精彩內容
1. 專利地圖分析
2. 關鍵字擷取技術
3. 專利國際分類號關鍵字擷取
4. 專利分析應用服務 |
智慧財產是在產業國際化競爭過程重要的發展項目,如研發成果需要提升在智慧財產競爭的能量,專利布局將是其中不可或缺的工作,藉由專利布局可評估重要技術發展趨勢、重要國際廠商的技術發展方向,並以國際技術標竿作為專利布局規劃方向,提供研發投入之決策參考[1]。在經濟部產業創新條例12條施行後,政府所資助之研發計畫,須在執行前進行智慧財產經營規劃,因此專利分析布局成為計畫研發必要之工作,不僅執行計畫的法人機構有強烈的專利分析工具之需求,提供智財服務之技術服務業者,亦需要優質工具來協助專利分析。
專利地圖分析
專利地圖分析是將特定技術領域中的專利相關資訊,依各類別整理分析,而得各類之分析圖表,其主要目的在於瞭解技術發展歷程與趨勢、各專利權人競合關係及權利範圍等資訊,以作為觀察技術發展及相關企業動態之參考。專利地圖分析步驟繁多,詳細的分析流程參考圖1,而資通所目前開發的專利分析應用服務可協助加速地圖分析並取得較為準確的結果,本文會介紹如何取得專利分類號的關鍵字,並展示其應用於專利地圖分析的服務。
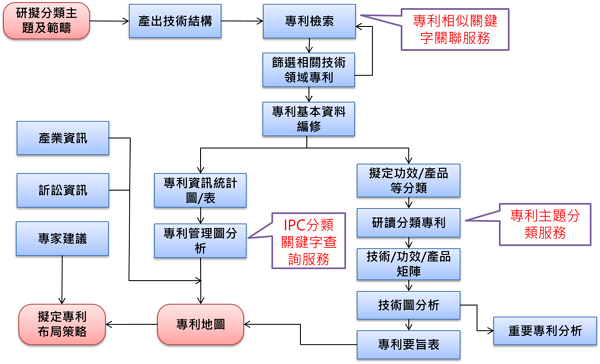
圖1 專利地圖分析執行流程[1]
國際專利分類系統(International Patent Classification,IPC)
在做專利檢索及專利布局分析時,使用正確的專利分類號能夠得到較準確的檢索結果,而如何把技術主題對應到專利分類號,就成為進行分類或檢索時很重要的工作,同時分類號也能讓專利閱讀者能夠快速的找到相關專利文獻。 IPC 是一種國際性的專利分類方法,其依據為西元一九七五年生效 的「關於國際專利分類之史特拉斯堡協定」,該協定中說明設立 IPC 的目的在為各國間的專利分類建立一套國際性的標準。目前有超過一百個國家採用 IPC [2]。 在架構編排部分,IPC 是按照技術主題來設立的,採用階層結構將整個技術領域按降冪方式依次分為五個不同的等級,IPC分類號結構按階層次序分別包含:部(Section)、 主類(Class)、次類(Subclass)、主目(Main group)、次目(Sub group)。目前 IPC 共分為有八個部,如表1所示,完整的IPC分類號包含五階層的分類等級,如「A63B 22/02」,其中A為「部」,A63為主類,A63B為次類A63B 22為主目,而A63B 22/02為次目。詳細IPC國際專利分類請參考智財局網頁[3]。
表1 國際專利分類系統「部」分類說明
專利的IPC分類歸屬,是專利審查人員在審查專利時所進行的分類標記,屬於人工標記的資料,一篇專利可能因其應用領域而有多個IPC分類號。IPC是專利資料中少見的人工標記資料,本文提出一種IPC分類關鍵字擷取方法,用以輔助專利檢索及專利地圖分析的工作。
關鍵字擷取技術
「關鍵字自動擷取」是一種辨認數位文件內有意義且具代表性詞彙自動化技術,常運用於搜尋引擎最佳化(SEO)、專利分析、輿情分析等領域。關鍵字擷取技術從應用面區分可分為單一文件關鍵字擷取及多文件的關鍵字擷取技術,其中兩者的差異是單一文件關鍵字擷取技術可從單一文件中的文字排列、句法結構及詞彙共同出現機率,判斷能代表此文件的關鍵字,而多文件關鍵字擷取是統計字詞在文件中的分布,找出重要性高的字詞,或是在已分類的文件中,找出可區分類別,具有類別代表性的字詞。
