工研院資通所 林良憲、張予潔、蔡煥文、林宏偉、王莉珮、蔡昀翰
 公版工業物聯網平台讓台灣業者能輕鬆接上工業4.0所需要的所有最新技術,達到互助互利的產業生態。
公版工業物聯網平台讓台灣業者能輕鬆接上工業4.0所需要的所有最新技術,達到互助互利的產業生態。隨著城市的發展,環境建設及基礎設施規模不斷擴大,人們對於生活便利性及豐富性的要求也越來越高,因此近幾年智慧城市一直是被討論的熱門話題,出現了許多與智慧城市相關的創新概念與應用,如智慧家庭、智慧交通、智慧健康、智慧零售、智慧工廠…等,這些應用的背後則仰賴於許多的智慧裝置及大量資料的處理與分析。但是問題來了:多樣的智慧裝置從何而來?該如何有效處理每日產生大量的資料?傳統的工廠擅長「量產」,傳統的產線若不「更有智慧」將無法因應未來多樣甚至少量客製化的市場需求;工廠內產生的大量累積資料如不加以儲存、管理與應用,就無法即時掌握工廠運作狀態,連帶無法有效提升產能。台灣業者近年來莫不以提升成工業4.0等級為目標而努力,但各自努力的結果卻是小工廠做不來,大工廠疲於奔命。為了避免資源分散消耗,在政府政策支持下,法人研發公版工業物聯網平台(National IoT PaaS, NIP),讓台灣業者能輕鬆接上工業4.0所需要的所有最新技術。透過NIP,資訊服務業者除了可以省力地為工廠開發運行在NIP上的軟體,更可以SaaS方式銷售軟體或服務給其它廠商,達成互助互利的產業生態。
工業4.0與工業物聯網
1. 工業4.0為工業發展必然趨勢
「小明是一位工廠老闆,為消化每日大量的訂單,以前的他每天總是疲於應付機台設備不預期的停機、材料供應不足、產線臨時調整等各種狀況。但在導入工業物聯網技術後,他可以完全且即時的掌握機台健康資訊、設備保養排程、材料庫存,產線調整也只是彈指間的事,使得處理訂單的效率大幅提升,也為公司創造了更多利潤。為了面對未來的產業競爭,現在的他可以有更多心思在產線優化、售後服務加值與行銷模式整合的思考與轉型上,帶領公司更上一層樓。」 上述或許是未來國內工廠將會發生的情境,而其間的種種技術也確實正在發生。全球工業發展至今為止歷經了四次創新性的革命,第一次工業革命始於瓦特改良蒸汽機,人類首次實現機械化工廠,以機械化生產取代人力及畜力;第二次工業革命是在電力的廣泛應用及內燃機的發明下,人類開始以電力取代蒸氣,標準化生產線型態出現使商品得以大量製造;第三次工業革命則隨著電腦及電子資料的普及下,使生產製造邁向數位化、自動化,大幅提升生產效率與品質;第四次工業革命,即「工業4.0」,隨著虛實整合、人工智慧、大數據、物聯網技術的發展與突破,儼然成為未來工業發展的必然趨勢,能跟上此趨勢的產業將持續活躍,否則將面臨被淘汰的命運。IBM也認為,工業4.0是邁向未來製造必經的旅程,企業應依自己的策略目標選擇階段性實踐方案。其中,智慧化連結所有生產設備與系統,建立雲端與大數據平台,運用自動化控制來管理相關的設備及生產流程,達到工廠或企業內優化是第一步。
