前言
近年來,隨著人工智慧(Artificial Intelligence, AI)相關應用蓬勃發展,人工智慧演算法的複雜度與運算時間持續上升,同時也提升了人工智慧加速器(AI Accelerator)的使用需求。為了滿足持續增長中的運算需求,各廠商紛紛將多核心矩陣技術(Multi-core Array Technology)應用於人工智慧加速器,並以增加核心數目的方式來達到更高的運算速度。為了充分發揮多核心矩陣的運算效能,人工智慧加速器架構持續演進,由提高多核心矩陣的平行運算能力[1] [2] [3],進而為了適應新的演算法演進出可變式架構[4] [5] [6],其可根據演算法各層(Layer)之形狀(Shape)和大小(Size)自動變更加速器內部網路的連接,以適應不同頻寬與資料再利用之需求。從上述的架構發展可以發現,目前人工智慧加速器設計主要聚焦在如何提高運算速度及適應新的演算法,然而從系統應用的角度來看,除了加速器本身的運算速度外,資料傳輸速度亦是一個影響整體效能的關鍵因素。因此,我們將視角由人工智慧加速器進一步延伸到系統層級,分析運算與資料傳輸中各階段對整體系統效能的影響。
精彩內容
1. ESL層級之單通道人工智慧加速器效能分析
2. 高可擴充性之多通道人工智慧加速器架構
3. 高可擴充性之多通道人工智慧加速器效能提升分析 |
現有人工智慧加速器模擬分析
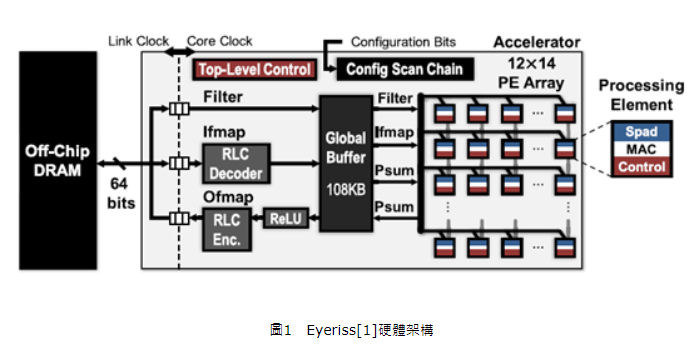
目前人工智慧加速器的架構一般由一個直接記憶體存取(Direct Memory Access, DMA)、總體緩衝器(Global Buffer, GLB)與多核心矩陣(Processing Element Array, PE Array),詳細如圖1所示。DMA負責透過匯流排(Bus)將資料由外部的動態隨機存取記憶體(Dynamic Random Access Memory,DRAM)搬入總體緩衝器,待運算結束後將結果由總體緩衝器移出至DRAM。總體緩衝器由靜態隨機存取記憶體(Static Random Access Memory, SRAM)構成,用於儲存輸入資料與加速器的運算結果,其根據深度學習(Deep Learning)卷積運算(Convolutional Computation)之需求分為Ifmap、Filter和Psumje共3種記憶庫(Memory Bank),各種記憶庫仍可根據需求分成更小的記憶庫。
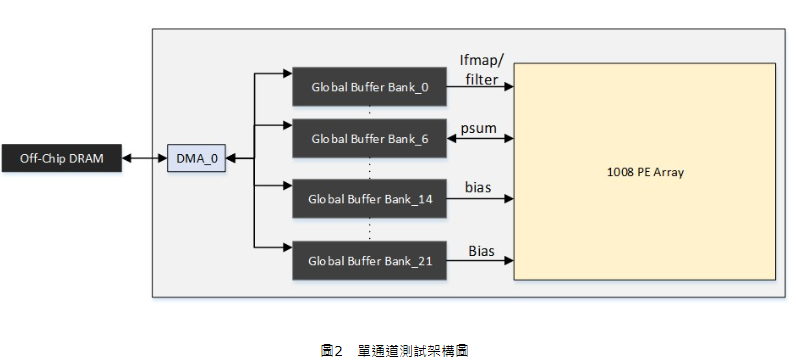
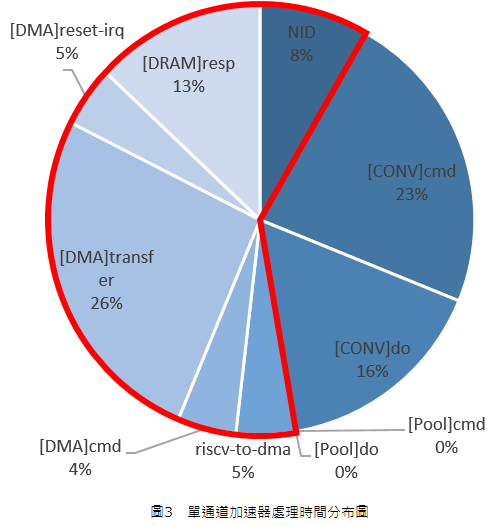
為了分析該架構的運算效能,我們採用系統整合設計軟體環境搭建一測試架構如圖 2,其具有一個DMA、22個總體緩衝器Bank及1008顆處理元件(Processing Element, PE)之多核心矩陣,並在250MHz的時脈下模擬Resnet-34運算,模擬結果顯示Resnet-34之運算速度為9FPs,其各部分之詳細處理時間分布如圖3所示。為了方便理解,我們將處理時間分成幾個大類:Conv(Convolution,卷積)、Pool(池化)、DRAM(DRAM反應時間)、DMA(資料傳輸)、NID(Network ID,網路標籤),其中Conv與Pool屬於多核心矩陣相關運算,DMA為資料傳輸,NID包含多核心矩陣所需ID資料傳輸與設定。由圖3可以看出,卷積(Convolutional)與池化(Pooling)相關運算占整體處理時間的39%,而DRAM與總體緩衝器之間的資料傳輸相關運算卻占據61%的處理時間(圖3中紅色線框起之區域),由此可見整體端對端(End-to-end)處理速度是由資料傳輸主導而非運算速度主導。
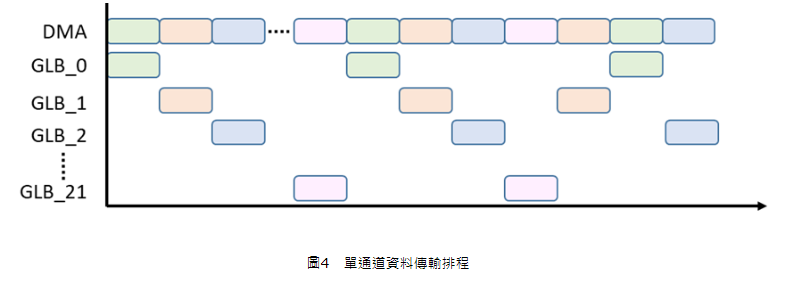
在圖1的架構中,DMA負責DRAM與總體緩衝器之間的資料傳輸,但是其每次只能連接DRAM與一個總體緩衝器記憶庫,這種傳輸方式相當於資料只能在單一通道(Single Cannel)中進行傳輸。因此,當總體緩衝器具有多個記憶庫時,每一個新的資料傳輸都必須等前一個總體緩衝器記憶庫所需資料結束傳輸後才能啟動,詳細資料傳輸排程如圖4所示,這表示各總體緩衝器記憶庫必須以序列(Serial)方式傳輸資料,導致整體資料傳輸時間上升。
