工業技術研究院 資訊與通訊研究所 蔡昆憲 陳炫良 葉泰麟 林國弘 董明智 陳耀華 盧俊銘

在嵌入式微裝置運行基準效能,分析結果可知AI運行軟硬體系統對整體效能的影響。
近來人工智慧(AI)受到廣泛的研究與應用,從雲端伺服器、邊緣端伺服器、桌上型電腦、手機、嵌入式系統、IoT裝置等都可以看到AI的應用身影。由於AI的應用領域廣泛,如時間序列與預測、圖像處理、動態影像處理、語音處理、自然語言等,因此在應用需求下,如何使選用的AI的軟硬體平台達到最佳效能變成為一項非常重要的工作。
隨著AI應用快速拓展,現有通用型處理器如AI運算加速器的種類繁多,如中央處理器(CPU)、繪圖加速器(GPU)在處理如深度學習神經網路等運算上的效能,無法滿足需求,或需額外新增人工運算指令架構支援,使得各種新的AI運算加速器架構正在源源不絕浮現。如向量處理器(VDSP)、張量處理器(TPU)、特用運算器(ASIC)等。為了支援各AI運算加速器,在軟體方面也有各式各樣的AI軟體框架,著名的如TensorFlow、CNTK、Theano、Caffe、Keras、Torch、Sci-kit Learn等等。
基於上述,多樣化的AI硬體運算器與各式的軟體框架,AI系統效能評估基準需要包含硬體加速器效能與軟體系統效能,如此方能為AI系統應用之軟硬體系統平台整合效能進行合理與需求性的評估。
精彩內容
1. MLPerf
2. MLPerf Tiny
3. 實例研究
4. 效能模型結果 |
MLPerf
MLPerf是由學術界、研究實驗室和業界人士組成的AI聯盟,以加速AI創新發展為目標使命,通過3個領域的開放協作工程來滿足新興機器學習行業的需求,並基於公平準則、可重複實用的測試基準,為硬體、軟體和服務訓練與推論效能提供中立評估,且全部在預定條件下執行,以保證效能測試的公平性。MLPerf透過定期進行新的測試,鼓勵創新開發並增最尖端AI技術的全新工作負載,持續進化引領AI的發展。
因應AI廣泛的應用領域使用不同的軟硬體系統平台,MLPerf分別為不同的軟硬體系統發展不同的效能基準技術MLCommons,根據AI技術分為訓練(Training)與推論(Inference)兩類。其中Training的測試基準對象為高效能運算系統(High Performance Computing),如高效能運算系統伺服器。Inference的測試基準對象則分別為資料中心(Data Center)、邊緣運算電腦系統(Edge)、手機(Mobile)和微裝置(Tiny)。
基準測試目標在於評估系統使用指定的數據集達成指定品質要求下,完成訓練模型(Training Model)所花費的時間。對於推論效能測試基準而言,以下將分別針對資料中心、邊緣運算電腦系統、手機說明所使用的數據集與品質目標。 高效能運算系統伺服器在科學應用上有兩類測試基準:氣候分段(Climate Segmentation)與宇宙學參數預測(Cosmology parameter prediction),所使用的數據集與品質目標如下表:
高效能運算系統所使用的數據集與品質目標如下表:
表1 效能運算系統伺服器數據集與品質目標

資料中心系統所使用的數據集與品質目標如下表:
表2 資料中心系統數據集與品質目標
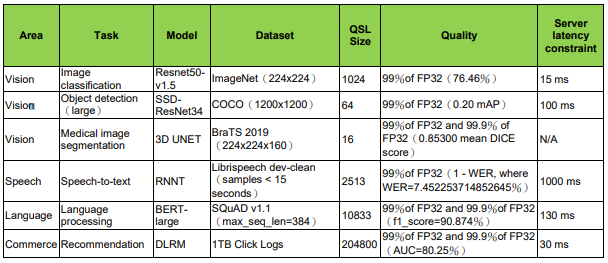
邊緣運算電腦系統所使用的數據集與品質目標如下表:
表3 邊緣運算電腦系統數據集與品質目標

