工研院資通所 張仕穎 蔡雨憙
在AI技術及應用蓬勃發展的當下,資料儼然成為人人爭搶的新一代原油,人人都想要大量及高品質的資料,用以提升模型準確率及以降低模型的複雜度。但收集/清理資料通常曠日費時,過程繁瑣乏味,所以資料品質工具產業趁勢而起,提供各種資料清理(Data Cleaning)及資料關聯擴充(Data Enrichment)的自動化工具。我們以地址資料為核心,除了開發清理地址資料的正規化技術外,也開發可透過標準化地址去自動勾稽外部資料的資關聯技術,協助國內廠商以快速、低成本的方式,改善自身資料品質,打造廠商AI化所不可或缺的資料基石。
精彩內容
1. 地址正規化的市場發展趨勢
2. 地址正規化技術介紹
3. 資通所地址正規化技術發展與推廣
|
地址正規化的市場發展趨勢
為了避免「Garbage in, garbage out」,每一個資料科學家在進行資料分析前,都必須極力確保資料的品質及盡可能的擴充關聯外部資料。這時就需要資料比對技術(Data Matching 或 Record Matching),主要可以用來去重複(De-duplication)或是替不同資料集建立關聯等(Record Linkage)[1,2, 10]。
本文比對技術的標的就是地址比對,因為幾乎所有開放資料或是客戶資料,都會跟地址有關。如何判斷兩筆地址資料,是對應到實際世界的同一個地址呢?這時就需要地址正規化技術!先將原始地址資料正規化到同一個基準,才能做後續的資料去重複跟比對。試想你有你有兩個資料表,一個有全台充電站的地址資訊,一個有用電戶地址及用電量,你想透過地址比對去關聯兩個資料表,藉此分析充電站的用電模式。在缺少地址正規化技術下,你很可能會因為兩個資料表的地址格式不一致、地址資訊缺漏錯誤或是舊地址未更新等問題,導致比對率過低,無法發揮資料所擁有的最大價值。
以產業領域來說,地址正規化技術屬於資料品質工具(Data Quality Tool)的範疇,資料品質工具市值預估從2017的 610.2M美金成長到 2022年1,376.7 M美金,每年成長17.5%[11]。地址正規化與資料清理(Data Cleaning)及資料關聯擴充(Data Enrichment)有關,雖然地址正規化在國人認知似乎毫不起眼,但國外卻有不少API服務(如:smartystreet、Lob等)或是套裝軟體(如:Xverify、Melissa、Byteplant等)[12] 是專門提供地址資料處理的服務,足見地址正規化之重要性。
而國內地址正規化的技術發展,早期通常只是一個資訊系統的附加功能,如:志弘資訊及豪雅科技等,到近幾年的專門地址正規化服務,如:Trinity、崧旭等,漸漸地在國內也開始受到重視。
地址正規化技術介紹
在先前文獻中,已經有不少地址正規化技術的相關研究,主要是著重在地址斷詞(也稱做Address Parser),以國外地址而言,通常只要你能正確地斷詞,後續的拼寫校錯及格式轉換通常就能迎刃而解,而不像台灣地址常會有資訊錯誤或缺失的情況發生。這些地址斷詞有的是基於Conditional Random Field (CRF) [3][4][5]、地址辭典查找 [6]、或是基於 Hidden Markov Model (HMM) [7]。大部分還是需要做特徵工程,需要倚賴專業知識去取特徵。[8][9]則提出以深度學習為基礎的地址斷詞,擺脫需要特徵工程的限制,也可以達到跟傳統方法差不多的正確性。但是目前鮮少中文的地址正規化技術 [3]。
我們的方法則是結合傳統的rule-based及AI learning-based技術,來兼具速度及準確率。更明確的說,地址斷詞這類需要專業處理經驗,且處理規則單純,我們就會使用rule-based來追求效率跟彈性;而規則較複雜的,例如:用戶比較容易寫錯路名還是鄉鎮區、常寫錯的字,我們就會導入AI學習的概念,讓模型可以依據用戶的習慣,學習正確的決策。
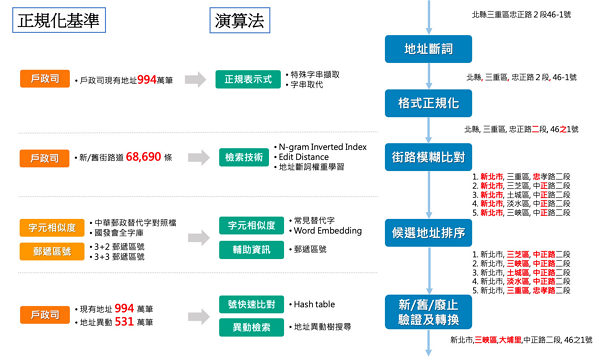 圖1 地址正規化流程及示意圖
圖1 地址正規化流程及示意圖地址正規化過程就是把輸入地址參照基準資料來做校正,把一個輸入的地址,校正成一個基準資料中的標準地址。我們使用戶政司的現有門牌地址資料及門牌地址異動資料來建立正規化地址的基準資料,包括:現有門牌地址、舊門牌地址、門牌異動紀錄等(詳細請參照圖1、左側)。 地址正規化共經過五個主要的步驟,說明如下:
1.地址斷詞
產生地址階層的斷詞。如:縣市、鄉鎮市區、村里、路街道、巷弄號等地址階層,地址斷詞的資訊主要跟後續的格式正規化及街路模糊比對的權重有關。地址斷詞是採取傳統的Rule-based做法,憑藉著過去處理大量地址的經驗,建立兼具效率及正確性的斷詞規則。沒有看過全台地址,很難產生完整的地址斷詞,因為地址樣態五花八門,如以下兩個地址正規劃的例子: “臺中市西區中興里中興四巷36號”,一般可能會斷成<臺中市、西區、中興里、中興、四巷36號>,因為巷弄關鍵字通常是在路段後面,而我們則能成功斷成<臺中市、西區、中興里、中興四巷、36號>。 “臺中市大里區大里二街151號”,一般可能會斷成<臺中市、大里區、大里、二街、151號>,因為把‘里’當成斷詞的關鍵字,而我們則能成功斷成<臺中市、大里區、大里二街、151號>。
