近十年來隨著資訊技術的進步以及企業對於數據價值逐漸有所認知,企業內部開始累積各式各樣的數據。然而現實的狀況是:1)數據分散在各個不同的數據庫;2)即便資訊已統整至一數據庫,卻不知如何應用數據產生對企業有用的正向價值;特別是後者,即是商業智慧(Business Intelligence, BI)要面對的重要課題。智慧零售就是透過商業智慧分析,從這些多而看似瑣碎的大批數據中,幫助零售業者了解其行銷的趨勢與盲點,找出顧客隱藏的資訊與擬聚顧客的方式,進而找到合適的商品銷售與活動設計,藉由個人化生產/行銷使企業得到更大的獲利空間。
智慧零售/行銷與商業智慧的連結與趨勢
商業智慧的發展從1980年代啟始,是早前決策支援系統的技術延伸,用以支援企業管理與行銷策略的制定。技術上而言,商業智慧是指透過資料蒐集、資料倉儲、資料探勘、數據分析等技術手段,將企業所蒐集到的客戶消費、營銷成本等數據轉為有價值的資訊,提供給企業經營管理人員輔助決策資訊的「智慧」化系統。由此可知,商業智慧涵蓋多種面向,實務上需由企業主聚焦特定目標,再由資料分析人員探索數據的特質與面貌;要注意的是,沒有目標的商業智慧分析只會帶來資訊系統的大幅膨脹,對解決企業問題無法帶來改善。
精彩內容
1. 智慧零售與行銷兩大指標-產品與個人化數據分析
2. 智慧零售之顧客管理應用-計算客戶終生價值(CLV)
3. 客戶偏好商品推薦模型案例分享
4. 客戶分群與客戶價值案例分享
5. 精準行銷兩大關鍵技術 客戶特性分析與商品推薦 |
智慧零售與行銷兩大指標-產品與個人化數據分析
在介紹智慧零售之前,先介紹與行銷有關的概念,其中客制化(customization) 與個人化(personalization)行銷是商業智慧分析所要追求的重要目標之一。客制化與個人化並不相同,從工業生產的歷史發展流程來看,從最早的工業化大量生產,逐漸演進到對客戶/消費者做適當分群所產生的客制化生產,近期再發展到聚焦於「個人」行為數據所衍生的個人化生產/行銷。Aberdeen Group的調查顯示,75%的消費者會因品牌有做個人化行銷、優化消費者體驗,因而對品牌產生正面印象,這也突顯個人化行銷的重要性。要達到個人化行銷,有兩大方向提供參考:1)以產品為主的數據分析;2)以個人消費特性為主的數據分析。 以產品為主的數據分析,主要目標為挖掘眾多消費記錄中,有哪些商品會有共同購買的特性(例如麵包與牛奶、泡麵與啤酒)、或是時間順序上有前後關係(例如購買筆電後有超過70%的機率在兩個月內購買轉接線材或隨身碟);對應的技術包含資料分類、分群、關聯性分析與序列樣式分析。 以個人消費特性為主的數據分析則聚焦於個人,從個人的消費記錄分析習慣性的消費商品(組合)類別、消費頻率、時間、地點等資訊,進而設計個人化的行銷活動;實務上會特別著重商品組合的特性,即所謂的「配方」;透過商業智慧分析,企業可以根據更廣泛的資料以及更新的分析技術來找出客戶偏好特性,同時利用客戶分群來定義不同的個人化配方。此配方不僅能達到個人化行銷推薦的目的,藉由商品組合的設計,亦能避免相同配方被其他人重複使用的損失。
智慧零售之顧客管理應用-計算客戶終生價值 ( CLV )