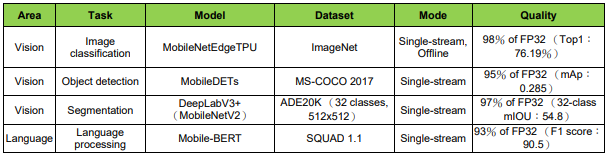
手機系統所使用的數據集與品質目標如下表:
表4 手機系統數據集與品質目標
為代表各種應用環境(Use Cases)與公平測試起見,MLPerf 官方為測試環境設計 4 種情境(Scenario),分別為 Single Stream、Multiple Stream、Server 和 Offline。Single Stream 代表意義為一個終端運行一個任務的情境;Multiple Stream 代表意義為一個終端同時運行多個任務的情境;Server 代表意義為伺服器的實時性 能的情境和 Offline 代表意義為不在線的伺服器的情境,下圖擷取自 MLPerf 釋出資 料文件,4 種情境如下圖所示:
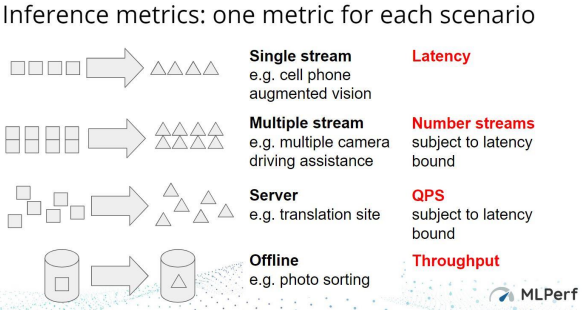
圖1 推論情境
4種情境的測試基準品質標準如下表所示:
表5 測試基準4種情境

LoadGen功能為負載產生功能為是可重複使用的軟體模組,能有效公平的量測推論系統效能。其運作流程如下:
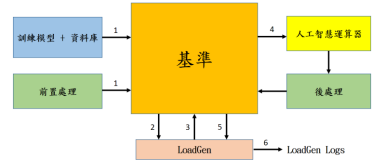
圖 2 推論基準流程
步驟1:基準讀進訓練模式與數據集,進行前置處理。
步驟2:基準根據數據集制定sample IDs並分配給LoadGen。
步驟3:LoadGen根據sample IDs產生4種情境(scenario)的詢問(query)的任務。
步驟4:基準將AI運算需求指派給AI運算器。
步驟5:AI運算器將運算結果經過後處理返回LoadGen。
步驟6:LoadGen輸出紀錄(Logs)並進行分析。

圖3 開放分區與封閉分區
MLPerf基準分為兩種測試分區:封閉分區(Closed Division)和開放分區(Open Division)。封閉分區是AI運算器將獲得預先訓練的AI網路模型和預先訓練的權重。在使用的精度等級方面,晶片公司在量化方面仍具有一定的靈活性,但是在封閉的分區,解決方案仍必須達到數學上的等效性,禁止重新訓練AI網路模型,其目的在於測試平台能否很好地執行預訓練好的AI網路模型。開放式分區則允許重新訓練AI網路模型及進行更廣泛的量化工作,鼓勵AI解決方案應用最新最佳的方式,加速AI在多方面的進展與創新。
上圖左側為MLPerf參考實作(Reference Implemenation),從上到下,開放分區如圖藍色部分,為AI網路訓練階段,以取得模型(Model),包含AI網路結構之調整(Pruning);封閉分區為推論階段如圖綠色部分,由輸入已訓練模型透過推論框架(Inference Framework)及編譯(Complier)得到AI網路運算核心(NN Compute Kernels),並將此核心分配給下層平台中的運算處理器,可以是中央處理器(CPU)、繪圖加速器(GPU)和運算加速器(Accelerator)等等,以完成運算回傳結果至推論框架輸出推論結果,此推論階段,MLPerf組織有詳細準則規範以供遵循。
MLPerf Tiny
人工智慧推論(inference)系統應用在微裝置端是一個非常有挑戰性的議題。微裝置是指能耗為微瓦(microwatts)到數瓦(watts)等級,資源極度受限,如CPU執行時脈、計算能力、記憶體資源等。微裝置與電腦、手機的執行環境有著天壤之別的差異。通常微裝置可以是一種IoT裝置使用電池電力維持運行,可能是麥克風、攝影機等感測裝置系統,傳輸資料量只有100kB或更少。一般而言,微裝置也各有其特定的軟體開發工具套件與軟韌體推疊。因此MPerf Tiny為在極度資源極度受限環境中執行機器學習工作負載的微裝置所設計的一套效能評估基準。
嵌入式微處理器性能測試基準聯盟EEMBC(Embedded Microprocessor Benchmark Consortium)成立於1997年是嵌入式微處理器基準測試協會,為非營利性組織,致力於為嵌入式系統創建標準基準測試。MLPerf工作小組與嵌入式微處理器性能測試基準聯盟合作開發TinyML的性能測試基準,利用了EEMBC的測試工具(EnergyRunner框架),MLPerf工作小組則是定義工作負載、規則以及性能測試基準。
- 關鍵字識別(Keyword spotting)
利用Google的語音指令資料集(Speech Commands Dataset),以DS-CNN模型進行有限詞彙的語音識別。
- 異常偵測(Anomaly detection)
利用機器以Deep AutoEncoder模型運作ToyADMOS聲音資料集,進行音訊時間序列異常偵測。
- 視覺喚醒詞(Visual wake words)
這是一個兩類別影像分類的工作負載,影像被區分為「人」或「非人」,利用MobileNetV1 0.25X模型執行視覺喚醒詞數據集(Visual Wake Words Dataset)。
- 影像分類(Image classification)
以ResNet-8模型進行CIFAR10資料集的10類別影像分類。
如同其他MLPerf性能測試基準,MLPerf Tiny推論基準也有封閉(Closed)與開放(Open)兩種分區(division),封閉分區試提供相似系統的對比性,開放分區鼓勵創新方法。
MLPerf Tiny所使用的數據集與品質目標如下表:
表6 MLPerf Tiny數據集與品質目標

