
隨著資料傳輸規模大增,加上對於低延遲、資訊安全、私密資料保護等需求日益升高下,邊緣運算伺服器市場興起。
前言
近年隨著5G、AI及物聯網等趨勢發展下,智慧裝置數量不斷提升,導致資料傳輸規模大增,引起傳統雲端運算的頻寬負載,加上對於低延遲、資訊安全、私密資料保護等需求日益升高之下,邊緣運算伺服器市場興起。
伺服器硬體設備以中央處理器(Central Processing Unit,CPU)為運算核心,主要分為x86與非x86兩大陣營。x86架構目前市占率超過90%,主要廠商為Intel與AMD;非x86陣營包括Arm和RISC-V兩種架構,前者在行動裝置已是主流,後者則基於開源指令集架構在新興市場成長快速。除了中央處理器之外,根據特定應用需求,市場也發展出特殊設計的晶片來降低CPU的負載,以實現更佳的性能與成本效益,其中包括GPU、FPGA以及ASIC 三種類型晶片。GPU過去以加速繪圖運算為主,目前則於AI訓練扮演要角;FPGA和ASIC是因應客製化演算法而開發,在特定應用如AI推論可提供優於GPU之運算能效。
針對邊緣運算伺服器所需之高性能ASIC晶片開發,目前市場有ARM及RISC-V兩種選擇,由於RISC-V為開放架構,其低成本、高彈性、可客製化的特點吸引產業目光,在相關國際標準組織推動下,國際大廠Google、NVIDIA、Intel及新創業者Esperanto、Ventana等紛紛採用,成為產業重要趨勢。由供應鏈角度來思考,第一步是掌握RISC-V矽智財,此部分領導廠商為SiFive及國內業者晶心科技,再來則是由系統晶片業者如Esperanto與Ventana等訂定晶片規格,包括RISC-V核心數目、記憶體大小、匯流排寬度、週邊I/O支援度等系統架構設計並完成晶片實作,系統業者基於這些高性能晶片進行伺服器板卡開發,最後通過伺服器業者如Meta與Amazon等業者驗證,實現技術商品化。
精彩內容
1. 異質叢集運算架構
