工研院資通所 王書凡
近年來因金融監管強度提升,合規成為法遵人員的主責。在法規變動頻繁下,易因疏失而忽略重要合規,導致金融機構遭裁罰。為解決此痛點,法遵人員期望能將合規監控流程智慧化,以減少發生人為疏失的機率,達到降低被裁罰的風險。欲將合規監控智慧化,可透過自然語言處理語意分析技術來達成,因此,本篇將先探討語意分析技術的發展,再說明如何應用語意分析技術將合規監控智慧化。
 透過自然語言處理語意分析技術,能將合規監控智慧化,帶動我國法遵科技的發展
透過自然語言處理語意分析技術,能將合規監控智慧化,帶動我國法遵科技的發展
精彩內容
1. 語意分析技術發展
2. 資通所開發之金融法規文本語意分析技術
|
語意分析技術發展
語意分析的核心是如何能讓機器跟人一樣理解文章。機器無法直接理解文章,需將文章裡每個詞轉換為機器可計算的詞嵌入語意向量,再組合所有詞的語意向量來理解整篇文章。語意分析技術從離散編碼向量、含前後詞資訊的詞語意向量,到考慮上下文資訊及賦予詞權重的文本語意向量,在自然語言處理領域中已有突破性的進展。
離散編碼向量 初步轉換成機器可計算的數值向量
欲將詞轉換為數值向量,需事先統計所有文本中的詞集,再以與詞集大小相同的數值向量在每個詞對映的索引值中標記有效,此方式稱為獨熱編碼(One-hot Encoding)。舉「金融法規文本語意分析技術」為例:假設此文本的所有詞集為{“金融”、 “法規文本”、“語意分析”、“技術” },其中“金融”的編碼方式為先取得詞集大小4,且“金融”在詞集的索引值為0,因此在長度為4的數量向量且索引值為0的位置標記1(有效值),即得到獨熱編碼向量為1000,以相同編碼邏輯此文本所有詞的獨熱編碼分別為:{“金融”:1000、“法規文本”:0100、“語意分析”:0010、“技術”:0001 }。 但離散編碼向量未被大量應用,因其有2個致命缺點,一為實際處理的所有文本詞集大小都是以萬計,因此離散編碼向量長度會達萬以上,非常佔記憶體的空間;二為它無法有效表達詞與詞之間的語意程度。
考慮前後詞語意向量 加入人腦理解思維
欲使機器的語意理解能力接近人類,以上一節的獨熱編碼是不足的,其缺乏詞與詞之間的語意表達。英國語言學家J. R. Firth提到,要充分理解一個詞的語意,需先理解它的上下文資訊,為使離散編碼向量有效表達詞與詞之間的語意程度,發展出以詞在文本中的次數及兩個詞間共同出現的機率來訓練詞數值向量,以滿足語意相近的詞在向量空間上能有較近的距離,其稱之為語意向量(Semantic Vector)。舉例來說,在一個語料庫中,「金融」的上下文可能會常出現「資產」、「負債」、「資金」等詞彙,「金融」一詞可透過這些詞彙產生語意向量,讓「金融」與「資產」的語意能較近,與無關的詞彙(如:「電話」)較遠,將更接近人腦理解思維。取得語意向量的常用演算法有Word2vec[1]、GloVe[2]。Word2vec為2013 年由Tomas Mikolov等人所提出,其使用2種方法來預測詞語意向量,分別為Continuous Bag of Words及Skip-gram,2種預測詞的方式在不同的任務各有展現;GloVe由Stanford團隊開發,其與Word2Vec類似,但GloVe更能考慮詞與詞間的共現,訓練速度也快,不管大規模或小規模的語料庫都有不錯的擴展性及性能表現。
含上下文資訊的文本語意向量
文本由數個詞組成,文本語意向量直觀上可透過文本內所有詞語意向量平均取得,但平均方式無法將文本特有的時序特性嵌入語意向量中,即每個詞在文本語意向量中被視為獨立的個體,無法表達詞序及句法的差異。為解決此問題,Doc2vec[3]、 平滑倒詞頻(Smooth Inverse Frequency, SIF)[4]、遞迴類神經網路(Recurrent Neural Network, RNN)[5]、長短期記憶網路(Long Short-Term Memory, LSTM)[6][7]等類型的語言模型因而發展,將詞語意向量以正向或雙向方式串接訓練,產生含時序特性的文本語意向量。Doc2vec由Word2vec團隊基於Word2vec無詞序及句法的缺點開發,並在架構中加入1個可以代表文本主題的向量,讓訓練文本語意向量的過程都保有該文本主題;SIF則有2個步驟,首先出現頻率愈低的詞,高機率是屬於文本的重要詞彙,需加強其權重值;接著在每個文本都有出現的詞(共有信息),其重要性在整個語料庫中相對較低,為能更有效表達不同文本間的主題,透過奇異值分解(Singular value decomposition, SVD)取得文本間的共有信息,再去掉這些共有信息以加強文本間的主題差異性,此方法簡單且具競爭力。