單一文件關鍵字擷取
Mihalcea及 Tarau 在2004年提出TextRank[4]。TextRank是基於圖論的關鍵字擷取方法,使用移動視窗掃過輸入文件,建立每個字詞之間共同出現的權重矩陣,再仿效PageRank疊代的方式計算每個字詞的重要性,而排名在前的字詞即為本文件的關鍵字。Rose, S.及Engel, D等人在2010年提出RAKE關鍵字擷取方法[5],使用標點符號及停用詞做為分詞標準,建立字詞共現矩陣,依其共現次數、出現頻率等特徵選取特徵分數較高的字做為關鍵字。Campos, R.及Mangaravite, V等人在2018年提出YAKE[6]。YAKE是一種非監督式的關鍵字擷取方法,主要參考字詞在文句中出現的位置、出現頻率、不同句子出現次數等資訊,判斷字詞的重要性。
多文件關鍵字擷取
常見多文件關鍵字擷取做法有是基於統計分布及文本分類的方法。基於統計分布的經典做法是SALTON,G.及 BUCKLEY, C.在1987年提出的TF-IDF[7],其基本精神在於一個字詞的重要性依其出現次數(Term Frequency, TF)成正比,與其所出現的文件數量(Document Frequency, DF)為反比。而基於文本分類的關鍵字擷取做法,常見是使用文本分類方法,如LDA、SVM,再依其類別詞袋(Bag-of-words)中的權重,排序字詞的重要性。
專利國際分類號關鍵字擷取
專利國際分類號(IPC)是做專利檢索及專利地圖分析時常用的利器,如能自動擷取每個分類號的代表性關鍵字,有助於理解專利分類號所代表的含意,並可提升專利檢索準確度及專利地圖分析效率。本文提出一種基於分類方法的IPC關鍵字擷取技術。
在資料蒐集及前處理階段,蒐集美國專利共1200萬餘篇,其中涵蓋超過12萬個IPC分類號,對IPC分類號的專利數量進行統計,如圖2,可看出IPC分類的專利篇數極端不平均,以G部分類號為例,專利篇數低於100篇的分類號共有11448個,100篇以上的分類共有3796個,因分類號要有一定篇數的的專利才能代表此分類的特性,我們選定有100篇以上專利的分類號進行關鍵字擷取,總共有27845個分類號,如圖3。
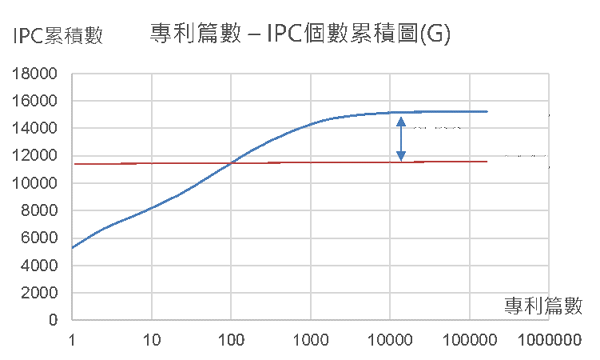
圖2 專利篇數與IPC個數累積圖(G部分類號)
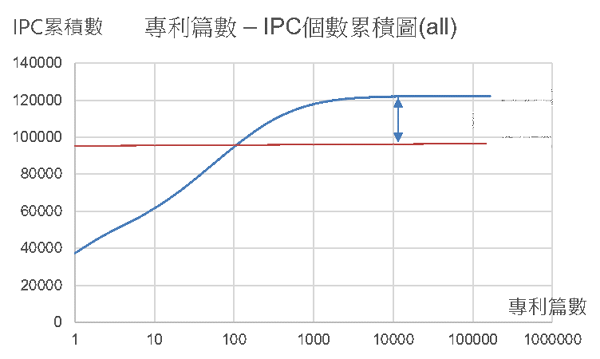
圖3 專利篇數與IPC個數累積圖(全部IPC)
我們使用一個類神經網路的分類模型,如圖4,輸入是一個字詞,中間經過一個詞嵌入層,輸出是對應的分類號,模型示圖可參考下圖。此處用的輸入詞典在前處理階段已對所有的專利進行解析,使用詞聚合規則加上維基百科條目與Microsoft Academic Topics[8]做為預設詞典,最終共篩選出詞集規模約500萬字,再使用此詞集對所有專利建立Word2Vec模言模型[9],並將此預訓練模型其做為分類模型詞嵌入層的輸入,在分類任務訓練階段將其固定住。然而IPC分類模型在實際訓練時,會發生類別數量過多、類別專利數量不平衡及資料量過大的問題,造成模型無法正常訓練,我們採用以下幾個解決的方法。
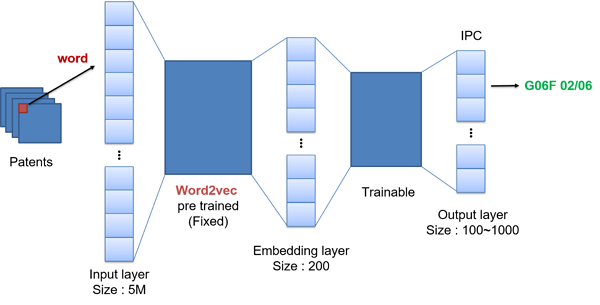
圖4 IPC分類模型架構
分組訓練