2. POC擬真環境與電路實作技術
3. 核心函式庫與工具鏈技術及應用成果展示 |
異質叢集運算架構
一般來說異質運算是指系統使用不同種類的計算單元,例如CPU、GPU等。不同運算工作交由符合需求的專用處理器來執行,可大幅提升運算效能、改善能源使用效率,計算單元之間透過高流量、低延遲的通道互相串聯,如同一個大型處理器。近年來,異質運算的定義變得更廣泛,包含使用不同架構的處理器,例如ARM、RISC-V架構處理器,其運算核心數量較多、功耗較低。使用不同處理器架構的伺服器解決方案,有可能更快解決特殊的工作負載。
基於上述理念,我們需要先定義出基本運算單元的長相,針對不同應用情境,可透過調配基本運算單元數目的方式增加或降低平行度以符合各別效能需求,無須費時重新設計其他硬體架構,透過延展性(Scalable)特徵使此硬體更廣泛被採用於對運算力有一定程度需求之應用。
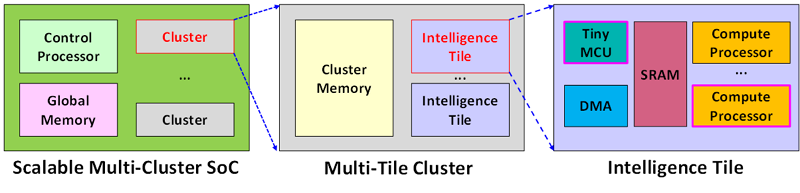
圖1 具延展性異質叢集運算架構(基於智慧型運算單元)
圖1最右邊為此架構的基本區塊─智慧型運算單元(Intelligence Tile),其中的組成元素包含計算處理器(Compute Processor),為整體架構中主要的算力來源,靠平行度組成高性能運算晶片的總運算力(Tera Operations per Second,TOPS);微控制器(Tiny MCU),專司單元內部的流程控制,可降低部分晶片主控制處理器之控制複雜度;此外還搭配了負責搬運資料的直接記憶體存取(Direct Memory Access,DMA)及運算資料暫存所需之SRAM。基於智慧型運算單元,可透過區塊堆砌成多單元叢集(Multi-Tile Cluster),再結合多個叢集並搭配晶片核心控制處理器(Control Processor)及主記憶體,形成完整的高性能運算晶片架構,如圖1最左邊所示。整體架構於不同層次皆採用堆砌概念,其延展性佳,可根據應用對於運算力的需求,調整硬體配置以避免資源浪費或能力不足等問題。