2. 構成工業4.0的核心基礎-工業物聯網技術
工業4.0的精神並非以機器取代人力,而是透過人機協同走向智慧生產,實現智慧工廠的概念。Frost&Sullivan(Frost&Sullivan, 2017)報告指出,在未來的智慧工廠中,設備間透過工業物聯網,可彼此對話,並相互分享資料,使企業能夠利用現代自動化控制系統提供大量的數據,為現場操作人員提供遠程監控、診斷和設備管理的功能,即使分散在各地不同的工廠也能強化數據收集以提供更佳的解決方法;此外,亦可即時反應設備健康狀況,減少配置和調整的精力跟時間,並大幅度減少現場故障排除的需求,更有效率的在線提供新的生產線或設施,以及改善跨公司間不同設備之協同合作。換言之,將生產設備及感測資料聯網,透過工業物聯網平台儲存與管理資料,並藉由人工智慧科技,運用平台的巨量資料開發智慧加值應用(如設備預兆診斷、製程參數優化、最佳化彈性排程等),優化產能,滿足大量客製化需求,是企業導入工業4.0必須積極採用的解決方案。
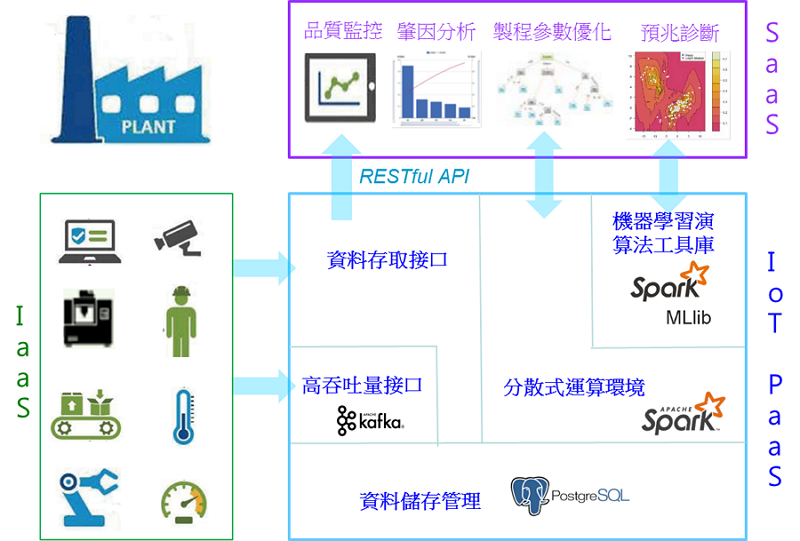 圖1 智慧製造資訊階層架構
圖1 智慧製造資訊階層架構3. 工業物聯網國際解決方案
分析目前國際大廠在工業物聯網平台的解決方案,主要有Microsoft Azure IoT(Microsoft, 2018)、IBM Bluemix(IBM, 2018)、西門子MindSphere(Siemens, 2017)等。Azure是微軟的公用雲端服務(Public Cloud Service)平台,也是微軟線上服務(Microsoft Online Services)的一部份,提供雲端、物聯網與巨量資料等所需的各類型服務;Bluemix是由IBM所開發的開放雲端平台,目的是提供開發者一個方便、快速設計的平台,同時也讓企業可以更好的整合各種不同的平台服務,Bluemix提供各式各樣的雲端服務與API,也包含各種虛擬機器及資料庫;MindSphere是西門子推出的開放式物聯網雲端平台,可實現虛實世界的連結,並提供強大的工業應用與數位服務以促成商業成功。此外,MindSphere的開放式平台即服務(Platform as a service, PaaS)可建立豐富的合作夥伴生態系統,以供開發並提供新的應用。
4. 國內產業缺口及政府政策
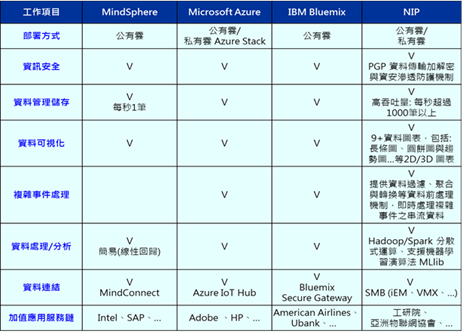