除了對產品與個人銷售記錄進行各種商業智慧指標的計算以外,商務應用上另一重要概念是計算客戶的價值。粗略而言,企業80%的營利來自於20%的客戶(每種企業的特性不一,但大多有此特性);因此計算客戶價值是商業智慧的優先要務之一。客戶終生價值(Customer Lifetime Value, CLV)是用來評估客戶價值的指標,基本計算公式如下:
其中 AC 為客戶的取得成本,M_i 為客戶在第 i 段期間消費所產生的利潤,C_i 則在第 i 段期間行銷/服務此客戶所付出的成本。一般來說,所謂的終生並非真的是「終生」,而是公式中的「期間」長度,實務上會依據產業的不同而有所差異;以零售業來說,通常會以三到五年的期間(預期銷售/服務數據)來計算 CLV。
值得注意的是,CLV 並非都是正值,當花費在該客戶的取得成本、行銷/服務成本大於客戶帶來的利潤,便會出現負 CLV 數值的客戶。企業必需針對不同 CLV 與目前的客戶利潤,設計不同的行銷及客戶管理策略,如圖1所示。
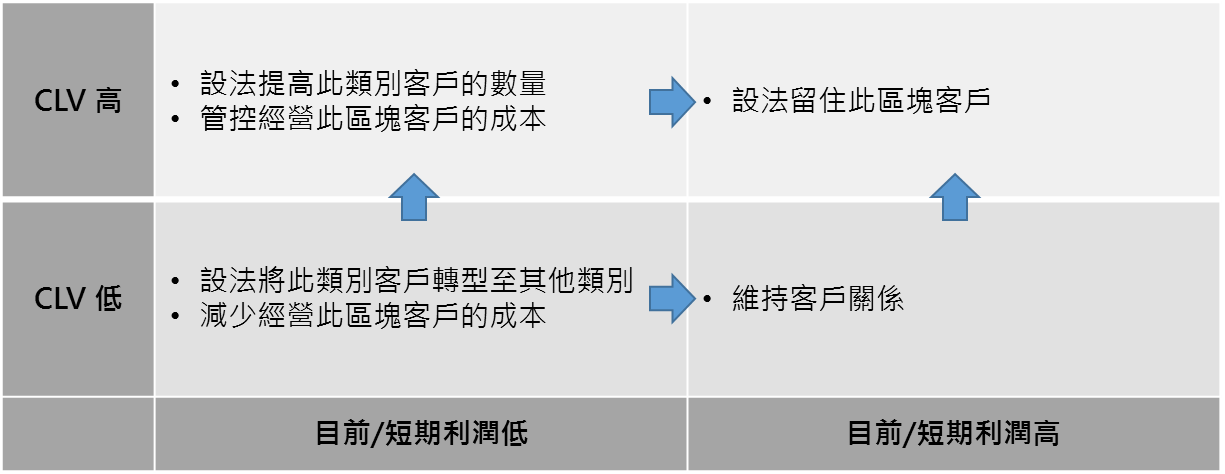 圖1 不同客戶價值群體之行銷與管理策略
圖1 不同客戶價值群體之行銷與管理策略由於資料蒐集、資料倉儲、資料探勘、數據分析等技術的進步,配合新的機器學習演算法,可找出客戶隱藏的偏好特性,進一步利用大數據將客戶自動分群,可使企業可以重新定義出不同構面的客戶價值。
客戶偏好商品推薦模型案例分享
智慧零售趨勢中,針對個人化商品銷售部分,商業智慧要能提供的就是個人化配方。若從另一個方向-以商品的角度來思考,即是商品推薦模型;方法上可從大量客戶消費相關資訊中萃取出訓練參數/特徵,並利用機器學習方法建置此模型。
1. 客戶消費行為特性參數設計
在零售消費市場,用來描述使用者消費行為特性的指標眾多,除了基本消費金額、次數、頻率、時段、地點(門市/通路)等特徵參數外,以下簡單介紹兩個常用的 CAI 與 NES 表現客戶活躍度與動態的指標。 顧客活躍性指標(Customer Active Index, CAI),是將每筆購買期間依時間遠近給予權重,越晚(近期)發生的購買期間給予較高的權重,也就是計算加權平均購買期間來代表顧客活躍程度,參考公式如下:
CAI 指數較高(CAI>0),表示在計算時間範圍當中每次的交易間隔天數越來越少,可說明其顧客與企業的關係越來越緊密;因此,透過 CAI 指數,可以看到在計算時間範圍有類似交易次數的兩位顧客,透過交易時間的不同,展現出其與企業緊密與否的關係。由下圖可看出甲顧客近期的客戶活躍度較乙顧客高;計算甲、乙的CAI指數(CAI甲> CAI乙),可透過數值明確表示兩者的活躍度。
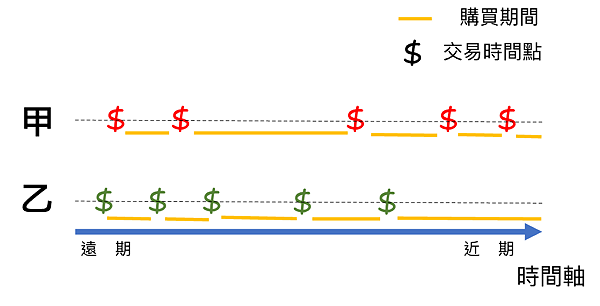 圖2 甲乙兩位顧客同期間各交易五次,交易次數相同,CAI 指數不同。
圖2 甲乙兩位顧客同期間各交易五次,交易次數相同,CAI 指數不同。顧客動態(NES)則是另一個用來表現客戶活躍特性的指標,其中N、E、S分別是:N(新顧客)、E0(主力顧客)、S1(瞌睡顧客)、S2(半睡顧客),以及喚醒機率低於10%的S3(沉睡顧客)。為了即時掌握顧客的變動性,根據消費者實際交易數據演算,配合資料更新進行動態修正,可產生企業內部顧客分群的上述五大標籤。隨著顧客沉睡度愈來愈深,品牌能夠有效喚醒的機會愈低,喚醒成本也相對將大幅度增加。利用 NES 標籤可找出顧客動態,進而作出不同客群的對應處理。