多通道人工智慧加速器架構
由前述的分析可以發現,資料傳輸速度主要是受限於DRAM與總體緩衝器之間的單通道序列式傳輸,因此增加通道的數目即可達到平行傳輸,讓多個DRAM同時存取多個總體緩衝器記憶庫,進而降低資料傳輸的時間。根據這個想法,我們提出多通道人工智慧加速器(Multi-channel AI Accelerator),其架構如圖5所示,總共有N個DMA、N個DRAM和M個總體緩衝器記憶庫。每一個DMA透過匯流排連接到固定的DRAM以形成一個傳輸通道;每一個DMA都可以對所有總體緩衝器記憶庫進行存取。因此,整個架構形成一個N對M的資料傳輸網路,並由總體緩衝器控制器(GLB Controller,GLB_Ctrl)管理通道與總體緩衝器記憶庫的連接方式。在最佳的情況下,資料傳輸時所有通道都會被啟用,同時有N個總體緩衝器記憶庫進行資料搬移。而針對不同運算需求,此多通道人工智慧加速器架構可以增加或減少通道的數目,即可達到整體最佳運算時間。
在單通道加速器道設計中,資料皆儲存於同一DRAM,因此只需管理DRAM內部的資料配置。然而,在人工智慧加速器架構下,資料會事先經過分配後儲存在各個DRAM中,若未妥善安排資料,會發生多個DRAM資料同時要讀寫同一總體緩衝器記憶庫,或多個總體緩衝器記憶庫同時存取同一DRAM。在這種多對一的情況下,會以優先權較前面的DMA先進行傳輸,其他的DMA則必須等待目前的傳輸結束後才能進行,這種傳輸方式相當於退化成單一通道傳輸,無法發揮多通道平行傳輸的優勢。因此,在進行資料分配時,必須考慮核心矩陣所需資料的順序、通道數目與總體緩衝器記憶庫數量,將需要同時輸入的資料配置在不同的DRAM。圖6和圖7分別是多通道DMA與總體緩衝器記憶庫傳輸排程,其模擬為8個通道對6個總體緩衝器記憶庫進行存取,其中同一顏色代表同一通道存取的資料。從圖7可以看出,在有足夠通道數且資料配置妥當的情況下,所有的總體緩衝器記憶庫可以都同時進行資料存取,而無需等待某個通道有空後才能進行。
模擬結果
為了比較單通道與多通道人工智慧加速器的處理速度差異,我們同樣使用系統整合設計軟體環境建立圖5的多通道架構,並將其中的N設為8、M設為22,再接上前述的1,008個PE的多核心矩陣,同樣在250MHz的時脈下模擬Resnet-34運算。模擬與比較結果詳細如表1所述,整體(End-to-end)處理速度由9FPs加速至13FPs,相較單通道架構,多通道架構可減少30.8%整體處理時間。其中,資料傳輸相關處理時間由68ms下降至35ms,其占整體運算時間的比例(圖8中綠色線範圍內)由61%下降至45%,而卷積與池化運算所占的比例由39%上升到55%,由此可證明多通道人工智慧加速器架構可有效解決單通道架構資料傳輸過長導致的整體(End-to-end)處理速度瓶頸。
表1 多通道與單通道加速器之運算分析
|
Architecture
|
Single-channel
|
Multi-channel
|
|
FPS
|
9
|
13
|
|
Processing Time ms/Frame
|
110
|
80
|
|
Processing Time Distribution
|
Time (ms)
|
Percestage
|
Time (ms)
|
Percestage
|
|
CONV
|
cmd
|
26
|
23.00%
|
25
|
32.00%
|
|
do
|
18
|
16.00%
|
18
|
23.00%
|
|
DMA-DRAM
|
riscv-to-dma
|
6
|
5.00%
|
5
|
6.00%
|
|
Cmd
|
4
|
4.00%
|
5
|
6.00%
|
|
Transfer
|
29
|
26.00%
|
12
|
15.00%
|
|
restq_irq
|
20
|
18.00%
|
5
|
7.00%
|
|
NID
|
9
|
8.00%
|
8
|
11.00%
|
|
Pool
|
cmd
|
0
|
0.00%
|
0
|
0.00%
|
|
do
|
0
|
0.00%
|
0
|
0.00%
|
結論
