工業技術研究院 資訊與通訊研究所 黃泰惠 蘇粲程 李青憲 陳德銘 涂家章

生成式 AI 可使用現有多模內容(如音訊、圖像或文字)來建立新內容。
在元宇宙的生成過程上,生成式AI (Generative Artificial Intelligence)將起到極其重要的作用。成為多模內容生成的關鍵技術力量。通過將 AI 與內容結合,由 AI 自動生成新的數位內容,讓文字、音樂、圖像、語音、視頻、商品、場景等都可由 AI 演算法自動生成。
生成式AI,從資料中透過各種機器學習方法,如生成對抗網路(Generative Adversarial Networks, GANs),學習隱含特性,進而生成如圖片的全新資料,這些生成的資料與訓練資料保持相似,但不是複製。
從過去透過人工設計特定特徵與生成規則,到近年從大量資料中透過生成式模型 (Generative models),如以 GANs手法生成擬真資料。其中相關應用,如從深偽(Deepfake)換臉應用、賽門鐵克(Symantec)報告提及的Deepfake聲音詐騙、Deepfake影片生成湯姆克魯斯彈奏吉他短影片,到AI完成貝多芬10號交響曲等,顯示新一代AI系統逐步從辨識任務走向生成任務,未來應用範圍也更將廣泛。
精彩內容
1. 生成式AI應用案例
2. 生成式AI技術現況與實例
3. 生成式AI未來發展 |
生成式AI應用案例
生成式AI是人工智慧領域近期的熱門話題。2022年Gartner 發布未來 3 到 5 年將促進數位營運和創新的重要戰略技術趨勢。其中生成式AI為12項重要戰略之一[1]。Gartner預計到2025年,生成式AI將占所有生成資料的10%,而目前此比例還不到1%。 生成式 AI 可使用現有多模內容(如音訊、圖像或文字)來建立新內容。可用於多種應用,如軟體開發、藥物研發和廣告行銷,但該技術也會被濫用於詐騙、政治造謠、偽造身份等。目前生成式AI已廣泛應用在各種產業,如生命科學、醫療保健、製造、材料科學、媒體、娛樂、汽車、航空、國防和能源等。
近期相當火紅的應用案例,例如台灣網紅小玉換臉應用。其主要針對影像或影片中人臉進行替換;除了負面應用之外,目前也正廣泛用在影音娛樂、遊戲等場域。該應用本質上屬於一種影像翻譯任務(Image-to-Image Translation),其中用到大量的生成對抗網路相關延伸技術[2]。

圖1 NVIDIA生成互動式人工智慧虛擬化身
人臉替換生成應用
近期相當火紅的應用案例,例如台灣網紅小玉換臉應用。其主要針對影像或影片中人臉進行替換;除了負面應用之外,目前也正廣泛用在影音娛樂、遊戲等場域。該應用本質上屬於一種影像翻譯任務(Image-to-Image Translation),其中用到大量的生成對抗網路相關延伸技術[2]。
聲音模擬生成與控制應用
美國演員方基墨,因喉癌需透過電子人工發聲器才能說話,在2021年也宣布和Sonantic公司合作[3],透過人工智慧生成其嗓音,近期也展示在《捍衛戰士:獨行俠》電影中。Amazon 2022 年6月發表Alexa新功能,可透過一分鐘聲音資料訓練後合成特定聲紋,其主要應用在於模擬去世親人的聲音,讓使用者與已故親人對話互動[4]。2022 年Meta公布的新技術包括語音生成元宇宙場景的Builder Bot、超級AI助手CAIRaoke等可以讓使用者透過口說描述所需環境樣貌,系統會透過模型建構虛擬世界如「Let’s go to a park.」、「Actually let’s go to the beach.」等指令, Builder Bot生成如公園、海灘等。