此外,透過增加更多資訊,我們能夠看得更清楚顧客行為的輪廓。例如透過引進外部資料,可以找出隱藏的可用資訊:像是大數據資料中顧客消費的門市與地址資訊,透過引入地區特性的外部資料,找出客戶所在地的地區特徵,如人口密度、商業區/文教區/住宅區等資訊;而日期以及時間等資訊,可以引入天氣資料,找出客戶傾向在哪種天氣狀況下進行消費與客戶偏好的天氣相關特徵。
2. 設計建構商品推薦模型
確認了有效的特徵參數之後,機器學習/深度學習的分析技術,則可進一步協助企業優化其產品推薦的精準度,例如:新推出的商品該優先投遞給哪一些客戶?方法上可根據要推論的目標、以及輸入參數中各事件的發生是與時間順序無關或相關的特性採用不同演算法;例如近年來數據分析比賽中冠軍選手慣用的分析方法—極限梯度提升演算法(XGBoost),以及深度學習中的長短期記憶演算法(LSTM)來進行推薦系統的模型訓練。評估模型優劣則可用常見精確率 (precision),召回率(recall)以及 F1-measure等指標。
不同的模型常會在不同的評估指標間互有優劣,因此在實務上,瞭解企業在意的商業特性至關重要,工程或資料分析人員需明確釐清該商業特性反應到哪一種評估指標,例如高precision之模型所產生的推薦名單,其名單長度可能相對較短;高recall之模型所產生的推薦名單數量較多,但整體的命中率可能相對較差。由此可知,在專案進行的過程中深度瞭解企業需求並與之溝通,才能探索出符合對方預期的模型並產出結果。此觀點不僅適用於零售業的消費分析,擴展至其他如金融業亦是如此。
客戶分群與客戶價值案例分享
智慧零售針對顧客相關的部分,商業智慧要能提供的就是客戶自動分群與找出客戶價值。對應在系統面,即為兩個機器學習模型,一個是客戶自動分群的模型,另一個是客戶價值的模型。兩個機器學習模型的訓練參數可以是前述提到的客戶消費/行為相關特徵。
1. 客戶分群
首先來談客戶自動分群模型。在實際的狀況下,專家們會利用經驗將顧客分成他們定義好的組別,然而隨著機器學習的方法日漸普及,機器學習的演算法能從數百個以上的維度觀察出資料的特性,並予以分組。因此在沒有專家經驗的狀況下,憑著機器學習的方法就可以將資料自動分組,或是能觀察到從以前經驗沒能得知的隱藏模式。藉由歷史客戶消費相關資料與特徵參數,透過演算法找出最適的分群(實務上,在自動分群後會再與該領域專家討論各群特性與商務連結的意義與價值);確認該群組的意義及重要性後,即可利用機器學習方法訓練預測模型,意即透過(新)顧客在每個時間區段的消費行為數據,預測該顧客所屬群體與此顧客的特徵(族群變化趨勢)。自動分群結果不僅可呈現給企業的行銷人員作參考,也可以納入另一個機器學習模型當作特徵參數,以計算顧客的終身價值或作為個人化商品推薦的分群基礎。
2. 客戶價值
前述傳統客戶終生價值(CLV)的計算法是利用客戶過去的消費力作為指標,而近期使用機器學習的方法可將許多不同的參考指標當作特徵參數納入訓練產生模型來計算客戶價值。此次分享的系統案例採用之前提到的,利用購買時間遠近所產生的 CAI 與 NES 以及 RFM(Recency, Frequency, Monetary value)指標來協助作為客戶價值的判斷。