POC擬真環境與電路實作技術
為了證明前面所定義之異質叢集運算架構設計理念可行,如何利用最短時間拼湊出能進行概念驗證(Proof of Concept,POC)的擬真環境格外重要。最好能有概念類似可藉助其功效之平台尤佳,圖2中Xilinx所生產之ZCU106發展板剛好符合此處的需要。ZCU106內含一顆Zynq UltraScale+ MPSoC,型號為ZU7EV,該型號MPSoC除了FPGA本來就具備的可程式化邏輯空間(Programmable Logic,PL)外,還具備四核心的Arm Cortex-A53、二核心的Cortex-R5與Mali-400 MP2 GPU等邏輯所組成的運作系統(Processing System,PS) [1],如圖3所示。

圖2 Xilinx ZCU106發展板
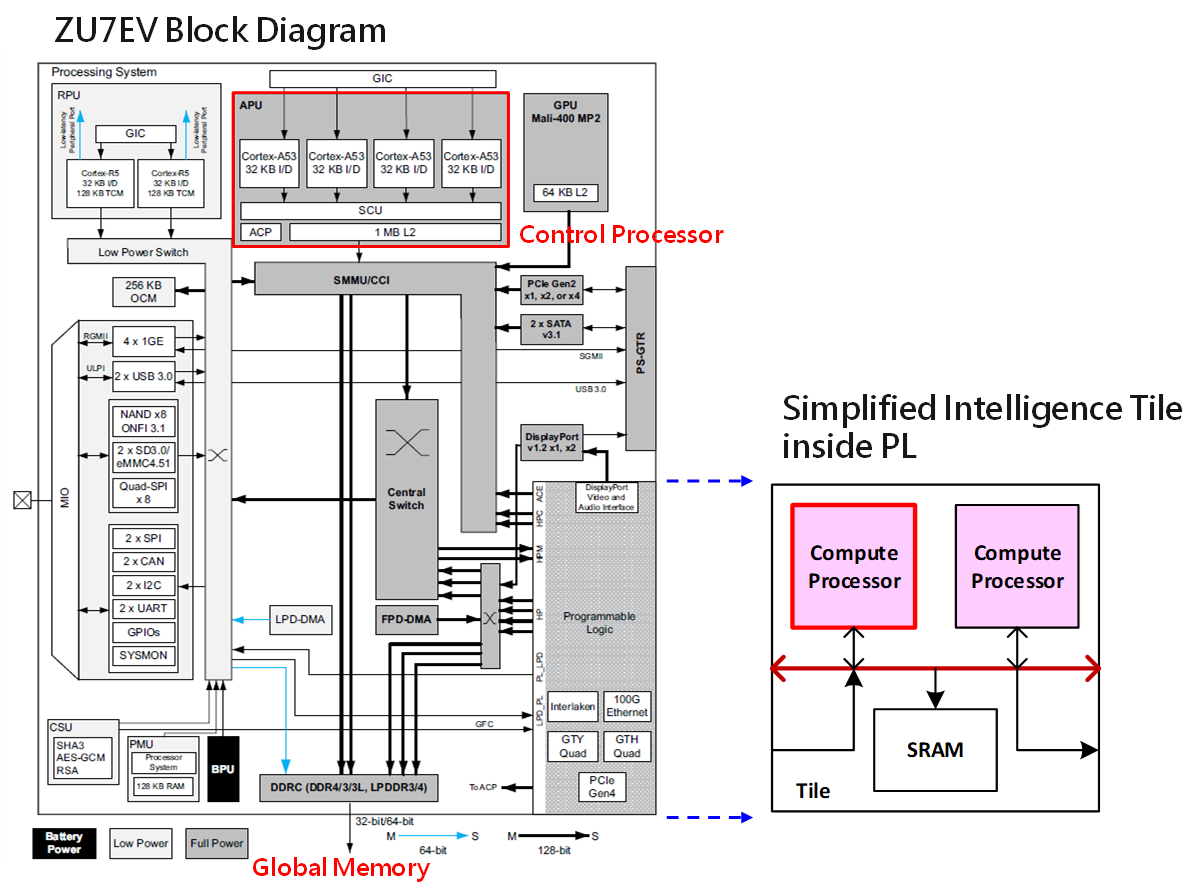
圖3 Xilinx UltraScale+ MPSoC-ZU7EV內部結構
ZU7EV所具備的四核心Arm Cortex-A53,與異質叢集運算架構中的控制處理器定位相同,主要負責流程控制、作業系統執行等。另外,運作系統中的DDR控制器則可扮演主記憶體的存取角色 [2]。藉由這些成熟的內建矽智財,可讓團隊先專心於智慧型運算單元的設計,降低系統中的不確定性(不用懷疑主處理器和記憶體存取的功能正確性)。為了在ZU7EV有限的可程式化邏輯空間中驗證異質叢集運算架構的概念,智慧型運算單元將被簡化為兩個計算處理器搭配一個共享記憶體。
表1 ZU7EV系統記憶體地圖分布
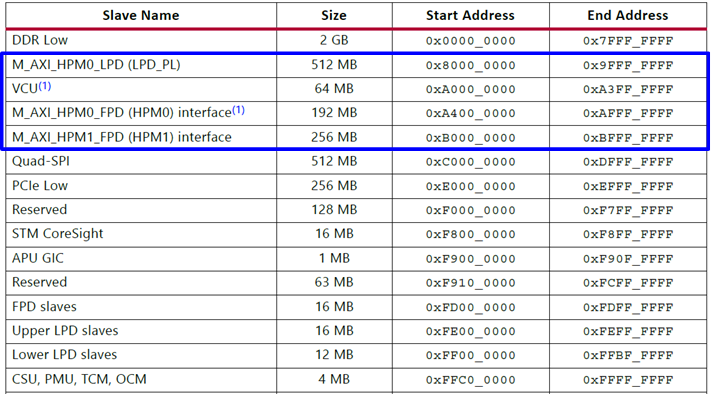