文字生成應用
文字生成應用,常見的應用有Bot自動回覆生成、語句生成、文件摘要等,其核心為自然語言生成技術,在自監督式學習(Self-Supervised Learning)成功應用在NLP領域,基於Transformer語言模型也被廣泛應用於文字生成。其中Open AI 的GPT 3可生成多種文體內容格式,如產品說明書、新聞稿,歌詞、劇本等。其中華盛頓大學所提出可控的文字生成模型Grover被用來生成假新聞與偵測假新聞[5],除可模擬紐約時報作家的寫作風格;此外也被用來產生《為什麼川普一天要做 100 個伏地挺身》文章,有趣的是該文章可掌握川普性格和言論風格。而Alibaba也進一步將技術推廣至電商場域─商品廣告文案生成助手,可根據商品特性產生廣告文案;除文字之外,Alibaba也進一步整合圖文等多模態(Modality)資料源,積極投入中文大型多模態視覺語言預訓練(Visual Language Pretraining)模型研發,目前廣泛用於產品文宣生成、搜尋、推薦與外觀設計等。
生成式AI於元宇宙應用
未來的幾年裡,每個人都會慢慢由只聽過變成感覺到元宇宙將有如電影中科幻的虛擬環境呈現在眼前,朝向身臨其境發展,虛擬環境充滿看起來與聽起來有如鏡像當前世界的寰宇;對於仍不熟悉元宇宙的人們來說,只是一個虛擬世界,可在其中戴上虛擬實境的眼鏡,並透過擬真的虛擬工廠、機台的維護組裝、通訊基地台如何配置、娛樂場所和許多活動來投射自己進入與現實近乎相同的世界,進入元宇宙就像是一個身歷其境、網路版本的虛擬現實世界,具有互動功能,使用不同的技術,如5G高速低延遲通訊、擴增實境 (AR)、虛擬實境 (VR)、2D轉化3D技術、人工智慧 (AI),將個人化的數位內容擴展到大眾面前,這一具前瞻性的技術就是生成式人工智慧,即利用現有資料學習使用,再利用人工智慧演算法來模擬創造新內容的過程。
2021年秋季的NVIDIA GTC 大會中,NVIDIA CEO用生成互動式人工智慧虛擬化身的 NVIDIA平台,這個平台整合包含語音 AI、自然語言、電腦視覺、推薦引擎和模擬等不同領域的技術,融合光線追蹤與 3D 繪圖,藉由這些AI工具,打造出具有語意理解對話能力的虛擬化身[6](如圖1)。
生成式AI技術,在元宇宙中,知名晶片大廠NVIDIA與汽車大廠 BMW 已透過 NVIDIA Omniverse 創造出數位孿生(Digital Twin)技術配合,在虛擬環境中導入所有真實物理參數設定,由生成式AI設計、模擬、操作和維護所有生產流程,轉而建構出極具未來性的真實生產工廠,可降低人們在設計生產廠房配置缺失[7] (如圖2)。

圖2 BMW導入NVIDIA Omniverse 數位孿生打造智慧製造[7]
知名電信商愛立信則是在元宇宙中,打造整個城市規模的數位孿生技術,配合匯入模型、建築物材質和植被等細節,同時利用 NVIDIA 光線追蹤視覺化效果,透過生成式AI陣列式計算並呈現城市內 5G 基地台的無線電波放射情況,並調整放置點,達到最佳覆蓋率與網路效能,可有效降低在5G基地台需要大量電力的消耗,也可同時獲得節能與減少碳排[6] (如圖3)。

圖3 生成式AI陣列式計算呈現5G 基地台無線電波放射[6]
想得到高品質的AI生成結果,往往需要大量的訓練資料,才能訓練出逼真的生成結果。自適性鑑別增強技術(Adaptive Discriminator Augmentation, ADA),可大幅減少訓練所需的影像數量,約可減少 10~20 倍的資料量。利用大都會藝術博物館提供不到 1500 張的圖片,將ADA技術套用於熱門的 NVIDIA StyleGAN 2的模型上,生成以假亂真的藝術作品[8](如圖4)。