2.格式正規化
針對內容的格式正規化,包括:數字全形半形、阿拉伯數字及中文數字、號之及之號等各種為了內容及格式統一的轉換。而不同地址階層會套用不同的正規化處理,例如:街路部分的數字要正規化成中文數字,巷弄號則是正規化成半形數字。
3.街路模糊比對
如果地址都是完整的,基本上前兩步驟就可以得到一個正規化後的地址,但是地址通常都是有缺漏或是錯誤的,所以還是得透過模糊比對技術,比對輸入地址與校正基準資料中的地址,找一個最接近且唯一地址做為輸出的地址。主要使用倒排索引(Inverted Index)加上n-gram [13]的編碼技術去達成高速的字串的模糊比對,篩出候選地址後,再進行編輯距離(edit distance)的比對來找到最接近的候選地址。採用n-gram的倒排索引是為了提升比對速度,畢竟直接去比對全台門牌地址,在效率上較為不可行。
4.候選地址排序
承接上一步的結果,針對候選地址排序,主要依據錯誤類型及全字庫資料建立有權重概念的比對方法來增加準確率,例如:一般手動輸入的地址,“縣市/路街道”資訊相較於“鄉鎮區/村里”資訊的正確機率比較高;另外,輸入的錯誤通常與輸入法有關,例如:使用注音輸入法的用戶,可能把 ‘得’或‘中’輸入錯誤,若是輸入的地址是“忠正路”,而候選地址有“中正路”與“忠孝路”,程式就可以依據上述原則,選擇“中正路”輸出,而不是因為兩個候選地址的編輯距離都是一個字不一樣,就輸出兩個候選地址。同理,也可以透過類似的做法,解決歧異字編碼的問題,讓字音/字形類似的候選地址給予較高的權重。另外,若是有提供額外資訊,也可以輔助判別排序,例如:郵遞區號、客戶提供的常見替代字/錯別字等。
5.新/舊/廢止驗證及轉換
將校正後地址依據基準資料中的異動歷程資料,來判定該輸入地址是戶政司資料裡的現有地址、廢止、舊地址或不存在,若是舊地址則自動轉換成新地址,若是廢止地址則輸出廢止日期等資訊。既然都已經對到一個實體地址了,除了格式的正規化外,也可以補足相關缺失(如:村里)及錯誤的資訊,另外,也可以驗證該地址是否是實際存在在地址資料庫之中。地址是否實際存在戶政司資料裡,對於郵政/物流的應用特別有價值。
資通所地址正規化技術發展與推廣
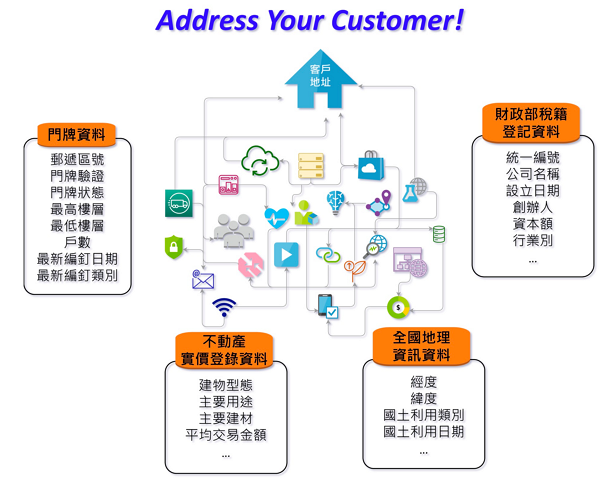 圖2 地址正規化及資料整合服務(Address Your Customer)
圖2 地址正規化及資料整合服務(Address Your Customer)於資通所地址正規化技術之發展,我們從資料的清理,擴充至資料的關聯,透過標準化的地址,關聯更多的開放及客戶資料,如圖2所示。透過資料地址正規化服務及資料整合服務,讓廠商可以提高自己用戶資料的品質以及擴充自己的資料屬性,讓其可以提昇AI模型的準確率。例如:
.協助能源局勾稽用電地址與稅籍資料的行業別資訊,使其可以分析不同行業別下的用電趨勢;
.協助房價預測公司勾稽地址樓層及屋齡,改善其預測模型準確率;
.協助校正台電用電地址,補足村里資訊,以利辦理村里節電競賽等等。
為了方便廠商使用,我們也將服務串接成API的方式,如圖3,讓廠商輸入用戶地址,就可以得到關聯多樣資料屬性的json格式輸出,目前也已經成功推廣給數家廠商,協助提升其資料品質。
 圖3 地址正規化及資料整合服務API
圖3 地址正規化及資料整合服務API在推廣地址正規化及資料整合服務過程中,我們會提供資料品質評估的工具(Data Profiling/ Data Assessment),例如讓廠商上傳一百筆地址資料,由資料品質評估工具顯示,其中有20筆地址是有異動過的,有30筆是公司地址,其中20家營業中,10家停業,20家裡面有5家是新創。廠商可藉此知道自己資料的品質與可擴充性,進一步評估地址正規化及資料整合服務在其業務及廣告上的助益。
結語
資料是新世紀的原油,但沒有精煉、合成,則無法發動具商業價值的AI應用。我們累積長期的資料處理經驗,致力研發台灣在地化的資料品質工具,包括:門牌/地號地址的正規化工具以及可勾稽數個資料來源的資料關聯工具。協助廠商以快速、低成本的方式改善自身資料品質,來打造機器學習/AI應用的穩固資料基石。雖然不像大廚有引人注目的華麗的身手,但是沒有廚房會不需要削馬鈴薯的助手,資料品質工具也是一樣,雖然不是個獨立搶眼的應用,但是我們期許可以成為廠商所依賴的最佳資料處理助手,與廠商一同挖掘自身資料的潛力。
參考資料
[1] Christen, P. Data Matching—Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer Science & Business Media, 2012.
[2] . Elmagarmid, A. K., Ipeirotis, P. G., Verykios, V. S. Duplicate record detection: A survey. IEEE Trans. Knowl. Data Eng 2017; 19(1): 10-16.