在全球人口老化、缺工的情況下,各國紛紛投入工業4.0轉型,走向智慧化生產的趨勢。台灣產業雖擁有硬體製造與組裝代工優勢,但長期多專注於硬體的效能升級,在軟體應用上創新能力卻相對不足,且國內製造業多採用客製化且封閉式的開發系統,無法與其他業者發揮協同運作之效益。再者,各種工業物聯網應用系統或平台要達到互通互聯,技術上仍有待突破,且國內製造業大多為中小企業,普遍處於工業機械化到自動化的階段,多數無自行建置先進製程管理平台之能力及資源,導入IT化之門檻相對也高,在製造過程中因缺乏共通性平台做整合,導致生產效率不佳。因此,政府推動智慧機械產業推動方案(行政院, 2015),以精密機械之推動成果及我國資通訊科技能量為基礎,導入智慧化相關技術,建構智慧機械產業新生態體系,藉由整合智慧技術,使機械設備具備故障預測、精度補償、自動參數設定等智慧化功能,使我國機械設備業者具備提供完整解決方案之能力。 分析前述國際大廠解決方案,除微軟發展出Azure Stack私有雲部署方案之外,IBM及西門子僅提供公有雲服務方案,讓終端用戶以租用其雲平台方式將資料上傳到公有雲平台。公有雲平台解決方案在產業應用有兩個大問題:1.資料隱私性、2.資料上傳頻率低,故儘管資訊安全做得再好,國內製造廠商大多不願意讓工廠生產過程的機台敏感資料離開公司;此外,國內金屬加工產業設備上常用到的加速規(Accelerometer)資料,其資料取樣頻率高達10Khz~100Khz,這是公有雲服務方式無法支援的資料上傳頻率。因此,在政府政策的支持下,由法人建立之國產公版聯網平台(National IIoT PaaS, NIP)應運而生,提供國內產業一技術自主且在地化的工業物聯網解決方案。下表1為國際大廠與NIP之綜合比較,除各平台皆需考量之資訊安全、資料管理儲存、資料可視化工具、事件處理引擎、資料處理與分析必備功能大家都有各自方案之外,NIP著眼於上述國際大廠解決方案無法滿足國內製造業在資料隱私性及高頻資料上傳需求,發展供廠商選擇之私有雲與公有雲部署彈性解決方案,並研發高吞吐量接口,可支援加速規高取樣頻率資料的上傳與儲存,解決IBM、Siemens等只提供公有雲服務方案的問題,並提供國內業者除微軟外的另一種選擇,雖不及國際大廠的知名度,但因採用開源方案,可降低中小企業建置與維運成本。
表1 國際大廠與NIP之綜合比較
NIP主要研發技術
以下就NIP目前建立之三項主要研發技術簡述如下:
1. 高吞吐資料傳輸技術
由於工廠生產機台的製程參數與感測設備具備大規模與高速等資料傳輸的特性,如馬達震動訊號產生頻率約100K筆/秒、中大型廠區機台約100~550台不等的資料同時上傳的規模,為符合工廠感測設備或生產機台巨量、高頻率的資料傳輸目的,NIP提供PUB/SUB的高頻資料傳輸通道與方法,以滿足現階段工廠高速、大規模資料的傳輸需求。
2. 巨量資料運算技術