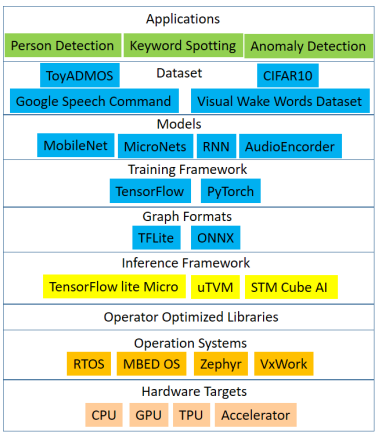
圖4 AI軟體框架
上圖說明AI軟體框架分層如下:
1.應用層(Application):從應用角度有影像分類、人員偵測、關鍵字偵測和異常偵測等。
2.數據集層(Dataset):應用層之下所使用的數據集有Google Speech Commands、Visual Wake Words Dataset、ToyADMOS和CIFAR10等。
3.模式層(Models):模式層為經過AI訓練網路結構,有Mobilenet、MicroNet、遞歸神經網路RNN和AudioEncorder等。
4.訓練框架層(Training Framework):AI機器學習系統,如TensorFlow和以Python為介面的PyTorch等。
5.圖形格式層(Graph Formats):如TFLite、ONNX等。TFLite以FlatBuffers為高效率可攜格式。優點是程式碼占用的空間較小,以及推論執行速度快,只需要少量運算和記憶體資源。ONNX是一種針對機器學習所設計的開放式的文件格式,使得不同的AI框架如Pytorch、TensorFlow等可以採用相同格式存儲模型數據交換。
6.推論框架層(Inference Framework):推論框架用來正確表達深度學習的模型,方便表達模型結構以進行推論流程,如適用於嵌入式微裝置系統的TensorFlow lite Micro、uTVM和STM Cube AI等推論框架。
7.運算函式庫層(Operator Optimized Libraires):用以將上層推論框架層所產生的運算核心連結至下層作業系統,用以完成運算核心與作業系統層級服務的對映。
8.作業系統層(Operation System):主管並控制分配執行下轄硬體、軟體資源以完成服務工作的系統軟體程式,嵌入式作業系統如實時作業系統(RTOS)、MBED OS、Zephyr和VxWork等。
9.硬體層(Hardware Targets):用以執行作業系統服務包含AI運算硬體,如中央控制單元(CPU)、繪圖運算加速器(GPU)、張量運算處理器(TPU)和運算加速器(Accelerator)等。
EEMBC基準模式 EEMBC嵌入式微處理器性能測試基準有兩種模式:效能模式(Performance Mode)與能耗模式(Energy Mode)。硬體連接示意圖如下:
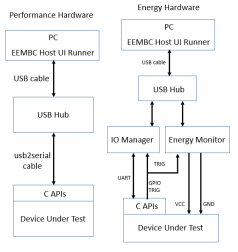
圖5 效能模型與能耗模型
- 效能模型
效能模型如上圖左側分別由電腦(PC)、USB集線器(Hub)和待測硬體(Device Under Test)所構成。電腦運行EEMBC Host UI Runner,透過USB集線器傳送命令給待測硬體,由待測硬體完成工作並將結果回傳至電腦,由EEMBC Host UI Runner負責分析相關效能資訊。
- 能耗模型
能耗模型如上圖右側分別由電腦(PC)、USB集線器(Hub)、輸出入管理裝置(IO Manager)、能耗監控設備(Energy Monitor)和待測硬體(Device Under Test)所構成。電腦運行EEMBC Host UI Runner,透過USB集線器傳送命令、處發訊號給輸出入管理裝置與能耗監控設備,以通知待測硬體與啟動能耗監測,待測硬體完成工作並將結果回傳至電腦,由EEMBC Host UI Runner負責分析相關效能與能耗資訊。
- 模型差異
效能模型與能耗模型差異點如下:
表7 效能模型與能耗模型差異