表1為ZU7EV所定義的記憶體地圖 [3],其中分配給可程式化邏輯空間的區域大小為1GB(由0x8000_0000至0xBFFF_FFFF),PS是透過圖3中的LPD_PL及HPM連接埠與PL進行溝通。由於智慧型運算單元中的記憶體分布不會剛好落在ZU7EV所定義的這個區域中,所以若要將此設計與ZU7EV中的PS進行連接,中間必定要有額外的地址轉換器(Address Translation Unit,ATU),負責將PS欲存取之位置轉換成單元內所定義的地址。另外,PS內的Arm Cortex-A53和PL中的計算處理器,彼此之間所實現的溝通方式為傳統的中斷。
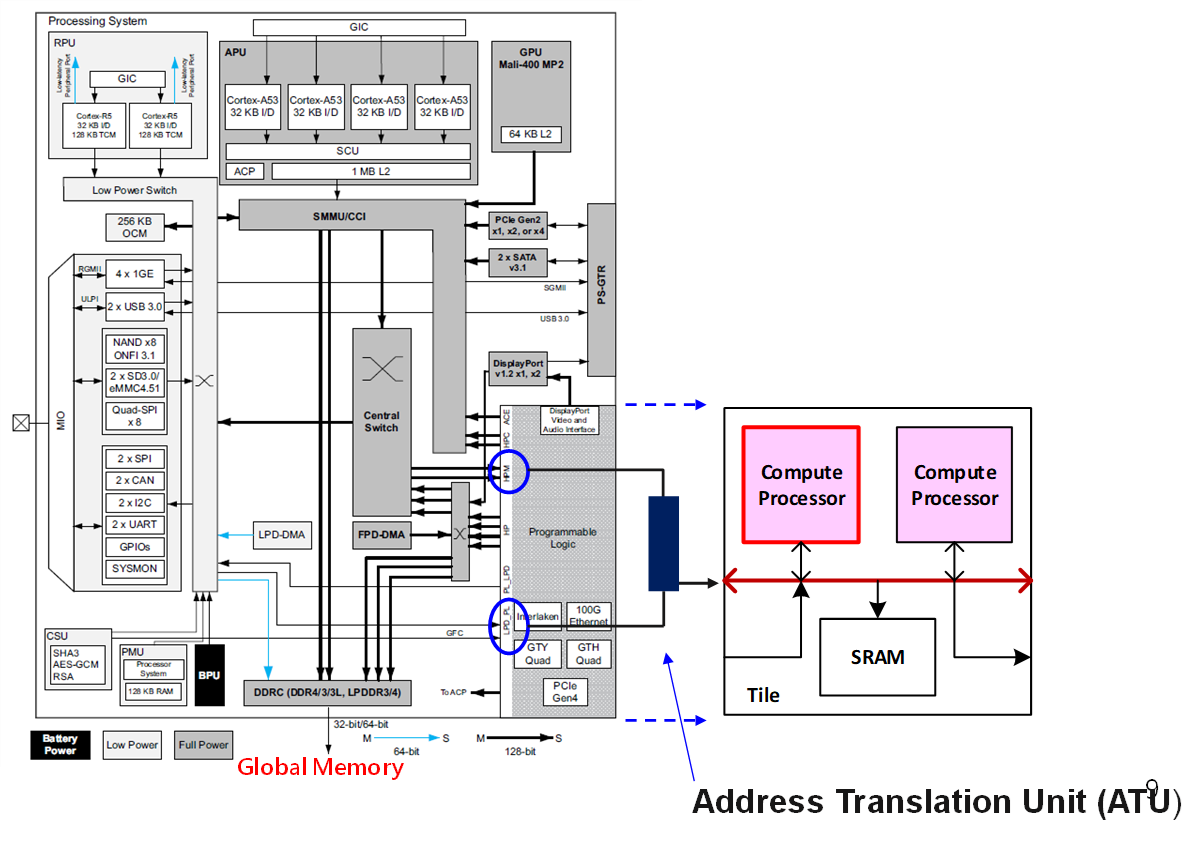
圖4 FPGA內部平台架構
關於運算單元架構中的共享記憶體,為確保由Cortex-A53和計算處理器所看到的資料一致性,需確認處理控制處理器所發出共享記憶體區段的存取必須為不可緩存的(non-cacheable),否則當控制處理器將某共享記憶體位置資料存入本身快取記憶體之後,又針對其進行修改但尚未寫回原先共享記憶體的實體位置,將導致計算處理器端出現資料不一致的情形。經多方資料查證與實驗,已確認ZCU106中的Arm Cortex-53,面對可程式化邏輯空間的記憶體存取皆屬於Strongly Ordered形式。Strongly Ordered屬性記憶體表示在存取時一定要確實碰到該實體記憶體位置,並不會被快取記憶體所擋住。故對Cortex-A53來說,所有在PL內的記憶體區段都屬於不可緩存的,故可程式化邏輯區塊內的計算處理器不會遇到資料不一致的問題。克服上述問題之後,便可透過此開發平台進行異質叢集運算架構的概念探索與相關軟體驗證。
智慧型運算單元的組成元素除了影響運算力的四個計算處理器與儲存運算中間值的SRAM之外,亦內建了DMA保持資料搬運的方便性,更加上微控制等級處理器協助單元內部的功能調整,提升整體運作效率,完整架構如圖5所示。
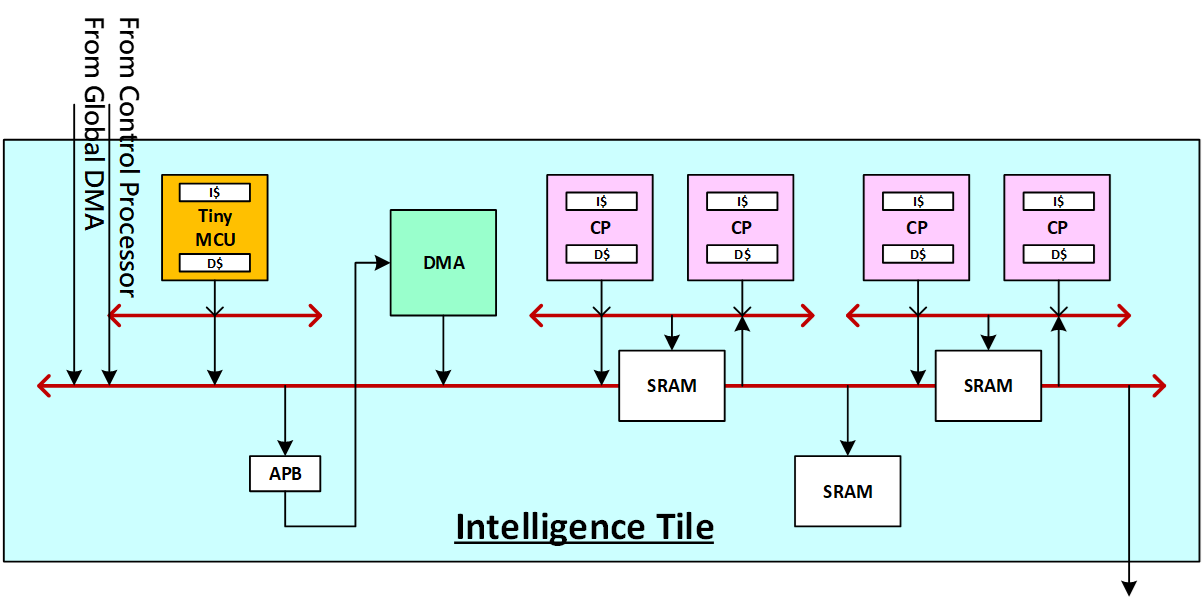
圖5 智慧型運算單元細部架構圖
