工業技術研究院 資訊與通訊研究所 黃俊傑 李建宏 黃士銘 吳藺剛 賴國弘

隨著邊緣運算的快速發展,企業需求越來越多地依賴於邊緣端和公有雲的算力資源,如何通過混合雲邊算力資源調度達到成本效益最大化,將是未來的挑戰。
前言
雲端和邊緣雲都為用戶提供算力、網路和存儲服務。過去十年,邊緣運算發展迅速,尤其在近五年部署應用顯著增加。如何同時善用雲端和邊緣端的算力資源,使企業既能在邊緣端實現關鍵或敏感服務,又能利用公有雲的算力資源完成工作,並通過混合雲邊算力資源調度達到成本效益最大化,這將是未來的挑戰。
本文將探討混合雲邊算力資源調度管理機制,通過整合邊緣端和公有雲的算力資源,企業可以將重要和敏感的資料留在邊緣端進行訓練或推論,而將非敏感資料交由公有雲的大量算力資源來完成。
精彩內容
1. 混合雲邊算力資源調度管理平台之必要性
2. 混合雲邊算力資源調度管理平台架構
3. 混合雲邊算力資源調度於AI/GenAI應用情境之優點 |
混合雲邊算力資源調度管理平台介紹
隨著物聯網的普及,邊緣運算對產業的影響將增大,各個產業皆需要它的存在。根據國際調研機構IDC調查[1],2024年全球邊緣運算投資金額將提升至2,320億美元,相對於2023年增加15.4%,並在2027年達到3,500億美元。雲運算和邊緣運算的區別在於處理資料量的多少、延遲性以及分析的深度和範圍。以下就雲運算 (Cloud Computing)、邊緣運算(Edge Computing)及邊緣人工智慧(Edge AI)做說明:
(1) Cloud Computing:雲運算為一種運算架構,藉由整合運算、儲存與網路的資源池,提供用戶端隨需選用,雲運算提供可快速擴展且具彈性的運算環境。
(2) Edge Computing:採用邊緣運算的目的是盡可能靠近資料來源以減少延遲和網路頻寬的使用,讓企業能夠更有效地收集和分析資料。對企業而言,邊緣運算能夠優化工作流程,達到節省成本、提高獲利,優化產品交付速度等優勢。採用邊緣運算優點包括:(a)減少延遲,快速回應;(b)提高資料的安全性;(c)本地端的資料收集更為容易,此適用情境在網際網路無法到達的場域等。
(3) Edge AI:透過邊緣運算的算力完成AI的工作任務執行;換句話說,由於要被AI使用的資料是在邊緣端產製或收集,故透過邊緣端的算力提供AI即時地完成工作任務,而不須將這些資料送到公有雲進行運算。因此,Edge AI使得邊緣端的裝置更具智慧,使其在本地端即可作為對應的決策。Edge AI所帶來的優點包括:(a)快速回應;(b)資料安全;(c)穩定性與可靠性。
Gartner在2023年8月的報告[2]中指出,Edge AI是資料科學和深度學習的主要趨勢之一。Gartner預測到2025年將超過55%的深度神經網路(Deep Neural Networks)之資料分析將發生在邊緣端,而這個數據相對於2021年只有不到10%的資料分析在邊緣端發生增加很多。整體而言,Edge AI帶來的特色將使得設備更智能且提供更廣泛的應用;Edge AI的應用情境之領域非常寬廣,包括:(a)智慧工廠;(b)智慧零售;(c)智慧城市;(d)智慧醫療;(e)能源與公共事業等。
對企業而言,邊緣運算提供安全性與即時性等優點,加速邊緣運算的部署速率。但因為場域環境與投入經費的限制,無法像資料中心一樣能提供大量硬體所需的電力系統,並且其投入的經費也會相對少非常多,導致邊緣端的邊緣雲管理平台運算資源不足,無法同時滿足大量的運算需求。故邊緣端如何讓重要且須被立即執行的高優先權工作能立即取得運算資源便是一件很重要的議題。另一個議題即是善用公有雲的算力資源,讓非機敏或非須立即被處理的資料由公有雲協助處理。採用混合雲邊算力資源整合應用的機制,在邊緣端投入滿足應用服務需求的算力成本,可同時滿足具重要、機敏且即時性的資料在企業的邊緣端立即完成運算的工作;並將其餘的工作交由單一公有雲或多雲的架構來完成其他的工作。