圖4 AI生成藝術繪畫[8]
元宇宙充滿許多創造可能性,但也有許多目前法規無法規範的挑戰,元宇宙將示現著真實世界和虛擬世界碰撞的未來生活,隨著生成式人工智慧技術不斷蓬勃發展,無法容易分別新型擬真虛擬世界及我們所處的實際現實,或許只是時間的問題,是一個充滿無限創造但又帶著一絲擔憂的異世界。未來可透過對生成式人工智慧演算法的控制和創造性技術使用,在不超越倫理等相關規範情況下,組合以實現更具包容性和多樣化虛擬空間,目前正如具爆發性發展的種子。
生成式AI技術現況
人臉替換生成
人臉替換生成目前主流為透過GAN網路架構,其中CycleGAN就是將GAN應用,無監督圖像翻譯(image-to-image translation)的知名演算法,其主要來特點在於訓練資料不需要成對,只要不同域(domain)之間的圖像,就能訓練模型進行圖像翻譯任務。其中CycleGAN架構圖如圖5所示。
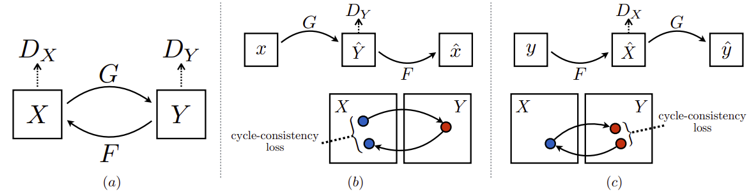
圖5 CycleGAN架構圖[9]
(a)表示模型包含G : X → Y 與F : Y → X兩個生成器(generator),並搭配兩個鑑別器 (discriminator)DY and DX;DY 功用在於讓 G 生成一個讓DY難以分辨的圖像,反之, DX與F的關係亦然。(b) 表達forward cycle-consistency loss也就是 F(G(x)) ≈ x;(c) 則表達backward cycle-consistency loss: G(F(y)) ≈ y。應用到人臉生成與成果比較[9]則如圖6、7所示。

圖6 GAN 人臉替換生成[9]

圖7 人臉替換生成結果比較[9]
文字生成技術
基於Transformer之語言模型應用到文字生成任務,最早可從2018 OpenAI GPT[10]模型架構如下圖8所示,其中採用Transformer的Decoder,搭配自回歸語言模型(Autoregressive LM),從文章上文內容,預測下一個詞彙。後續經過GPT2 GPT3陸續加入更大型模型與更大量訓練資料,其中GPT3模型參數到達1,750億,並使用45TB資料進行模型訓練。
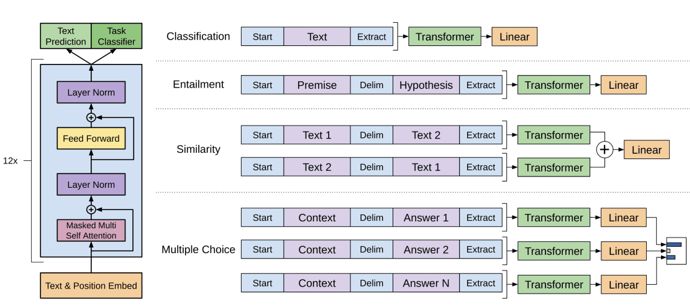
圖8 GPT網路架構圖與下游任務微調(fine tuning)[10]
而近期則是NVIDIA與微軟合作,提出Megatron-Turing NLG[11],參數量來到 5,300億,其中為了提升訓練效率,除引入稀疏化模型方法,如mixture-of-experts,也針對資料與模型進行平行化設計。在少量資料情境下,如zero-, one-, and few-shot learning,與多種NLP任務上,如Completion Prediction、Reading Comprehension、Commonsense Reasoning、Natural Language Inference等皆超越之前的SOTA效能。而Google也提出5,400億參數量的Transformer語言模型(Pathways Language Model, PaLM)[12],同樣訴求訓練效率提升,並在自然語言、code生成、數學推理等任務達到優異表現。
人工智慧之3D影像生成技術
元宇宙的目標是建立一個使用者可即時互動的沉浸式虛擬三維空間,使用者透過頭戴式眼鏡可看到在虛擬空間其他使用者的影像替身(Avatar)並可與之交談互動,也可用不同視角查看虛擬空間中的物體,或隨位置移動,看到不同的虛擬空間景象。
