工業技術研究院 資訊與通訊研究所 梁瑋倫、林大衛、劉志尉
強化學習(Reinforcement Learning, RL)屬於機器學習中的一個領域,探討智能體(agent)應如何基於環境(environment)而決定所該採取的行動(action),以取得最大化的獎勵(reward)。為了找出一個能獲得最多獎勵的最佳化策略(policy),智能體必須沙盤推演於採取不同行動策略下,所獲得不同的獎勵值,並揀選能於環境所具有的狀態(state)中獲得最大獎勵的行動策略來訓練(training)出神經網路中的權重(weight)。往後於推論(inference)的過程中,便能藉此權重來決定於所身處的環境狀態中應採取何種行動,方可獲得最大化的獎勵。然而一切冗長的訓練過程並非一定得要在現實世界中執行,可以藉由強大的電腦設備將現實世界中長時間的訓練過程,壓縮於模擬環境中高速進行運作。因此在訓練的過程中,外表似乎看似平靜的智能體,內心深處實則早已波濤洶湧。
強化學習
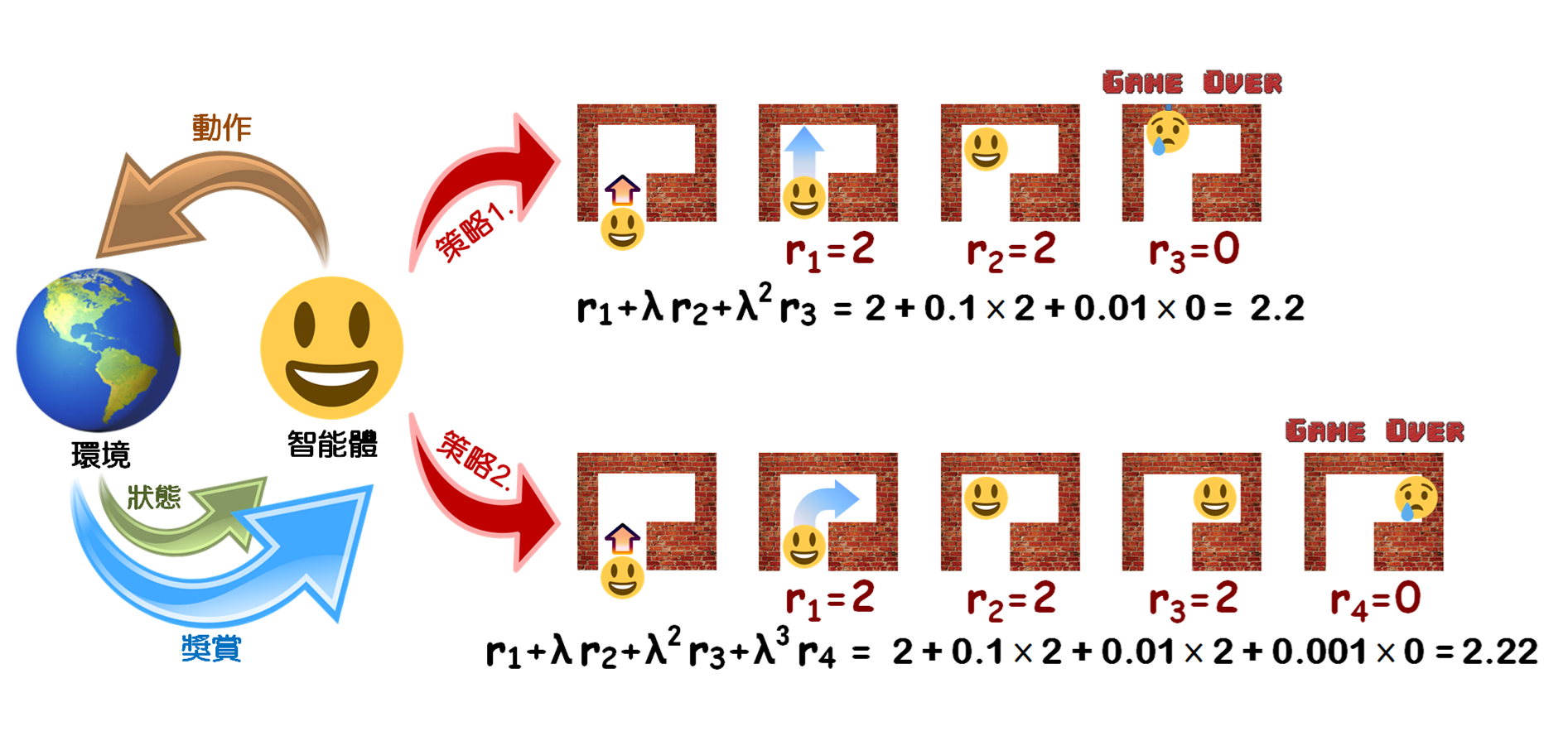
圖1 強化學習的基本概念與策略範例
強化學習指的是智能體藉由與環境不斷重複地互動,來學習應如何正確地執行一項任務。藉著讓智能體通過自我嘗試錯誤(trial-and-error),不斷反覆地試驗以便找出能獲得最大化報酬之行動的學習方法,即便智能體在缺乏人為指導的情況下,依舊能自我分析出一系列正確的決策。AlphaGo就是一個著名的強化學習案例,它是第一支能夠打敗人類圍棋世界冠軍的人工智慧圍棋軟體。
強化學習的核心邏輯如圖1左側所示,當智能體觀察其於環境所身處的狀態後,首先得於環境當中執行出一個動作,環境因接收該動作將產生狀態上的變化,並同時產生一個獎懲信號反饋給智能體。智能體會依照其所身處的新狀態,再次對於環境執行出下一個動作,環境又會因接收動作而再次產生狀態上的變化,並產生另一個獎懲信號反饋給智能體。隨後,智能體會再根據反饋的環境狀態來選擇下一個欲對於環境所作出的動作,如此不斷循環。智能體會根據一系列與環境互動過程中所獲得的不同獎勵,來研判自己在何種狀態下應採取何種決策,方可由環境中獲得最佳獎勵。