- 量測指標
1.延遲(Latency)
一次流程為下載輸入,載入輸入張量(input tensor),執行推論至少10秒並且10迭代。執行五次流程,量測每秒的推論數,以五次流程的中位數為代表分數。
2.正確率(Accuracy)
對整個有效輸入做單一次推論並收集輸出結果之正確機率,針對單一次個別結果計算Top-1百分比和AUC結果,此結果必須符合每一AI網路模型需符合其所訂定的正確率。
3.能耗(Energy)
測試流程同延遲方式,但針對每秒推論數量測其能耗,計算每次推論所需之能耗焦耳。以五次流程能耗的中位數作為代表分數。
- 實例研究
本論文實例採用硬體NUCLEO-L4R5ZI-P並使用效能模型基準進行研究。開發版主要組成規格如下:ARM Coretex-M4 32位元120MHz微處理器(MCU)、浮點運算器(FPU)、640KB SRAM、2MB Flash、ST-LINK/V2-1 debugger/programmer。
1.硬體安裝

圖6 效能模型硬體連接示意圖與實體圖
如上圖,使用MicroUSB線連接電腦(PC)與NUCLEO-L4R5ZI-P開發版。電腦上安裝linux作業系統與EEMBC Benchmark Framework之Host UI Runner。
2.軟體框架
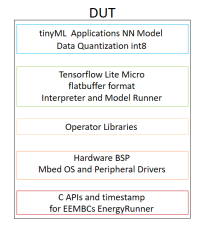
圖7 AI微裝置軟體框架
開發版上的軟體架構如上圖,簡介此軟體框架包含應用層(tinyML Applications)、TensorFlow層(Tensorflow Lite Micro)、運算程式庫層(Operator Libraries)、作業系統層(Hardware BSP)與介面層(C APIs and timestamp)。其中作業系統使用Mbed OS,由ARM和它的技術夥伴協同運作開發。開發版的參考實作實例可由MLPerf Tiny的github下載取得。並在電腦linux系統下完成編譯以獲得佈署二進制檔案(binary file)並安裝於開發版上。請參考下圖軟體編譯結果,其中包含anomaly_detection.bin、image_classification.bin、keyword_spotting.bin與person_detction.bin。

圖8 軟體編譯結果
3.實例執行
電腦端運行EEMBC Host UI Runner以量測開發版運行AI應用工作負載時所產生之延遲與其正確率,完成效能模型基準測試。運行如下圖Host UI Runner所示。