以建立沉浸式三維空間體驗的影像生成來說,這是屬於程序化內容生成(Procedural Content Generation, PCG)問題,其牽涉整合大量多媒體內容,包含影像3D模型、2D影像和360度影片。在電腦科學領域,程序化生成是一種利用很小的函式和源數據,便可製造出很多和源數據有關或類似但存在不同的新數據。在電腦圖學中,它也被稱為隨機生成,常用於製作材質貼圖和三維模型資源,並在電子遊戲領域中用於自動製造大量遊戲內容。程序化生成有著減小檔案體積、擴大內容量、增強遊戲隨機性等優點。傳統上的3D PCG包含了人工建立少量3D組裝塊資材,其可用於重組成數個不同的新物件。以3D PCG創造沉浸式虛擬空間的元宇宙建造者,若無相關工具和程序的深刻認識,將極端地限制其所能創造的內容[13]。
近年來人工智慧技術的發展已證實其是可降低程序化生成3D影像內容成本的有力工具(3D procedural content generation, PCG),不過此影像生成技術的進展目前仍處於它們的嬰兒期[14]。人工智慧3D影像生成技術開始受到人們矚目起於2020年神經輻射場(Neural Radiance Fields, NeRF)技術的論文發表,NeRF技術可從視角稀鬆取樣的固定2D輸入影像資料合成數個不同新視角的影像,如圖9所示,這些輸入影像內容可以是複雜的景物合成的新視角影像,依然保有精細的紋路。
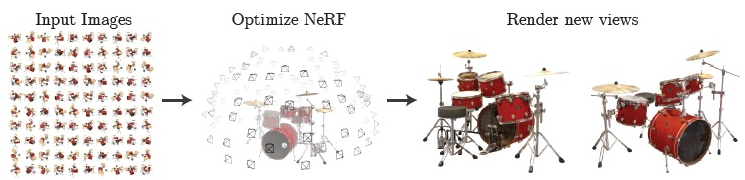
圖9 NeRF技術可從視角稀鬆取樣的固定2D輸入影像資料訓練出可合成數個不同新視角影像的模型[15]
NeRF利用5D的連續函數來描述靜態景物,該函數是根據輸入的空間座標(x, y, z)和觀測視角(θ, ϕ),輸出光線色值(r, g, b)和光線照過空間座標(x, y, z)之後的阻斷比例(volume density) [15]。NeRF採用全連接多層感知器(fully-connected multilayer perceptron, FC MLP)神經網路來模擬此連續函數,其輸入是一組5D向量,包含一組3D空間座標(x, y, z)和一組2D視角(θ, ϕ),其網路輸出是4D向量,包含3D的RGB色值和一個volume density值。NeRF渲染出指定視角景物影像的步驟如下:(1)從攝影機掃過景物的輸入光線取樣一組3D點集合;(2)將那些點的座標和相應視角輸入前述神經網路以得到一組顏色RGB值和volume densities;(3)採用傳統的立體渲染法(volume rendering)累積那些顏色RGB值和volume densities以得到一張2D影像。
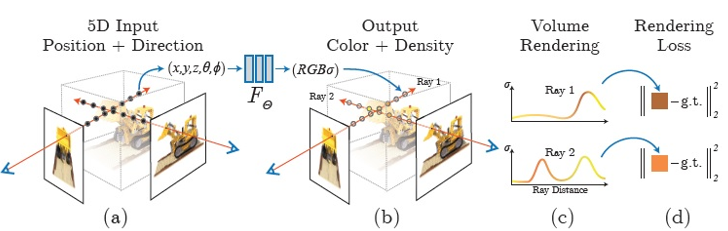
圖10 NeRF景物的神經網路照明域(neural radiance field)表示法和可微分的渲染步驟,以合成影像和目標影像的誤差值調整模型權重[15]
NeRF在MLP神經網路訓練階段採用梯度下降法(gradient descent)調整網路權重參數,以最小化輸出值產生之渲染圖與目標圖的誤差值,如圖10所示。從同一景物但取樣視角不同的數張影像,訓練一個MLP神經網路有助於得到高品質的立體渲染參數,使得合成圖的品質更接近真實。