為了找出於執行何種策略下,方能獲得最佳獎勵(r),我們可利用動作價值函數(action-value function)
Qπ (s, a) = E[rt+1 + λ rt+2 + λ² rt+3 + ⋯ |s, a]
來計算在某個環境狀態(s)下所採取的策略(π)對於未來獎勵所能獲得的期望值(expect),並由此一策略來決定所需執行於該環境狀態中的行動(a)。
當中的 λ 為一個介於零跟一之間的衰減係數。當 λ 值愈小,因著未來時刻所獲得的獎勵得乘以愈高次方的 λ 值,而使得愈是未來的獎勵對於動作價值函數的影響愈小,觀察動作價值函數將可得知智能體會採取對於鄰近當前最有利的舉動,故此智能體將更加短視近利,較在乎目前可獲得的獎勵;反之,若 λ 值愈大,智能體將更加重視未來所能獲得的長期獎勵。智能體會藉由機率(ε)隨機選擇不同的動作來探索(explore)於環境中可能遇到的各種情況,並查看由環境中所得的回饋,之後再從中找到一個最佳的策略,使得所獲得的獎賞最多。譬如,圖1右側舉出一個智能體如何基於環境而作出行動,來取得最大化預期效益的例子。當中描述智能體所作出的兩種不同決策,藉由動作價值函數可從中尋找能獲取最大化獎賞的行動。當智能體走進了一個死胡同的迷宮(假設衰減係數 λ = 0.1),採取直走的策略相較於轉彎將使得智能體更早碰壁,並使得遊戲提前結束,因此轉彎的策略將獲得相較於直走更大的動作價值函數。
Q-Table是用一張表儲存在各種狀態下執行不同動作所能帶來的獎勵值,而Q-Learning(off-policy)跟Sarsa(on-policy)則是強化學習中2種依賴於Q-Table的方法。然而當Q-Table中的狀態過多時,將可能導致整個Q-Table無法裝下內存。此時可採用Deep Q-Networks(DQN)[1],藉由神經網絡來擬合整張Q-Table。以狀態、動作、權重(w)為變數的Q函數,在確定了不同時間點所處的狀態,以及所應作出的動作之後,
我們便可藉由結合「目標Q函數:r + λ maxa'Q(s', a', w)」以及「預測Q函數:Q(s, a, w)」的