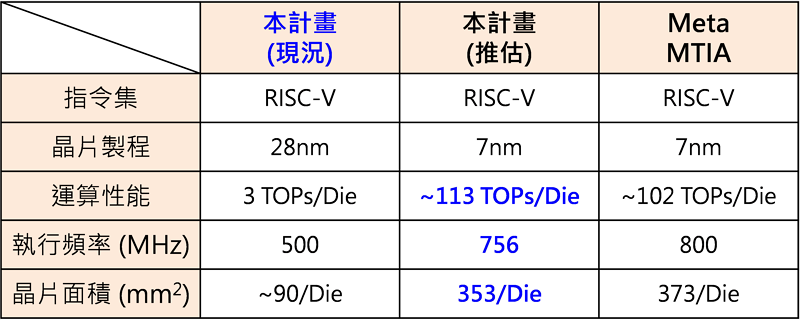
ASIC流程實作部分,由於計畫經費與製程檔案取得狀況等實質條件限制,最終是採用TSMC 28nm HPC+製程進行後段實作,完成智慧型運算單元布局繞線設計,面積為2500x2500µm2,最高執行頻率可達500MHz,並可透過延展式架構特性及後段設計之階層實作方法達成單晶片運算力3.072 TOPS之實體設計,最終完整的智慧型運算單元電路布局如圖6所示,可以注意到計算處理器擺放方式為兩個一組置於單元左右兩側,而微控制器則擺放於單元中央,單元下方則是SRAM與匯流排相關邏輯。SRAM與匯流排邏輯相近可縮短存取路徑,因多數外部存取路徑之目的地皆為單元內部之SRAM。Meta(前身為Facebook)於International Symposium on Computer Architecture 2023研討會(ISCA’23)中公布首顆公司自製之高性能運算晶片(Meta Training and Inference Accelerator,MTIA),其採用TSMC 7nm FinFET製程(N7)進行實作,最高執行頻率可達800MHz,單晶片面積為19.34x19.1mm(~373mm2),單晶片運算力在INT8的運算單位下約102.4 TOPS。表2第一列為目前採用28nm製程資料所實作出來的數據,透過TSMC所發表的相關文獻 [4][5],可得知28nm的實作數據對應到7nm製程時的可能數值(包含執行頻率、運算力以及對應單晶片面積),表示於第二欄,最終第三欄則呈現MTIA目前公布出來的對應數據。透過這比較表,可顯示目前的設計在晶片面積、執行頻率與運算力等技術指標與當前國際指標同步。
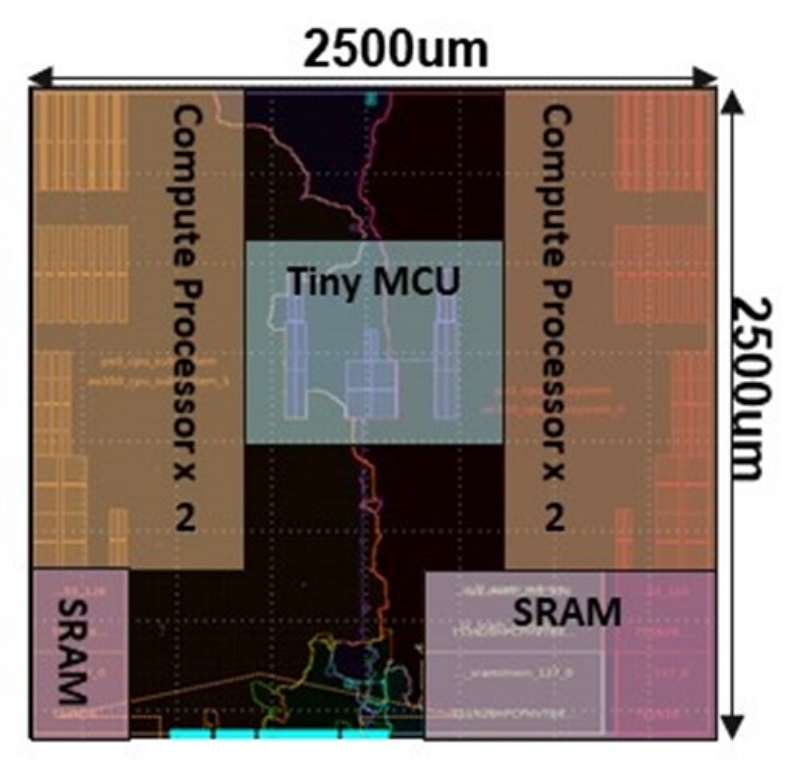
圖6 智慧型運算單元電路布局
表2 階段性成果與國際現況比較
核心函式庫與工具鏈技術及應用成果展示