以上是NeRF主要的基本方法和概念,原論文中也提到當此基本方法運用於高複雜度景物時,網路的輸出無法收斂到足夠的高解析度,且從攝影機每一輸入光線取得所需的樣本數沒有效率。為改善此問題,論文中提出將網路5D輸入向量先做帶有位置編碼訊息的轉換,使得MLP網路可以模擬較高頻變化的函數,並採用階層式取樣步驟,可降低高頻變化景物所需的光線取樣數。

圖11 NeRF與其他方法產生的新視角影像比較[15]
NeRF合成新視角影像的結果非常令人驚豔,特別是在金屬或有光澤物體的結果,視覺的真實性真的非常高。NeRF在2020年發表後短短不到一年內就累積了300多個 citation以及眾多知名後繼方法,包含結合 GAN獲得 2021 CVPR best的 GIRAFFE,算是為學術界開啟一個新的研究方向。
2021年發表的論文GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields[16]特點是可以經由生成對抗網路(Generative Adversarial Networks, GANs)的訓練方法將景物中的物件和背景做3D的分離,在合成影像階段可控制物件的視角和位置,以組合特徵域參數而渲染成一張影像,如圖12所示。此論文方法訓練過程中的生成部分類似NeRF,和一般GAN不同的地方在於使用多個模型分別表示同一影像中的物件和背景。
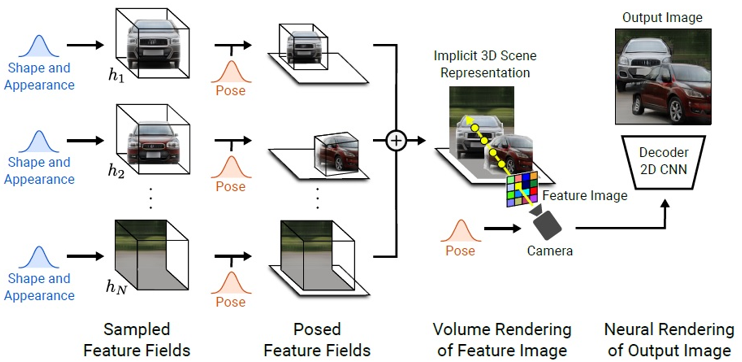
圖12 GIRAFFE將景物影像表示成數個神經網路特徵域的組合,藉由調整個別特徵域的視角和位置可控制合成影像的型態[16]
另外有數種NeRF的變形以加速訓練和合成新視角影像的研究發表,例如2021年發表的論文PlenOctrees for Real-time Rendering of Neural Radiance Fields[17],採用NeRF-SH(球面諧波SH, spherical harmonic)的MLP架構,輸出用spherical harmonic 係數k取代RGB色值,輸入的部分也不需視角(θ, ϕ)資訊,如圖13所示。NeRF-SH的MLP完成訓練後,藉由密集取樣所有訓練目標體的NeRF-SH模型輸出值以建立一存放volume density和SH係數的PlenOctree。此PlenOctree可另外進行內部參數最佳化以改善其品質。後續合成影像所需的RGB值則由加總那些係數k加權SH基底在視角(θ, ϕ)的函數值得到。所以此方法的訓練過程實際上包含NeRF-SH(MLP)訓練和PlenOctree參數最佳化的訓練,原論文提及由於發現NeRF-SH(MLP)的訓練並不須達到完全收斂的程度,所以此方法所需的整體訓練時間較原NeRF短。該論文的實驗結果顯示,以此PlenOctree技術合成800×800影像的速度超過150FPS,是原NeRF合成速度的3,000倍,而且保留NeRF可合成不同視角和幾何形狀景物的自由度,以及獲得更高的影像解析度品質。
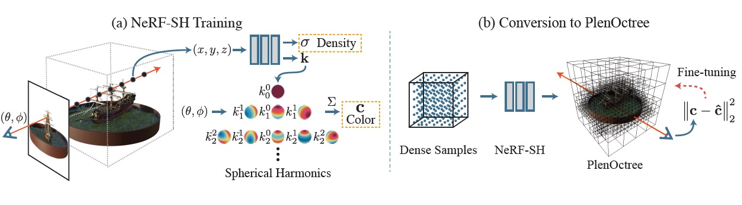
圖13 PlenOctree技術訓練階段概念圖[17]
生成式AI工具平台
NVIDIA 推出了Omniverse平台,是一個實現元宇宙易於擴展的平台,圖14是它的平台架構。利用Omniverse可進行 3D 設計協作和多 GPU 可擴充模擬,以及即時真實模擬。此平台改變了創作與開發,及團隊合作的方式,為團隊中帶來更多創意可能性與效率。在元宇宙中建立數位孿生,讓 BMW、Ericsson等公司能夠創作符合真實物理情況的虛擬環境,其中包含各種物件、流程或環境,而且這一切都能透過生成式人工智慧技術讓虛擬與真實世界的資料輸入內容持續同步。藉由 NVIDIA Omniverse平台、數位孿生、5G通訊網路,正以爆炸性的速度與更高的擬真度以實現元宇宙。