「損失函數:L(w) = E[( r + λ maxa'Q(s', a', w) - Q(s, a, w) )²] 」
來針對權重進行偏微分,計算出能使損失函數最小化的權重,以如此的方式來推算出權重(註:s' 與 a' 分別是下一個時刻的狀態與動作)。
一旦將權重訓練完成,往後智能體在進行推論的時候,只要於環境中遇見類似於訓練過程中所見過的情景,便能藉由該權重推測出一系列不同時刻的狀態與動作(因觀察狀態而作出動作、再由所作出的動作導出下一個時刻的狀態,如此遞迴)來獲得最大獎勵。亦即,在進行推論的過程中,所面對到的環境狀態,若於訓練過程中已經見過,那麼所導入的權重將可使得智能體能直接判斷出:於該環境所處的狀態若要獲得最大獎賞,所應作出的行動為何。因此,便無需像在訓練過程中,得大海撈針似的,在不斷多次嘗試各種不同的動作之後,才能夠找出一個可獲得最大獎賞的行動策略。
探討於硬體中實現強化學習之應用情境
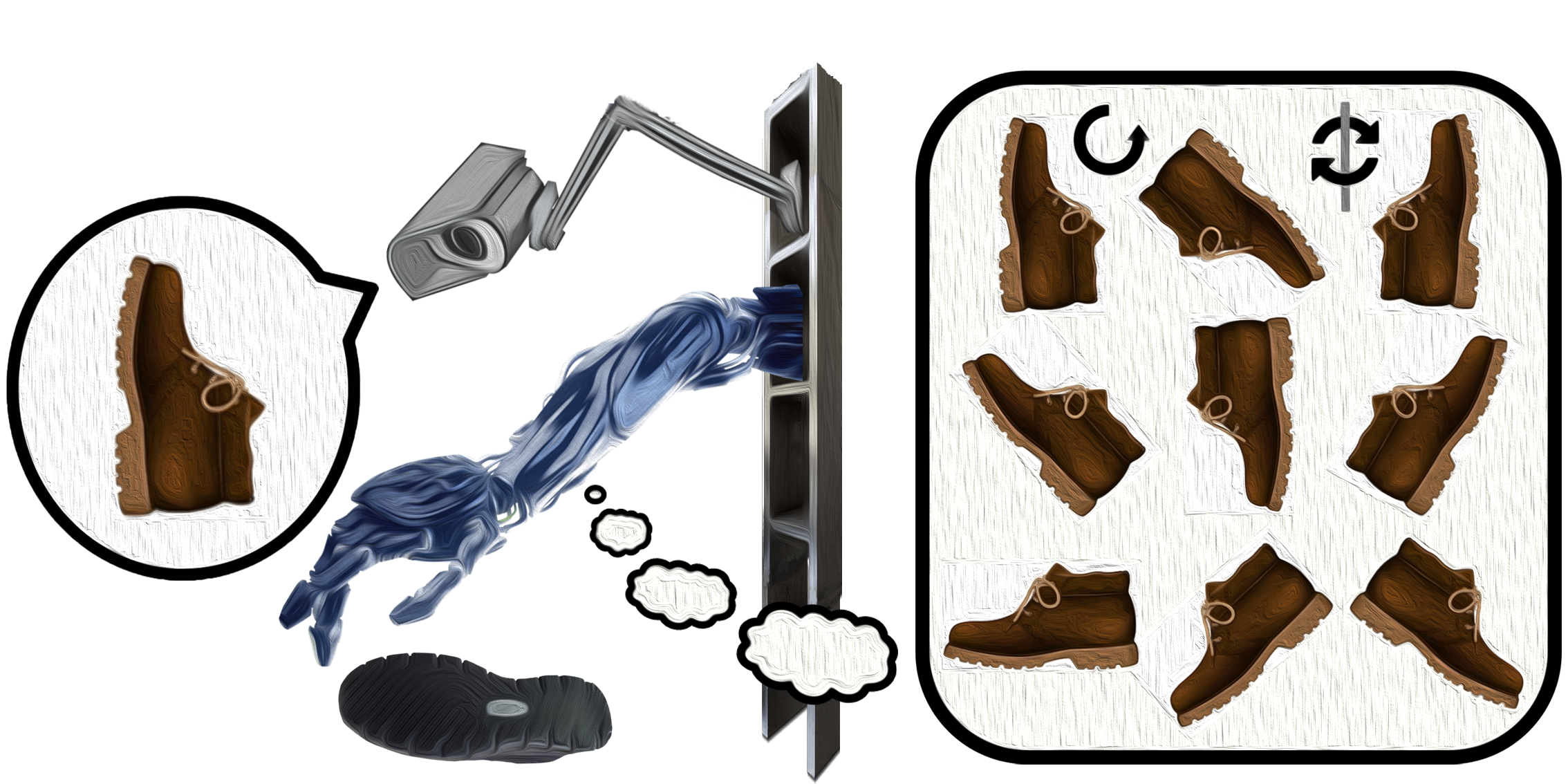
圖2 一個進行端對端強化學習的智能體,正嘗試於模擬環境中虛構出於現實世界中所未曾見過的景象
圖2描述了一個從攝像鏡頭感知環境,再由機器輸出動作的端對端強化學習智能體(範例中的智能體欲藉由一隻機器手臂將一隻鞋子給抓起)[2]。由鏡頭所捕獲的圖像輸入卷積神經網絡(CNN)來分析眼前欲抓取的物品所擺放的狀態,再來決定能順利將物品抓起以便獲得最大獎勵所應作出的每個動作,最終訓練出權重值。在推論的過程中,智能體將藉由訓練時所獲得的權重來判斷所應採取的動作為何。當智能體遇到於訓練時所曾經見過的情景時,便會不假思索地分析出當下所需採取的行動;然而,若智能體在推論的過程中,遇到在訓練的時候所不曾見過的場景,它將會感到茫然而不知所措。譬如,在訓練的過程中,我們告訴智能體:「利用機器手臂在最短的時間內將擺放為0度角的右腳鞋子給抓起,即可獲得最大的獎勵。」故此,為了獲得最大的獎勵,智能體將會以最短的時間,將擺放為0度角的右腳鞋子給抓起,並藉此訓練出權重,並且所訓練出的權重將僅能最適用於把擺放為0度角的右腳鞋子給抓起。