工廠生產機台蒐集累積的製程與感測歷史資料量過大,一般PC受限於CPU與Memory的物理限制,無法快速處理巨量資料。NIP利用開源Spark分散式運算處理框架,解決單台電腦的物理限制問題。因此,當工廠端需要分析處理大量的製程與感測歷史資料時,可透過Spark分散式平行化處理資料,加速資料處理速度,同時也解決原始單機硬體規格不足的限制。 Apache Spark是個可擴充性的分散式資料處理平台,其數據計算於叢集記憶體中執行,因此運算速度相較於傳統在硬碟中運算的Hadoop MapReduce(Apache Hadoop, 2018)更為快速,研究結果顯示,Spark在記憶體叢集運算比Hadoop在硬碟叢集運算快100倍。Spark在處理巨量資料分散式運算時,除了可串聯多台電腦成為一個巨大的Spark Cluster擴充運算硬體規格外,Spark也會將大量的資料切成小份,並將這些小份資料分別派給叢集中不同核心(CPU core)執行,待各叢集核心將所有資料執行完畢後,再匯總成最後的結果輸出。
3. 機器學習演算法
NIP平台為SaaS開發者提供一個分散式建構學習模型的執行環境,使用開源社群的資料分散式運算處理框架Apache Spark(Apache, 2018)與叢集(clusters)資源管理Apache Mesos (Kakadia, 2015)建構一個以分散式運算為基礎的架構,使開發者在巨量資料的情況下,可快速地建構資料學習模型,其中Spark MLlib(MLlib, 2018)提供機器學習工具庫,而Mesos優點在於其資源管理介面可幫助開發者清楚了解其指派的運算工作排程等。Spark框架提供的Spark MLlib函式庫包含分類模型、迴歸模型與群集模型,其中分類模型如決策樹(Decision Tree),迴歸模型如線性回歸(Linear Regression)以及群集模型如k-均值分群(k-means clustering)等多種機器學習演算法,讓SaaS開發者可選擇以Scala、Java或Python等三種語言,另以API函數方式呼叫演算法,如此一來讓開發者可更容易更有效率地建構資料學習模型,並提供三種慣用語言,供使用者選擇。此外,Spark MLlib提供部分統計計算以及擷取、轉換和載入(Extract-Transform-Load, ETL)等功能函數,讓開發者可以分散式運算為基礎進行資料前置處理,例如:統計學的摘要統計(summary statistics)或最小最大值(Min-Max)轉換函數。
應用案例
NIP平台的各項技術,可視情境需求整合運用,也可單獨處理個別單一問題,以下就不同產業應用實例,分別演示NIP各技術應用情境。
1. 工具機主軸馬達資料傳輸