模擬結果顯示,現有人工智慧加速器受限於單通道資料傳輸,資料傳輸占據大部分整體處理時間,導致整體端對端處運算速度下降。為了解決通道不足的問題,我們提出多通道人工智慧加速器,其中每一通道由一組DRAM與DMA組成,每個DMA都可存取所有總體緩衝器記憶庫,並形成一個多對多的資料傳輸網路。相較於單通道加速器,一次只有一個總體緩衝器記憶庫運作,其他總體緩衝器記憶庫則處於待機狀態;多通道加速器可同時對多總體緩衝器記憶庫進行資料存取,降低總體緩衝器記憶庫處於待機狀態的時間,提高整體資料傳輸速度。模擬結果顯示,相較於單通道架構,8通道架構之人工智慧加速器的資料傳輸時間由68ms下降至35ms,整體運算時間減少30.8%,整體運算速度由9FPs推升至13FPS。由以上結果可知,多通道人工智慧加速器架構可有效解決單通道架構下資料傳輸過長導致的整體處理速度瓶頸,提升整體加速器之運算效率,並可以居不同需求變更通道數目,以達到最佳運算速度。
參考文獻
[1]Y.H. Chen, T. Krishna, J. S. Emer and V. Sze, "Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks", IEEE J. Solid-State Circuits, vol. 52, no. 1, pp. 127-138, Jan. 2017.
[2]B. Moons, R. Uytterhoeven, W. Dehaene, and M. Verhelst, “14.5 envision: A 0.26-to-10 TOPS/W subword-parallel dynamic-voltageaccuracy-frequency-scalable convolutional neural network processor in 28 nm FDSOI,” in ISSCC Dig. Tech. Papers, San Francisco, CA, USA, Feb. 2017, pp. 246–247.
[3]S. Yin et al., “A 1.06-to-5.09 TOPS/W reconfigurable hybrid-neuralnetwork processor for deep learning applications,” in Proc. Symp. VLSI Circuits, Jun. 2017, pp. C26–C27.
[4]Y.-H. Chen, T.-J. Yang, J. Emer, and V. Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,” IEEE J. Emerging Sel. Topics Circuits Syst., vol. 9, no. 2, pp. 292–308,
[5]Sungpill Choi, Kyeongryeol Bong, Donghyeon Han, Hoi-Jun Yoo, "CNNP-v2: A Memory-Centric Architecture for Low-Power CNN Processor on Domain-Specific Mobile Devices", Emerging and Selected Topics in Circuits and Systems IEEE Journal on, vol. 9, no. 4, pp. 598-611, 2019.
[6]Kuo-Wei Chang, Tian-Sheuan Chang, "VWA: Hardware Efficient Vectorwise Accelerator for Convolutional Neural Network", Circuits and Systems I: Regular Papers IEEE Transactions on, vol. 67, no. 1, pp. 145-154, 2020.
[7]Jun. 2019C. Zhang, Z. Fang, P. Zhou, P. Pan, and J. Cong, “Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks,” in Proc. ICCAD, 2016, pp. 1–8.