倘若在推論的過程中,智能體藉此權重遇見一個截然不同於訓練過程中所見過的景象(譬如:遇見一隻擺放為30度角的右腳鞋子、或是一隻擺放為0度角的左腳鞋子,甚至遇見一個不是鞋子的物品),所訓練出的權重將難以於智能體中派上用場,因而無法順利地在短時間內將物品給抓起。換而言之,假使我們供給AI訓練的數據資料量若不夠多,則所訓練出的權重將無法於推理時滿足各式各樣可能遇到的情況。
倘若在訓練的過程中,讓智能體遇見過擺放為0度角的右腳鞋子、以及擺放為30度角的右腳鞋子,此兩種不同的情景。則將所訓練出的權重用於推論的時候,該權重便可順利地將0度以及30度角的右腳鞋子給抓起(當然若要求智能體抓取60度角的左腳鞋子,依舊是會強其所難)。因此,如何讓智能體在訓練的過程中,遇見各種於推論過程中可能會遭遇的情況,便成為一項不可或缺的重要條件。眾所周知,所提供給智能體訓練權重的數據量理當是愈龐大愈好。然而,於現實世界中欲打造出一個能供應龐大數據庫給智能體訓練權重的環境,將耗費極大的人力、物力;此外,還需讓智能體於此打造出的現實世界的環境來執行權重訓練,亦會使整個過程顯得曠日費時。如果這一切都能在虛構出的模擬當中執行,不僅無須耗費人力於現實世界中打造一個真實的環境、並省下物資成本,甚至於訓練過程中,亦無須受到現實世界中之實體物質在物理上的牽制,而可以加速於短時間內完成所有訓練過程中所需作出的動作[3-5]。因此,當智能體於現實世界中僅藉由攝像鏡頭看見一隻擺放為0度角的右腳鞋子,若它能在模擬環境中虛構出不同角度的右腳與左腳鞋子(甚至是另一個截然不同的物體),並將其提供給於模擬環境中所虛構出的機器手臂來進行抓取的訓練,智能體將不再受限於僅能用現實世界所提供之0度角的右腳鞋子來訓練權重。
也就是說,假設訓練的過程是在模擬環境當中執行,我們可於模擬環境中虛構出某個物品,並將其提供給於模擬環境中所虛構出的機器手臂來進行抓取的訓練,不僅於現實世界中省下了採買物品的費用(雖然若要在現實世界中進行推論的測試,還是得採買該物品),也省下機器手臂於現實世界中緩慢抓取的過程,在模擬中則可藉由強大的電腦運算能力,將整個訓練過程如同快轉式地撥放、高速將其完成。非營利的人工智慧研究組織OpenAI在使用強化學習來研究機器手掌操控立方體的技術時,便動用了8顆Nvidia的V100 GPU、以及 6,144個CPU核心,將累積於現實世界中100年的經驗壓縮於模擬中進行訓練,因此僅須耗費50小時即可完成[3]。