前兩者上述已介紹過,RFM 則是通過客戶的近期購買行為、購買頻率以及消費力這三項指標來描述該客戶的價值狀況。RFM 指標不只參考客戶創利的貢獻度,亦強調利用客戶行為來區分客戶;從 RFM 裡也可以利用自定義的閾值分出 8 種客戶價值類型,分別是重要價值客戶、重要喚回客戶、重要深耕客戶、重要挽留客戶、潛力客戶、新客戶、一般維持客戶以及流失客戶,如表1。
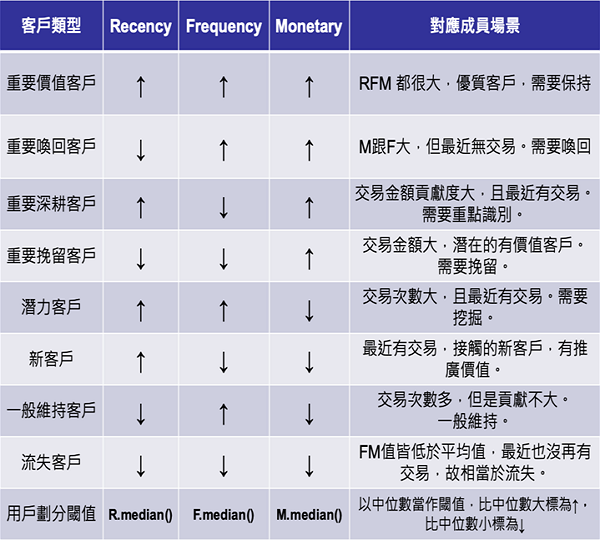 表1 RFM的8個客戶群組
表1 RFM的8個客戶群組以上三種指標用於客戶價值模型的參數,可使模型即時掌握顧客的變動性;這樣模型不僅根據消費者實際交易的數據做演算,也能配合資料更新進行動態修正。其他適用於模型的客戶行為相關特徵參數同樣能透過大數據發掘出來;像是之前提到的客戶偏好消費時段、通路以及地點,可由數據資料統計而來,這些特徵皆可納入機器學習模型當作特徵參數以計算顧客的終身價值。
精準行銷兩大關鍵技術 客戶特性分析與商品推薦
在新零售時代,第一步要做的,就是「以心為本」,充分蒐集並利用數據,分析透視消費者的行為模式。了解消費者在想什麼、需要什麼,才能在越來越擁擠的市場中脫穎而出,而有機會成長、獲利、擴張。因此在商業智慧系統之中,我們可以藉由顧客消費紀錄,透過多維度資料交叉分析,萃取客戶偏好特性與潛在商機,協助行銷人員由消費者、環境、商品或複合條件作為分群主體,快速正確鎖定客群,並可透過個性化的觸及,在適當時機投放優惠給鎖定之客群,提高觸及轉換率;同時發展效益追蹤機制,快速取得行銷投放效益,了解影響投放效益之不同面向因素,而數據分析正是支援此系統能達到精準行銷、預測行銷活動成效的關鍵。
參考文獻
- Fader, P. S., Hardie, B. G., & Lee, K. L., “RFM and CLV: Using iso-value curves for customer base analysis”, Journal of Marketing Research, 42(4), pp.415-430, 2005.
- Farris, P. W., Bendle, N., Pfeifer, P., & Reibstein, D., “Marketing metrics: The definitive guide to measuring marketing performance”, Pearson Education, 2010.
- Fripp, G., “Marketing Study Guide”, 2014.
- Jeffery, M., “Data-Driven Marketing”, John Wiley & Sons Inc., 2010.
- Witten, I. H. and Frank, E., “Data Mining: Practical Machine Learning Tools and Techniques”, 2nd ed., Elsevier, 2005
- 米可。老客户召回策略-RFM模型及應用,http://www.woshipm.com/operate/666103.html, 2017.
相關連結: 回178期_智慧零售與照護專輯