注意力機制 由文本主題自動為詞賦予權重
在平滑倒詞頻演算法中,雖已賦予每個詞有不同權重,但其無法依據不同的主題給予合適的加權,因此注意力機制[8]開始被重視,其可透過分類準則來給定不同的主題,並自動學習哪些詞對於文本主題是關鍵,關鍵的詞賦予較高權重,非關鍵的詞則壓低其權重,使文本語意向量更能突顯文本主題。
 圖1 透過注意力機制將賦予法規文本中每個詞重要性權重示意圖
圖1 透過注意力機制將賦予法規文本中每個詞重要性權重示意圖資通所開發之金融法規文本語意分析技術
面對法規異動頻繁的環境,現行金融機構作業高度依賴法遵人員進行人工法規解讀、內外規對映等,不僅費時、也容易造成解讀偏差與疏漏,當被政府機關檢核發現重大疏漏,金融機構還因此會被重罰,增加不必要的成本。為解決此痛點,開發在地化之金融法規文本語意分析技術,透過蒐集金融及法規的專有詞彙擴充中文斷詞系統的字典並賦予每個詞在金融法規中特有的命名實體識別(Named Entity Recognition, NER)建立金融法規知識庫,針對我國金融法規文本進行特徵解析、特徵語意理解及相似法規關聯計算,改善法遵管理作業上自動化與智慧化不足的問題。
 圖2 本所開發之在地化金融法規語意分析技術
圖2 本所開發之在地化金融法規語意分析技術法規文本特徵解析 取得金融及法規領域特徵
金融法規文本泛指函釋、裁罰案件及法律條文等,其內文含大量金融法規領域的專有詞彙,如:外匯授信、共同基金、投資型金融商品等,如運用「金融」和「法規」領域的專有詞彙,語意分析技術將能在金融法規領域有效發揮。只可惜現今斷詞系統無法有效斷出專有詞彙,舉「投資型金融商品」為例,以現有斷詞系統不視其為一詞,將被斷成「投資型」、「金融」及「商品」3個較普遍的詞。因此,欲使金融及法規專有詞彙能正確斷出,需大量收集專有詞彙做為斷詞系統的擴充字典,讓斷詞系統正確地斷出金融法規文本的詞特徵。 接續透過NER賦予每個詞在金融法規中特有的標記,正確辨識法律條文、業務、標的物、發文字號、金額、日期、門檻值、金融概念等(如圖2的[法規特徵])特徵,並建立金融法規知識庫儲存,做為語意分析的重要基礎資料。
法規文本特徵語意理解及內外規關聯計算
透過NER及詞性篩選具備金融及法規特徵之文本資料後,運用平滑倒詞頻取得文本的語意向量,接著評估文本語意向量間的相似程度。在向量空間中可透過兩向量的夾角來判定其相似程度,但兩向量的夾角計算困難,而改計算夾角的餘弦值,其值介於正負1之間,即為餘弦相似度方法。當2個文本語意相近時,其語意向量的夾角小,餘弦值接近最大值1,因此可藉由餘弦相似度愈大,語意愈相似來進行文本間的語意關聯。以內外規對映應用為例,可關聯出如圖3的結果。 關聯結果優劣可透過公司內部制定的法遵手冊來驗證,如圖3中的「保險業內部控制及稽核制度實施辦法第30條」,在法遵手冊內提及其應遵循的制度規章為「法令遵循作業準則」,再檢視回關聯結果,語意相似最高的結果不但對映正確,還能指出是法令遵循作業準則中的第10條。以此原則計算整體的內外規對映準確率可達85%。
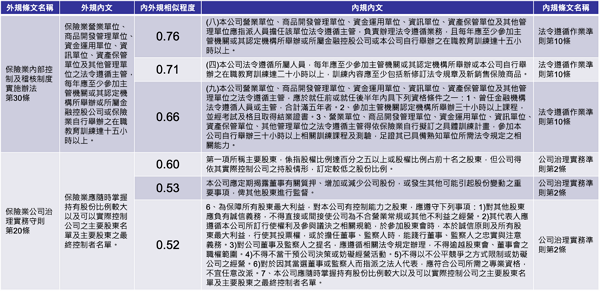 圖3 語意分析技術外規關聯內規結果
圖3 語意分析技術外規關聯內規結果合規監控智慧化 指出具風險的規章
圖3的語意分析結果列出與外規高相似的內部規章,其可減少法遵人員人工判讀及檢核的時間,並透過候選名單揪出不合規的內部規章。以圖3為例,假使金管會將「保險業內部控制及稽核制度實施辦法第30條」的最低時數限制從15小時上修至20小時,當法遵人員收到修法通知後,即可快速透過圖3結果得知「法令遵循作業準則第10條」有不合規的風險,並立即通報相關單位期限內修正且向上回報,以避免金融機構因查核而被裁罰。