另一個類似的例子,則是柏克萊加州大學的研究人員所提出:藉由圖像化之目標來達到視覺強化學習的方法。比如希望能讓智能體將機器手臂擺到達指定位置狀態,只需給予智能體一張呈現機器手臂應如何擺放的目標狀態圖像,智能體就可以操控機器手臂使之同於所輸入的圖像來獲取最大的獎勵。並且在訓練的過程中,智能體可通過許多自我生成的目標(self-generated goal)來學習如何將機器手臂擺到指定的目標位置,而無須藉由人為方式刻意提供不同的目標狀態圖像給智能體來進行訓練。這可使得研究人員在開始訓練智能體前,無須耗費心力產生大量目標狀態圖像來提供給智能體[4]。
智能體身處在虛構的模擬環境中猶如虛擬實境的體驗

圖3 一隻沉浸在VR虛擬實境中的乳牛
在地狹人稠、寸土寸金的城市裡,求尺寸曠土不可得。畜牧業者難以於鋼筋水泥澆築的建築物當中,為所飼養的牛隻找到一個廣大的草原牧場,使其盡情享受印入眼簾的美景。然而,牧場主人若能想個辦法,使飼養的乳牛盡情享受著大自然的風光美景。乳牛便能藉著愉悅的心情多多生產高優質的純淨鮮乳,但要在人口密集的大都市裡找到一片青翠的綠草地又是談何容易!倘若要將牧場搬遷到荒郊野外,則土地還得重新購買,整個牧場亦須重新搭設,不僅費時又費力,且所生產的牛乳往後還得多負擔一筆長途運送回市區的開銷。若藉由頭戴式顯示器讓乳牛進入虛擬實境(Virtual Reality, VR)[6],就能使得乳牛雖身在大都會、卻心在大自然(如圖3)。而讓智能體於模擬環境中經歷現實世界裡無限可能遭遇的情況,便如同一隻藉由頭戴式顯示器進入虛擬實境裡享受著自然美景的乳牛。
同樣類似的例子,多得不勝枚舉,例如士兵藉由虛擬實境使其猶如獲得親臨戰場的體驗[7],以及在家就能到處趴趴走的虛擬實境跑步機或腳踏車[8]等,都是很好的例子。這些就像是智能體嘗試著在模擬世界中,虛構出一個如同現實世界中的場景,使得訓練的過程在虛構出來的環境當中執行。雖然置身在現實世界中,然而所虛構出的模擬環境卻取代了現實世界中的無限可能!