以工具機主軸馬達加速規震動訊號為例,震動加速規產生頻率約10K筆/秒,由於標準OPC UA( OPC Foundation, 2006)與SECS/GEM(Huang E, Cheng F-T, & Yang H-C. 1999)資料傳輸頻率約1筆/秒,無法承載此類高頻震動訊號資料的傳輸需求。NIP的高吞吐資料傳輸技術提供分散式資料傳輸通道,由多個資料仲介同時且獨立接取前端工廠生產機台或感測設備資料的上傳,SaaS資料運用端如可視化網頁應用服務或資料分析應用程式可透過平行化或分散式的資料存取架構,同時向多個資料仲介取得機台與感測設備資料,提升整體NIP資料遞送與接收的吞吐效能,除了傳輸吞吐量效能提升之外,NIP分散資料傳輸架構設計也確保NIP平台系統的可靠度與延展性,資料傳輸仲介彼此之間透過相互的備援與資料備份的機制,達成NIP系統平台的高服務層級(Service Level Agreement, SLA)與高可用性(High Availability, HA)目標。透過加速規震動訊號案例的驗證與淬煉,在平行資料傳輸架構下,單一NIP資料傳輸仲介即可承載平均104K筆/秒資料傳輸吞吐量與每筆約12.28ms的低資料延遲時間,如圖1所示,解決目前國際標準OPC UA或SECS/GEM資料傳輸瓶頸,於NIP平台系統的承載規模上,單一資料傳輸仲介可同時支撐108個感測設備或機台以10K筆/秒(100 Bytes/筆的資料大小)的資料上傳速率,為中大型工廠規模的機台巨量資料傳輸提供一完整的解決方案。
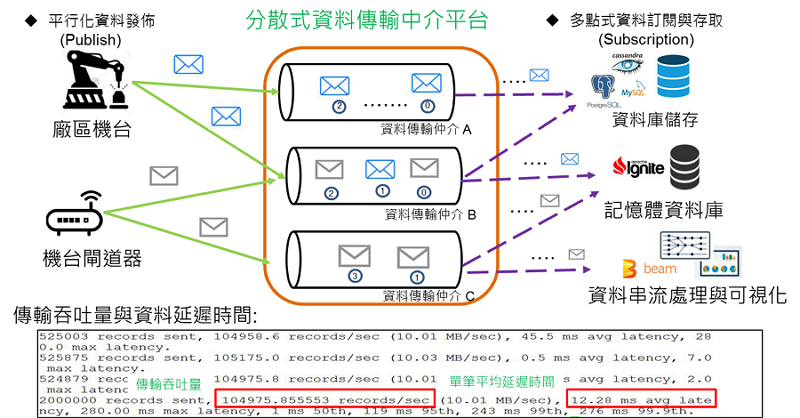 圖2 分散式資料傳輸仲介平台
圖2 分散式資料傳輸仲介平台2. 製造業資料庫存取分析
印刷電路板工廠製造端每天都有大量的製程與感測資料蒐集並儲存於資料庫中,長時間累積後資料庫資料量過大,當需要擷取部分資料分析時,無法快速查詢所需分析的資料。透過Spark分散式平行化運算平台,可加速查詢資料庫的時間,經實測如下圖2所示。傳統資料庫查詢只用單一執行序讀取資料庫,並非用多個執行序平行讀取,導致讀取大量資料時,需要耗費長時間等待結果。NIP不同於傳統單一執行序查詢資料庫,Spark在讀取資料庫時,會先將欲讀取的data table切成多份小份資料,並利用Spark叢集中多個核心進行多執行序平行查詢,加速查詢速度。考量作業人員對Spark使用不易,NIP提供簡易的查詢介面,供工廠端資料分析人員查詢資料庫。分析人員只需要輸入一般的ANSI SQL語法與資料庫相關的設定,資料查詢Rest API會利用Spark將table分割並平行查詢,並且在查詢後將資料寫成csv格式,最終將多個csv檔案彙總至hdfs,回傳hdfs link供資料分析人員下載使用,此巨量資料運算方法為工廠端提供巨量資料撈取及運算的完整解決方案。
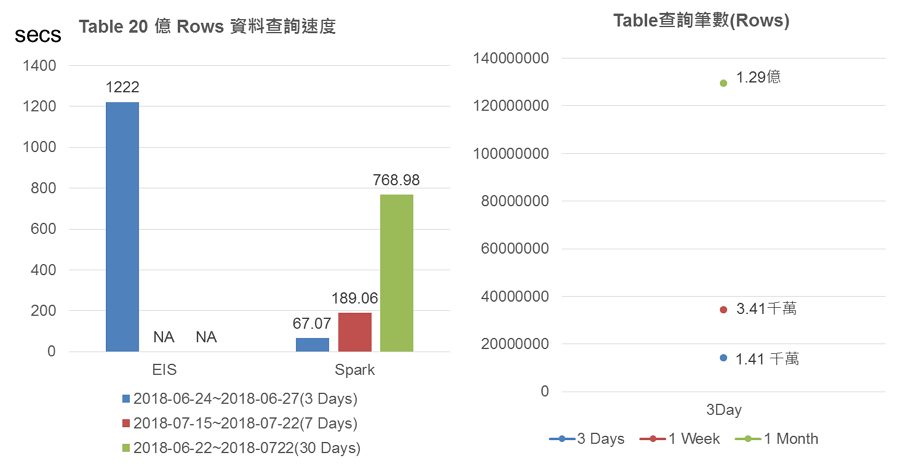 圖3 傳統資料庫讀取速度與spark讀取速度比較表
圖3 傳統資料庫讀取速度與spark讀取速度比較表3. 水情大數據運算模型環境建置