高性能運算晶片需要搭配客製化核心軟體與工具鏈,方可發揮其硬體設計的最大效能。整個軟體工具鏈與執行環境是以支援多核平行與向量運算為考量進行設計,歸納幾點特色如下,完整流程則如圖7所示。
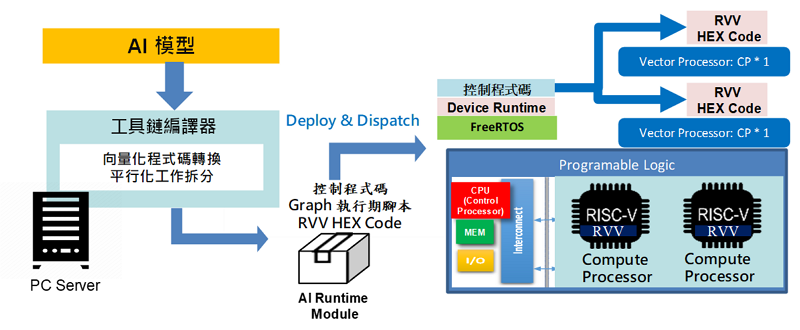
圖7 軟體工具鏈流程圖
(一) 透過軟體自動部屬架構,偵測此時硬體加速模組支援平行度,將工作量動態分配到運算單元上同時運行,獲得平行化與向量化處理得加速效果。
(二) 分配至各硬體加速模組後,透過運算圖分割技術,實現多核AI向量平行運算,以前面所提及FPGA發展板的雙核計算處理器為例,理論上可提升二倍性能,但考量可能的overhead產生,故預估性能可提升1.5~1.7倍。
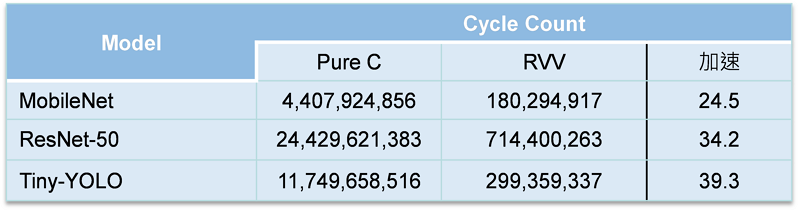
(三) 搭配使用以RISC-V計算處理器之向量擴充指令集(RISC-V Vector,RVV),提升單一處理程序之AI運算效率,性能提升24.5~39.3倍。表3內容即針對三個不同的AI模型在單純C語言與使用向量擴充指令集之間的週期數比較。
表3 向量擴充指令集加速之實驗結果
結合FPGA發展板中的異質叢集運算架構與其客製化核心軟體工具鏈,以圖8的深度學習計算節點叢集技術進行技術成果展示。此技術為一可延展設計,系統效能隨硬體模組同步擴增,將工作量動態分配並通過工具鏈編譯AI模型載入各運算單元硬體上同時執行。最終搭配多核平行化運算與向量擴充指令集加速,提升整體AI運算效率。
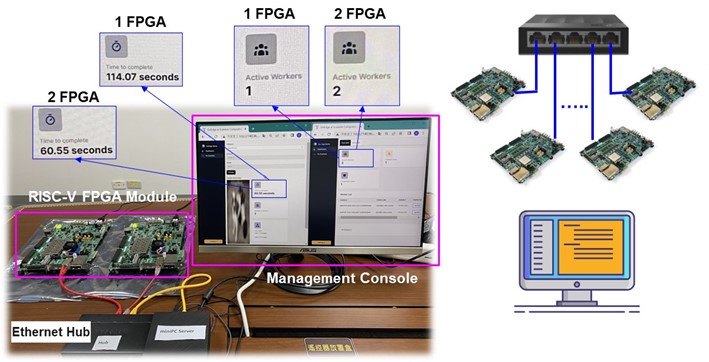
圖8 可延展之深度學習計算節點叢集技術
結論