結論
強化學習在訓練的過程中,智能體將不斷地藉由嘗試錯誤法,來找出一個對於所身處的環境狀態,能得到最大獎勵的行動策略,並藉此訓練出權重。之後於推論的過程裡,當智能體一旦遇到類似於訓練過程中所曾遭遇過的環境狀態,隨即能藉由所訓練出的權重來判斷出應做出何種行動方能從中獲得最多的獎勵,如此便無需再像是訓練過程中,得不斷地利用嘗試錯誤來找出最佳解法。而智能體藉由所訓練出的權重,來判斷於所身處的狀態中,應採取何種行動方能獲得最大獎賞的情況,便類似人類藉由學習過程中所獲得的經驗,來判斷應當於所身處的環境中做出何種行動,方能滿足最大利益是同樣的道理。
我們若期望智能體在推論時,無論遇見各種情況都能執行最佳策略來獲得最大獎勵。於訓練時,便應提供各式各樣、盡可能多的環境狀態給予智能體進行訓練。然而藉由人為的方式來建立供應給智能體訓練的數據集是一件相當辛苦的事情,並且智能體若需在現實世界中藉由真實的硬體設備來進行訓練,整個過程將極其費時。倘若智能體於訓練過程中所需的數據集可以藉由電腦程序自動產生,並且藉由硬體設備來進行訓練的過程能轉由模擬環境來執行,整個訓練過程將使效率大幅提升!
參考文獻:
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg ,and D. Hassabis, “Human-level control through deep reinforcement learning, ” nature, vol. 518, pp.529–533, Feb 2015.
[2] A. Ramezani Dooraki and D. J. Lee, “An end-to-end deep reinforcement learning-based intelligent agent capable of autonomous exploration in unknown environments, ” sensors, vol. 18, 3575, Oct 2018.
[3] M. Andrychowicz, B. Baker, M. Chociej, R. Józefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, and L. Weng, W. Zaremba, “Learning dexterous in-hand manipulation, ” arXiv, Jan 2019.
[4] A. Nair, V. Pong, M. Dalal, S. Bahl, S. Lin, and S. Levine, “Visual reinforcement learning with imagined goals, ” arXiv, Dec 2018.
[5] D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke, and S. Levine, “QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation, ” arXiv, Nov 2018.
[6] J. Vincent. (2019) virtual reality homepage on The Verge [online]. Available: https://www.theverge.com/tldr/2019/11/26/20983717/vr-virtual-reality-headsets-cows-russia-vr-trial
[7] T. Alexander, M. Westhoven, and J. Conradi, “Virtual environments for competency-oriented education and training, ” in Adv. Hum. Factors Bus. Manag. Training Educ. Adv. Intell. Syst. Comput., vol. 498, 2017, pp. 23-29.
[8] J. Maculewicz, S. Serafin, and L. B. Kofoed, “A stationary bike in virtual reality - rhythmic exercise and Rehabilitation, ” in DCBIOSTEC, 2015, pp. 3-8.