此平台的主要目的是根據工作負載的特性,將其分配到邊緣端和企業在公有雲或多雲環境中,使工作負載利用多重算力資源完成任務。「混合雲邊算力資源調度管理平台」之管理核心為全域式智能資源編排管理引擎,如下圖 1所示。資源編排管理引擎提供雲端資源配置與管理機制,依據用戶端工作負載的要求,藉由排程演算法配置最符合此工作負載相對應的運算資源,進行工作負載與運算資源之管理,例如:動態新增運算資源給此工作負載或是當工作負載完成工作任務後回收這些運算資源等。此全局資源編排管理引擎可同時向邊緣端資源編排管理引擎請求資源,並管理公有雲的算力資源。全域智能資源編排管理引擎具備綜觀全局的能力,可設定不同的管理政策來決定用戶的工作負載分布,構建最適合用戶的算力環境。這包括在多雲環境中選擇符合政策的公有雲,以滿足安全、效率和成本的需求。為了進一步提升管理效率,全域智能資源編排管理引擎全自動化管理虛擬資源的全生命週期,動態向本地邊緣雲請求調整運算資源,並向公有雲請求或減少資源,協助分配工作任務至對應的公有雲。
>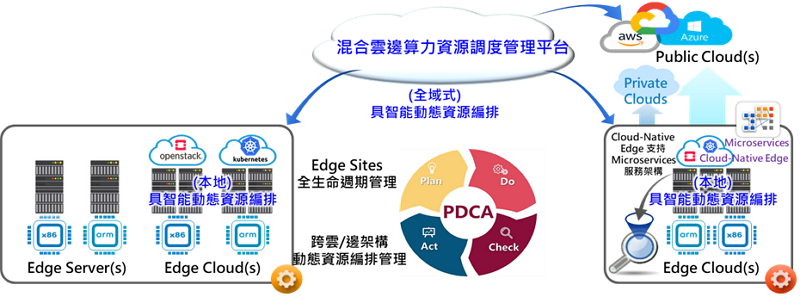
圖 1 混合雲邊算力資源調度管理平台
混合雲邊算力資源調度管理平台架構
前一章節介紹了『混合雲邊算力資源調度管理平台』的功能和目的,本章節將介紹其架構。該資源管理機制分為兩個階段進行運算資源配置。第一階段由全域智能資源編排管理引擎根據規劃政策進行資源請求,將工作負載依據執行政策分配至對應的邊緣雲或公有雲。第二階段由本地資源調度管理平台根據本地政策引擎進行虛擬資源配置,實際載入工作負載(如虛擬機或容器)。本地資源編排管理服務通過監控機制管理虛擬資源的生命週期,並將監控結果回報給全域智能資源編排管理引擎。全域式具智能資源編排管理引擎在此虛擬資源運行期間,可根據用戶的請求動態調整算力資源的配置,例如:向該虛擬資源的管理平台請求更多的算力資源加入至虛擬資源,或是將工作負載部分執行工作交由另外的管理平台執行,以協助提昇可負擔的工作量。
第一階段的資源編排管理機制為全域式的架構,主要任務是找尋最符合用戶端需求的政策,以進行混合雲邊管理平台的配置;最常見的政策引擎例如:(1)選擇離用戶端最近的混合雲邊管理平台,此機制最大的優點是減少延遲與提高回應時間,但缺點是有可能會有過度集中使用某幾個特定的邊緣雲/公有雲導致資源浪費;(2)選擇效能最佳的混合雲邊管理平台,例如:有很多高速的CPU、GPU、大量的Memory或是高效的儲存設備等,此機制最大的優點是讓應用服務獲得最佳的運行效能,但其缺點是突然有大量的工作負載發生時,會大大增加工作的負擔;(3)選擇成本最低的混合雲邊管理平台,此機制最大的優點是降低使用者負擔成本,較適合需要資源密集型的工作負載,但其缺點是在考慮成本因素下無法兼顧效能或管理平台的可用性;(4)選擇混合雲邊管理平台的可用運算資源池最多的管理平台,此種機制對維運團隊是最佳的組合,讓運算資源以均勻分配(uniform distribution)的方式被管理,但其缺點是對用戶而言不一定能獲得最佳效能的運算資源;(5)採用前四種混合機制的排程演算法,並依據的需求給予不同的權重,此種演算法的優點是多面向考慮所有因素後,再將用戶的工作負載部署至最恰當的邊緣雲/公有雲管理平台,此種機制的優點是綜合考量,但缺點是演算法會相對複雜,尤其是權重要如何決定的部份將會更為複雜;(6)以(5)為基礎加入AI元素,同時考量邊緣雲/公有雲管理平台的工作負載狀態,對維運團隊而言,可以獲得最佳的資源管理,對用戶而言,可以獲得較佳資源配置,但缺點是同(5)且須收集大量的數據資料作為模型訓練的基礎,增加管理上的複雜度。
