助產品設計等應用。除了前述影像生成應用外,工研院也開發程式碼生成的AI技術,目標是合成積體電路設計的verilog程式碼以縮短廠商晶片開發設計所需的時間。
參考文獻
[1] David Berthelot, Rebecca Roelofs, Kihyuk Sohn, Nicholas Carlini, Alex Kurakin, "AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation", ICLR 2022
[2] Mohamed Akrout, etal., "Diffusion-based Data Augmentation for Skin Disease Classification: Impact Across Original Medical Datasets to Fully Synthetic Images", Arxiv 2023
[3] Ortiz-Arroyo, Daniel; Durdevic, Petar, "Effective Generative Data Augmentation in Condition Monitoring", TechRxiv 2023. Preprint. Available at: https://doi.org/10.36227/techrxiv.24024522.v1