全台各水庫的資料隨著時間的經年累積,資料庫的資料數量已經增加至千萬筆紀錄值(record),當以如此巨量的歷史資料進行水情預測模型建構時,往往需等待較長的時間。然台灣的梅雨季節或是颱風較多的7~9月,模型的建構與水庫水量的預測時間必須在很短的時間內完成,讓政府可及時通知民眾水庫未來幾個小時內可能發生的狀況,進而避免民眾的財產損失。針對此問題,NIP系統提供的Spark框架可幫助開發者以分散式方式處理巨量資料並可快速建構資料學習模型用於水情之預測,並使用深度學習演算法如卷積神經網路(Convolutional Neural Networks, CNN)可提升水情預測模型的學習準確性,而此種演算法將會需要更多的運算時間。對此,NIP系統整合深度學習演算法的工具Tensorflow (Abadi et al., 2016)至Spark框架上,讓開發者可以分散式框架進行神經元(neuro)的運算,進而提升運算的效率。除了前文提及的Spark Mllib函式庫與Tensorflow可運行於Spark的分散式運算框架下,本NIP系統提供Stanford CoreNLP wrapper (Manning et al., 2014)與Genetic Algorithm (Mitchell, 1998),如圖3。
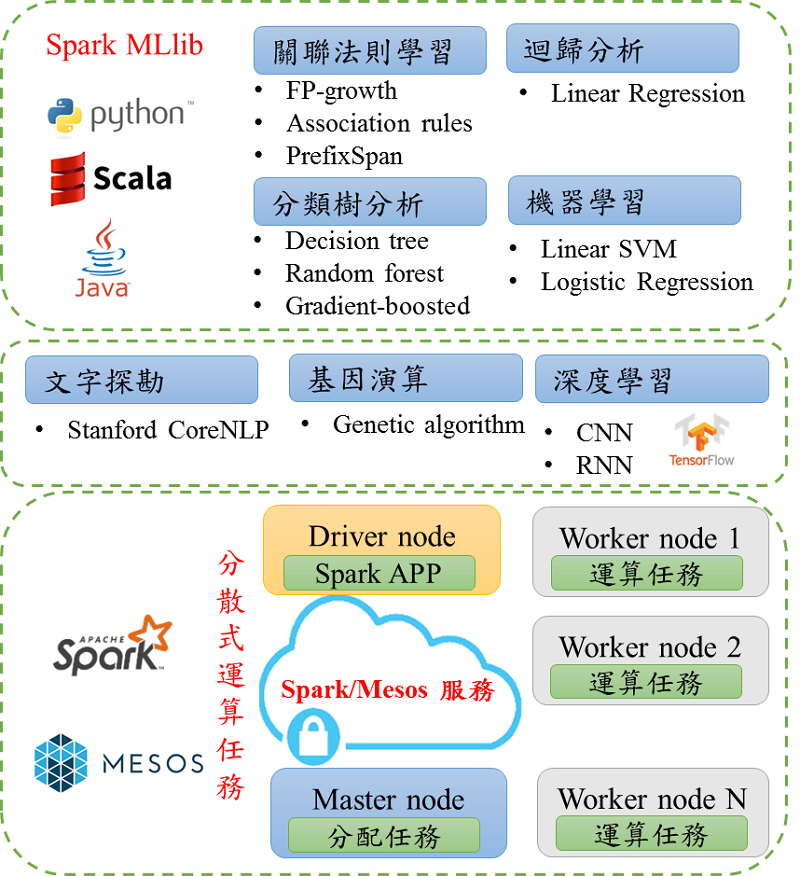 圖4 大數據運算模型函式庫
圖4 大數據運算模型函式庫NIP平台係國家智慧機械推動重點政策,乃針對國內產業所需而發展,具備高吞吐量資料接口、巨量資料儲存與即時運算分析及機器學習函式庫等功能,並具備標準化RESTful APIs,方便在地資服業者開發智能化應用,提升資服業者物聯網資料加值應用服務開發效率,降低終端用戶平台導入維運成本,為一適合跨廠區、整廠、整線設備導入之國產化聯網應用開發平台。台灣產業過去累積出十分完整的硬體優勢,包括全面的製造核心能力和垂直分工的產業供應鏈群聚,然而過去二十幾年台灣在網路經濟的發展過程中並未佔有競爭優勢,仍以傳統硬體為導向的產業思維,在全球新興產業發展脈絡中優勢逐漸弱化,因此台灣產業需把握以軟硬整合為主的物聯網趨勢,方能創造產業新價值。
參考文獻
[1] 智慧機械產業推動方案規劃,[Online].Available: https://www.ey.gov.tw/Page/448DE008087A1971/e6039c49-74ee-45a5-9858-bf01bb95dc76
[2] Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., . . . Isard, M. (2016). Tensorflow: a system for large-scale machine learning. Paper presented at the OSDI.