未來發展
並非所有文本內的詞彙皆與文本主題相關,如圖3的「保險業公司治理守則第20條」,其正確的對映應為內外規相似程度為0.52的文本,但因其所述的範圍較廣,以致於語意分析時無法專注在其該有的主題上。為解決此問題,未來將導入注意力機制,由語意模型在訓練時自行學習加強與文本主題相關的詞彙,使文本語意向量能正確表達主題。另為擴展詞特徵的同義詞及上下位詞等資訊,將結合知識圖譜(Ontology)技術,透過機器學習與知識圖譜技術相輔相成,以增加本系統語意分析的資訊量,進而取得更佳關聯結果。
結論
金融法規文本語意分析技術針對我國金融法規文本數據與法遵知識領域,透過蒐集金融及法規的專有詞彙擴充中文斷詞系統的字典協助斷詞,且賦予每個詞在金融法規中特有的NER,並由NER篩選出具有金融及法規的語意分析資料,再透過平滑倒詞頻將金融法規文本轉為機器可讀之語意向量,最後利用餘弦相似度關聯相似的金融法規文本,以建構一套符合在地化法遵需求的技術。
此技術可協助法遵人員在合規時不需檢核大量的內部規章,透過語意分析標出高相關的內部規章,縮小檢核的法規數量以減少人工負擔,使法遵人員能有更多的時間可專注在後續的風險分析,以避免金融機構因不合規而被主管機關重罰。
參考文獻
[1] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado and J. Dean, “Distributed representations of words and phrases and their compositionality”, Proc. Advances Neural Information Processing Systems, pp. 3111-3119, 2013.
[2] Jeffrey Pennington, Richard Socher, and Christopher D. Manning, “GloVe: Global Vectors for Word Representation”, 2014.
[3] Q. Le and T. Mikolov, “Distributed representations of sentences and documents”, Proc. 31st Int. Conf. Machine Learning, pp. 1188-1196, 2014.
[4] S. Arora, Y. Liang and T. Ma, “A simple but tough-to-beat baseline for sentence embeddings”, ICLR, 2017.
[5] P. Liu, X. Qiu and H. Xuanjing, “Recurrent neural network for text classification with multitask learning”, IJCAI Int. Jt. Conf. Artif. Intell., vol. 2016-January, pp. 2873-2879, 2016.
[6] D. Li and J. Qian, “Text sentiment analysis based on long short-term memory”, 2016 1st IEEE Int. Canf. Comput. Commun. Internet ICCCI 2016, pp. 471-475, 2016.
[7] Zheng Xiao and PiJun Liang, “Chinese Sentiment Analysis using Bidirectional LSTM with word Embedding”, IInd International Conference on Cloud Computing and Security (ICCCS), pp. 601-610, 2016.
[8] Z. Lin et al., “A structured self-attentive sentence embedding”, 2017.
相關連結: 回182期_AI智慧應用專輯