將資料依IPC分類號進行分組,以減少每組的IPC分類號個數,再對每組個別建分類模型進行訓練。分組方式可為兩個階段,第一階段依主部(Section)進行分組,計有A~H共8個組,依主部分組的好處是可以將主題內容差異大的IPC分類號事先分開,如果將主題差異大的專利一起進行分類訓練,模型不容易找出類別代表性的關鍵字來區分IPC類別,因為簡單的關鍵字就可以區分不同領域的類別。第二階段分組可依IPC分類專利篇數分組,舉例而言,將專利篇數100~1000、1000~10000、超過10000篇的IPC分類號個別分組,將專利篇數相近的IPC分類號放在一起訓練也有助於解決資料不平衡的問題。
上取樣(Oversampling)
將專利資料分組後仍存在資料不平衡的問題,例如專利篇數100~1000這組的IPC分類號,訓練資料量仍可能會有高達10倍的差異,而擁有較多專利的IPC號類別,其類別關鍵字在訓練時會較為強勢,排擠了較少專利的IPC類別關鍵字的發揮空間,解決的方法可以使用上取樣(Oversampling),隨機地複製少數類別的數據,使得整體類別資料平衡。
Subsampling
對訓練資料進行抽樣可加速訓練的過程,並且透過調整抽樣機率處理詞彙出現機率差異過大的問題,讓高頻詞具有較低的抽樣機率,我們採用word2vec [9]中所使用的subsampling方法,讓專利中字詞被抽樣到的機率如以下公式
其中f(W_i )代表字詞W_i出現的頻率,而t是一個固定的常數,通常可設定為10^(-5),藉由subsampling可加速訓練,更可提升模型分類的準確度。
反覆訓練
雖然經過分組訓練減少類別數量,但每組的類別數量仍偏多,使得模型分類表現在每個類別上有明顯差異,透過保留分類效果較佳的類別,並將分類效果差的類別歸為一組重新訓練,反覆操作此步驟直到大部分的類別都能找到具有分類效果的關鍵字群。整體的分群訓練流程可參考圖5。
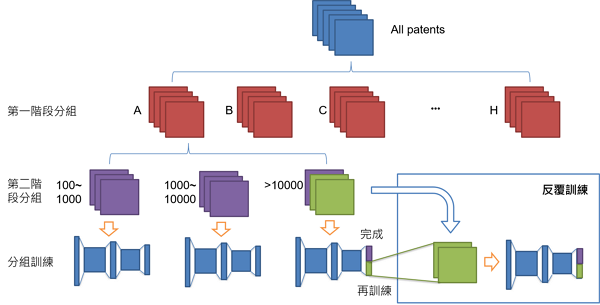
圖5 IPC關鍵字擷取訓練流程
專利分析應用服務
工研院資通所目前致力於專利智慧檢索及專利地圖分析服務,部分研究成果也公開於網路平台,歡迎多加利用並提供寶貴意見,目前主要服務內容如下。
專利關聯關鍵字查詢服務
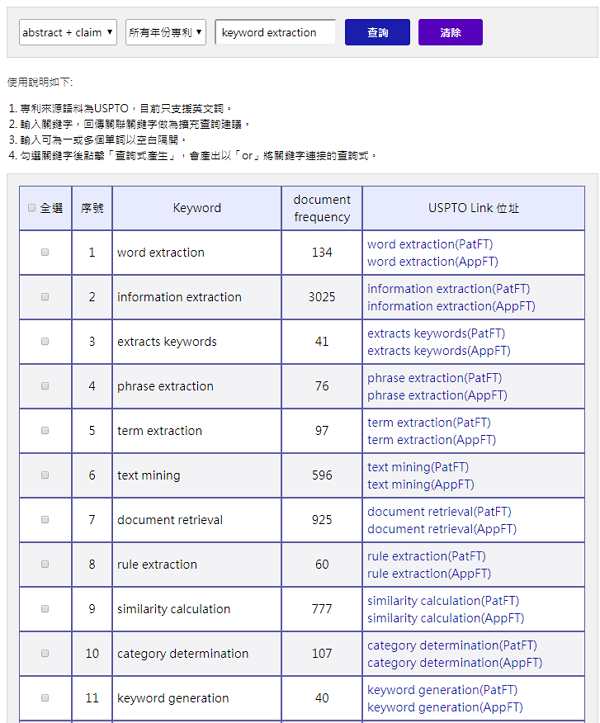
蒐集百萬個專利關鍵字,並計算關鍵字之間的相關程度,用於專利檢索分析時,找尋同義關鍵字或相關關鍵字,服務網頁如下網址,服務介面如圖6所示。
https://tap.itri.org.tw/patentAnalysis/search.aspx
圖6 專利關聯關鍵字服務介面
IPC分類關鍵字查詢服務
實作本文所提出之專利國際分類號關鍵字擷取方法,可找出IPC分類號的代表性關鍵字,輸入IPC分類號,如G10L 15/18,可顯示此分類號的專利篇數、分類階層中文說明,以及依重要性排序的類別代表性關鍵字,服務網頁如下網址,服務介面如圖7所示。 https://tap.itri.org.tw/patentAnalysis/ipc_search.aspx
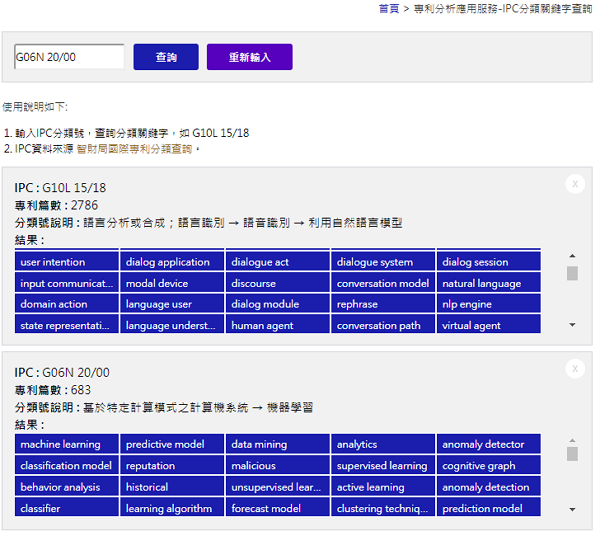
圖7 IPC分類關鍵字查詢服務介面
結論