第二階段的排程機制會以原生的邊緣雲或公有雲既有的排程演算法為主,例如:OpenStack採用filter and weight演算法,而filter的演算法也是類似上述的組合機制作為filter的條件。Kubernetes會有不同組合的排程演算法,例如:若是以Intel第四代CPU為主的Xeon伺服器,整合Intel CRI-RM(Container Runtime Interface – Resource Manager)達到硬體資源感知的目的,並彈性搭配Kubernetes的政策參數,例如:整合NUMA (Non-Uniform Memory Access),讓用戶端的工作負載獲得最佳的執行效率。此外,大多數邊緣雲/公有雲管理平台允許用戶設定自動擴展策略,因此,資源編排管理機制在第一階段和第二階段都需要考慮用戶已部署的工作負載位置,作為擴展新虛擬資源的策略之一。
由於邊緣雲管理平台會由維運團隊進行部署與管理,故除了上述的排程演算法讓用戶端的工作負載獲得對應的運算資源外,可以加入優先權的政策機制,讓優先權高的用戶或是優先權高的工作負載在排程演算法中獲得較優先處理的權限,快速獲得邊緣雲/公有雲管理平台的運算資源。下圖 2為具優先權保證之邊緣雲管理平台,透過此管理平台會讓具高優先權的工作負載獲得較優先的資源配置,同時儲存低優先權應用服務狀態,並將低優先權應用服務從運行狀態移至等待排程狀態,讓高優先權的工作負載進入運行狀態。
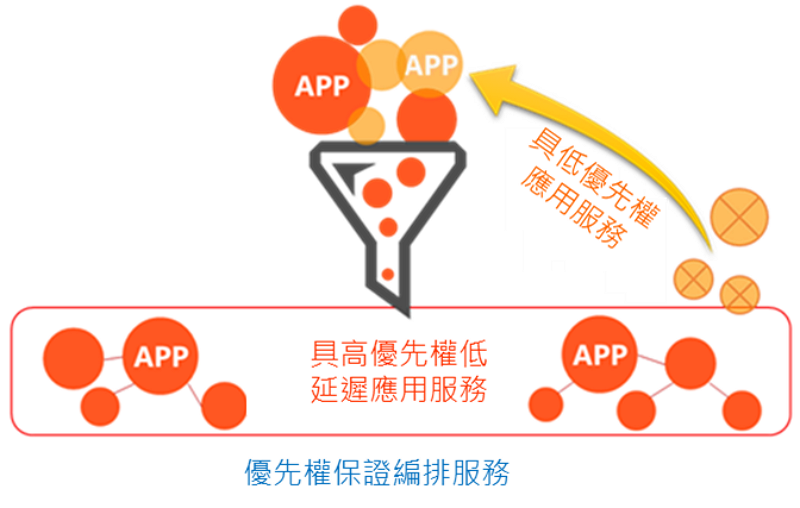
圖 2 具優先權保證之邊緣雲管理平台之關鍵服務
混合雲邊算力資源調度於AI/GenAI應用情境之優點
AI在製造業和醫療領域獲得高度評價,提升產能並輔助醫生判讀影像,效果顯著。Google Transformer除了語言模型運作外,最大的貢獻是『平行化』,能同時進行多個處理工作。最近熱門的生成式AI(Generative AI,GenAI)基於Transformer Model,結合語言模型或多模態模型。GenAI 創造新一代數位助理,優化知識管理、內容創建工具和應用程式,改變應用程式建構方式,對各產業影響積極。AI與GenAI包括模型訓練、部署和推論。訓練階段需要大量運算資源,尤其是GenAI。推論階段的運算需求則取決於用戶數量。大型語言模型訓練主要由雲端服務供應商(Cloud Service Provider,CSP)(如Amazon、Microsoft、Google)完成;推論則由邊緣端的AI伺服器、工作站或終端裝置進行。
企業在訓練模型時,會以通用模型為基礎,加入專屬資料,產出符合需求的模型。由於訓練過程涉及敏感資料,不宜交由公有雲完成。企業可採用本文所提的混合邊雲算力資源調度管理平台,將非敏感資料交由公有雲完成精進型語言模型,再將其置於邊緣端算力平台,加入敏感或重要資料,訓練出更適合企業需求的模型;或是整合企業在邊緣端的邊緣雲管理平台及公有或多雲管理平台,採federated learning方式完成企業專屬的語言模型。
結論
邊緣運算需求逐年增加,但邊緣運算環境無法像資料中心那樣建置大量運算資源,硬體資源較少,因此只需執行必要的運算工作。混合雲邊算力資源調度管理平台針對這一特性,根據工作負載的特性,將其部署到對應的邊緣雲、公有雲或多雲環境,尤其適用於GenAI工作負載。