圖14 NVIDIA OMNIVERSE 平台[18]
生成式AI技術實例
本章節我們將介紹實作人工智慧之3D影像生成技術時蒐集訓練資料方法及參數設定,NeRF實驗程式碼可從原論文作者提供的(https://www.matthewtancik.com/nerf)取得。以NeRF論文裡提到的合成實驗資料庫為例,其訓練影像資料由以目標物件為中心的上半圓球平面100個隨機分布攝影機朝中心拍攝取得,這些影像資料的尺寸為800×800像素且附有相機拍攝角度和內部參數資訊。若所取得的目標物件影像並非正好填滿全影像,則需提供矩形物件框的座標位置給訓練程式,以便進行訓練時隨機取樣的拍攝光線可集中在目標物件。訓練NeRF MLP所需的遞迴次數約100k到150k之間。模型訓練過程中的影像生成誤差收斂後即完成訓練步驟,之後給予影像的視角即可使用此模型的輸出參數渲染出影像。因此若合成視角為環繞物件的圓形軌跡,即可產生360度環視物體的效果,如圖15所示。NeRF的合成效果在包含背景複雜的真實影像依然可維持紋路細緻影像的效果,如圖16所示。

圖15 以環繞物體圓形軌跡視角之合成影像

圖16 NeRF合成不同視角的真實影像時依然可保持影像細緻的紋路(影像圖片取自https://www.matthewtancik.com/nerf)
未來發展方向與相關議題
相較於早期的生成式AI偏向透過規則方法與小型模型,現在則透過大量網路資料搭配大型深度網路模型建構而成的大型預訓練模型,將讓生成式AI開始有了新典範。未來幾個面向值得注意:
創造性:從音樂圖片到文章與設計生成等應用案例,生成式AI方法似乎可達到不錯的成效,未來生成式AI是否可朝向與真人合作完成更具創造性的工作?為了達成此目標,過去訓練AI模型的目標函數(objective function)是否也要考慮加入創造性的元素,如novelty。
可控制性:透過真人與AI系統交互合作過程,讓生成內容的過程可被有效的控制,避免讓生成式AI一步到位產生內容,透過真人互動回饋,可減少AI生成過程中錯誤遞移現象導致失效。
此外,目前主流透過巨量資料訓練而成的大型預訓練模型,是否適合須產生具備創意元素之生成式AI應用?或者應透過不同的機制設計,如prompt composition,透過重構生成內容,得到更具創造性的內容?此外當大型預訓練模型中存在資料偏誤(Bias),是否影響生成內容?如何衡量與改善,都是目前尚待解決之問題。
結論
元宇宙是下一個世代的網際網路,未來人們可以在元宇宙裡進行各式各樣的互動,不過,目前仍處於發展的早期階段。生成式AI對建構豐富的元宇宙內容扮演關鍵的角色,目前在各個領域都有了初步的一些進展,隨著元宇宙的發展,未來生成式AI的技術值得持續關注。
參考文獻
[1] Gartner Top Strategic Technology Trends for 2022. Available at: https://www.gartner.com/en/information-technology/insights/top-technology-trends
[2] Goodfellow I, Pouget-Abadie J, Mirza M, et al. “Generative adversarial nets[J],” in Advances in neural information processing systems, vol. 27, 2014.