圖9 Host UI Runner執行結果-每秒推論數

圖10 Host UI Runner執行結果-正確率
效能數據
表8 效能數據
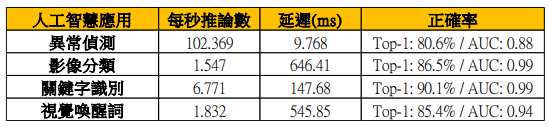
表9 MLPerf Tiny效能數據
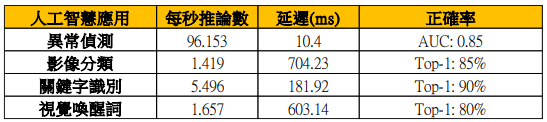
表9為MLPerf Tiny v0.5公布之參考數據。表8顯示實例執行下效能基準測試數據,分別是:(1)異常偵測應用在正確率Top-1:80.6%與AUC:0.88的情況下,每秒推論數為102.369次(inference/second),延遲為9.768 ms;(2)影像分類應用在正確率Top-1:86.5%與AUC:0.99的情況下,每秒推論數為1.57次(inference/second),延遲為646.41 ms;(3)關鍵字識別應用在正確率Top-1:90.1%與AUC:0.99的情況下,每秒推論數為6.771次,延遲為147.68 ms;(4)視覺喚醒詞應用在正確率Top-1:85.4%與AUC:0.94的情況下,每秒推論數為1.832次,延遲為545.85 ms。表8顯示在NUCLEO-L4R5ZI-P開發版上,由應用端至硬體執行端完整執行MLPerf TinyAI應用所得之效能基準數據。AI進行預測時,Top-1為機率最大的結果為正確答案,才視為正確。AI分類器使用AUC(Area Under Curve),為計算ROC(Receiver Operator Characteristic)曲線下面的面積,AUC數值越高則分類器正確率會越高。在此實例執行中各項正確率皆提升的條件下,各項效能增進分別為(1)異常偵測增進6.5%;(2)影像分類增進9%;(3)關鍵字識別增進23.2%;(4)視覺喚醒詞增進10.56%。
結論
本論文探討低功耗嵌入式微裝置運行AI應用的效能基準,從AI end-to-end的角度,評估AI應用軟硬系統整體校能,遵循MLPerf Tiny推論規則,運行效能基準以量測推論延遲(Latency)與統計其既定品質下的正確率。
從AI應用角度,在嵌入式微裝置運行基準效能,分析結果可知AI運行軟硬體系統對整體效能的影響,確實了解AI應用與軟硬體系統搭配之最適性,以達成最佳效能與能耗的目標。同時對於AI硬體與軟體的發展提供了實際應用的數據資料,指導各軟硬體廠家AI研發的重點努力之處。 隨著AI的廣泛應用於科學研究、醫療影像、工業生產等各方面,未來MLPerf將採納更多的不同的應用模型與數據資料,以促進AI的正確面向發展與創新。
參考文獻
[1] Colby Banbury, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, David Kanter, Sebastian Ahmed, Danilo Pau, Urmish Thakker, Antonio Torrini, Peter Warden, Jay Cordaro, Giuseppe Di Guglielmo, Javier Duarte, Stephen Gibellini, Videet Parekh, Honson Tran, Nhan Tran, Niu Wenxu, Xu Xuesong “MLPerf Tiny Benchmark”, in arXiv:2106.07596v4, 2021 Available: https://arxiv.org/pdf/2106.07597.pdf
[2] Del Barrio, V.M., Gonzalez, C., Roca, J., Fernandez, A., Espasa E. “ATTILA: a cycle-level execution-driven simulator for modern GPU architectures.” in 2006 IEEE International Symposium on Performance Analysis of Systems and Software, 2006, P. 231-241
[3] R. David, J. Duke, A. Jain, V. J. Reddi, N. Jeffries, J. Li, N. Kreeger, I. Nappier, M. Natraj, S. Regev, et al. Tensorflow lite micro: Embedded machine learning on tinyml systems. arXiv preprint
[4] V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. S. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius, C. Osborne, G. Pekhimenko, A. T. R. Rajan, D. Sequeira, A. Sirasao, F. Sun, H. Tang, M. Thomson, F. Wei, E. Wu, L. Xu, K. Yamada, B. Yu, G. Yuan, A. Zhong, P. Zhang, and Y. Zhou. Mlperf inference benchmark, 2019
[5] MLCommons [online] Available: https://mlcommons.org/en/ [6] MLPerf Tiny Inference Rules: https://github.com/mlcommons/tiny/blob/master/v0.5/MLPerfTiny_Rules.adoc [7] EEMBC UPLMark. [online]. Available: https://www.eembc.org/ulpmark/