[3] Sun, W. Chinese Named Entity Recognition Using Modified Conditional Random Field on Postal Address. 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI);1-6.
[4] Arora, N., Knock knock: who's there? package delivery at the right address. ACM Proceedings of the Sixth International Conference on Emerging Databases: Technologies, Applications, and Theory 2016; 86-89.
[5] Wang, M., Haberland, V., Yeo, A., Martin, A., Howroyd, J., Bishop, J. M. A probabilistic address parser using conditional random fields and stochastic regular grammar. In IEEE 16th International Conference on Data Mining Workshops (ICDMW) 2016; 225-232.
[6] Matci, D.K., Avdan, U. Address standardization using the natural language process for improving geocoding results. Computers, Environment and Urban Systems 2018; 70:1-8
[7] Li, X., Kardes, H., Wang, X., Sun, A. Hmm-based address parsing with massive synthetic training data generation. In ACM Proceedings of the 4th International Workshop on Location and the Web 2014; 33-36.
[8] Sharma, S., Ratti, R., Arora, I., Solanki, A., Bhatt, G. Automated parsing of geographical addresses: A multilayer feedforward neural network based approach. IEEE 12th International Conference on Semantic Computing (ICSC) 2018; 123-130.
[9] Abid, N., ul Hasan, A., Shafait, F. DeepParse: A Trainable Postal Address Parser. IEEE Digital Image Computing: Techniques and Applications (DICTA) 2018;1-8.
[10] Koumarelas, I., Kroschk, A., Mosley, C., Naumann, F. Experience: Enhancing address matching with geocoding and similarity measure selection. Journal of Data and Information Quality (JDIQ) 2018; 10(2):1-16.
[11] Data Quality Tools Market by Data Type, Business Function, Deployment Model, Organization Size, Vertical - Global Forecast to 2022 https://www.marketsandmarkets.com/Market-Reports/data-quality-tools-market-22437870.html
[12] Top 5 Postal Address Verification Software in 2020, https://www.techtimes.com/articles/246472/20191211/top-5-postal-address-verification-software-in-2020.htm
[13] Kim, M., Whang, K., Lee, J. n-Gram/2L-approximation: a two-level n-gram inverted index structure for approximate string matching. Computer Systems Science and Engineering 2007; 22(6):365-379.
相關連結: 回182期_AI智慧應用專輯
相關連結: 智慧圖資在房屋鑑價與無線網路佈建的應用