本文提出一種基多文件分類之IPC分類關鍵字擷取方法,用以輔助專利檢索及專利地圖分析的工作。未來工研院資通所將持續協助技轉中心投入建置AI協作專利分析共用平台,整合人工智慧之資訊技術,並逐步擴充人工智慧學習之領域技術類別及深度,協作執行專利分析布局工作,包括專利技術分類及專利檢索等工作,以提升專利分析布局之品質與效率。
參考文獻
[1] 張展誌, 劉智遠, “以專利布局支持新技術產業化”, 智慧財產權月刊, VOL. 224, pp.6-21, Aug.2017.
[2] 許耀華, “專利分類系統及其應用”, 智慧財產權月刊, VOL. 68, pp.5-21, Aug.2004.
[3] IPC國際專利分類查詢, https://topic.tipo.gov.tw/patents-tw/sp-ipcq-level-101.html
Mihalcea R and Tarau P 2004 Textrank: Bringing order into texts. In Proceedings of EMNLP 2004 (ed. Lin D and Wu D), pp. 404 –411
[4] Mihalcea R and Tarau P, “Textrank: Bringing order into texts”, In Proceedings of EMNLP 2004 (ed. Lin D and Wu D), pp. 404 –411
[5] Rose, S., Engel, D., Cramer, N., Cowley, W.: Automatic keyword extraction from individual
documents. In: Text Mining: Theory and Applications (2010)
[6] Campos R., Mangaravite V., Pasquali A., Jorge A.M., Nunes C., and Jatowt A. (2018). YAKE! Collection-independent Automatic Keyword Extractor. In: Pasi G., Piwowarski B., Azzopardi L., Hanbury A. (eds). Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26 – 29). Lecture Notes in Computer Science, vol 10772, pp. 806 - 810..
[7] SALTON,G.AND BUCKLEY, C. 1988. Term-weighting approaches in automatic text retrieval. Inform. Process. Man. 24, 5, 513-523
[8] Microsoft Academic Topics, https://academic.microsoft.com/topics
[9] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013b. Distributed representations of words and phrases and their compositionality. In NIPS, pages 3111–3119.
相關連結: 回182期_AI智慧應用專輯