新世代AI加速及邊緣雲產業將聚焦於高性能運算電路的開發,本文所提出之異質叢集運算單晶片架構具延展性,可依應用需要配置智慧型運算單元的支援平行度。並透過TSMC 28nm HPC+製程進行實作,將相關實作數據根據文獻所提供的製程轉換公式與業界最新之技術發表進行比較,無論在晶片面積、執行頻率或運算力等技術指標皆可與當前國際指標同步。最終透過深度學習計算節點叢集技術呈現出硬體與客製化軟體工具鏈環境的搭配,透過各種加速技巧,提升整體運算效率39.3倍。
參考文獻
[1] Zynq UltraScale+ MPSoC ZCU106 Evaluation Kit. Available at: https://www.xilinx.com/products/boards-and-kits/zcu106.html
[2] ZCU106 Evaluation Board User Guide (UG1244 v1.4), Xilinx, 2019.
[3] Zynq UltraScale+ Device Technical Reference Manual (UG1085 v2.2), Xilinx, 2020.
[4] S. -Y. Wu et al., “A 16nm FinFET CMOS technology for mobile SoC and computing applications,” 2013 IEEE International Electron Devices Meeting, Washington, DC, USA, 2013, pp. 9.1.1-9.1.4.
[5] S. -Y. Wu et al., “A 7nm CMOS platform technology featuring 4th generation FinFET transistors with a 0.027um2 high density 6-T SRAM cell for mobile SoC applications,” 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2016, pp. 2.6.1-2.6.4.