[3] Apache Spark [Online].Available: https://spark.apache.org/
[4] Apache Spark [Online].Available: https://en.wikipedia.org/wiki/Apache_Spark
[5] Apache. (2018). Spark. [Online].Available: https://spark.apache.org/docs/latest/index.html
[6] Apache Hadoop [Online].Available: https://hadoop.apache.org/
[7] Huang E, Cheng F-T, Yang H-C. Development of a collaborative and event-driver supply chain information system using mobile object technology. Proceedings of 1999 IEEE International Conference on Robotics and Automation, Detroit, MI, May 1999, pp. 1776–81.
[8] https://www.cw.com.tw/article/article.action?id=5068197
[9] IBM Cloud [Online].Available: https://www.ibm.com/cloud-computing/bluemix/zh-hant
[10] IBM developerWorks[Online].Available: https://www.ibm.com/developerworks/cn/websphere/bpmjournal/0812_boughannam/0812_boughannam.html
[11] IIoT Driving Manufacturing Innovations. September 2017. [Online].Available: http://www.frost.com/sublib/display-report.do?id=D7D4-01-00-00-00
[12] Kakadia, D. (2015). Apache Mesos Essentials: Packt Publishing Ltd.
[13] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Paper presented at the Advances in neural information processing systems.
[14] Manning, C., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S., & McClosky, D. (2014). The Stanford CoreNLP natural language processing toolkit. Paper presented at the Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations.
[15] Microsoft Azure[Online].Available: https://azure.microsoft.com/zh-tw/
[16] M. Zaharia, M. Chowdhury, M.J. Franklin, S. Shenker and I. Stoica. Spark: Cluster Computing with Working Sets, HotCloud 2010, June 2010.
[17] Mitchell, M. (1998). An introduction to genetic algorithms: MIT press.
[18] MLlib. (2018). MLlib user guide. [Online].Available: https://spark.apache.org/docs/latest/mllib-guide.html
[19] OPC Foundation: OPC UA Specification: Part 1–Concepts. Version 1.00, July 28, 2006.
[20] OPCUA [Online].Available: https://zh.wikipedia.org/wiki/OPC_UA
[21] Siemens [Online].Available: https://www.siemens.com/tw/zh/home.html
[22] Siemens MindSphere Whitepaper [Online].Available: http://www.siemens.com.tw/release/pdf/MindSphere_Whitepaper_CH.pdf
[23] Siemens MindSphere Cloud for Industry[Online].Available: http://www.siemens.com.tw/industry/wp-content/uploads/epaper/MindSphere_Siemens%20Cloud%20for%20Industry_201609/files/assets/common/downloads/MindSphere_Siemens%20Cloud%20for%20Industry_201609.pdf
相關連結: 回175期_智慧城市智能感知與物聯網專輯
相關連結: 公版聯網服務平台NIP