[3] How AI ‘masterfully restored’ Top Gun star Val Kilmer’s voice. Available at: https://fortune.com/2022/05/27/how-does-val-kilmer-speak-in-top-gun-maverick-sonantic-artificial-intelligence/
[4] Amazon's new pitch: let Alexa speak as your relatives from beyond the grave. Available at: https://www.engadget.com/amazon-alexa-voice-cloning-001552073.html
[5] Zellers, Rowan, et al. "Defending against neural fake news." Advances in neural information processing systems 32 (2019).
[6] GTC November 2021 Keynote with NVIDIA CEO Jensen Huang. Available at: https://www.youtube.com/watch?v=jhDiaUL_RaM
[7] BMW and Omniverse for Production. Available at: https://www.nvidia.com/en-us/on-demand/session/gtcfall21-a31325/
[8] NVIDIA Research Achieves AI Training Breakthrough Using Limited Datasets. Available at: https://blogs.nvidia.com/blog/2020/12/07/neurips-research-limited-data-gan/?ncid=so-yout-23960#cid=_so-yout_en-us
[9] Liu, Kai, Bicheng Li, and Jiale Li. "Deep Face-Swap Model Combining Attention Mechanism and CycleGAN." in Journal of Physics: Conference Series. Vol. 2278. No. 1. IOP Publishing, 2022.
[10] Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
[11] Smith, Shaden et al. “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model.” arXiv:2201.11990 [cs.CL].
[12] Chowdhery, Aakanksha et al. “PaLM: Scaling Language Modeling with Pathways.” arXiv:2204.02311 [cs.CL].
[13] Toni Witt, "How Generative AI Will Help Build the Metaverse", 3/31/2022 . Available at: https://accelerationeconomy.com/ai-ml/how-generative-ai-will-help-build-the-metaverse/
[14] Shu-Ching Chen, "Multimedia Research Toward the Metaverse", in IEEE MultiMedia, vol. 29, no. 1, pp. 125-127, 2022
[15] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” in Proc. Eur. Conf. Comput. Vis., pp. 405–421, 2020.
[16] M. Niemeyer and A. Geiger, "GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields", in Computer Vision and Pattern Recognition Conference (CVPR), 2021.
[17] A. Yu, R. Li, M. Tancik, H. Li, R. Ng, and A. Kanazawa,“Plenoctrees for real-time rendering of neural radiance fields,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., pp. 5752–5761, 2021.
[18] Powering A New ERA OF Collaboration and Simulation in Media and Entertainment. Available at: https://boxx.com/Files/Files/WhitePapers/Omniverse%20Media%20and%20Entertainment%20-%20Solutions%20Showcase.pdf
相關連結: 虛擬實境浪潮下的3D產業與3D內容
相關連結: 虛擬實境的沉浸感