集仕多公司 梁哲瑋 劉子菱 寒江河智也

生成式影音平台 AI Generated Video Platform(AIGV)以生成式人工智慧技術,產生照片與影片降低影片製作成本。
前言
本文介紹生成式影音平台 AI Generated Video Platform(AIGV)的海外應用案例,以生成式人工智慧技術,產生照片與影片降低影片製作成本。在 AIGV 影片製作過程中需要模型微調,以符合國內在地風情或是符合海外當地文化,文中以客家柿餅為例,進一步介紹模型微調技術,讓原本不認識新竹客家柿餅的原始 Stable Diffusion 模型,產出新竹客家柿餅的照片並應用於影片中;此方法可應用於海外當地文化風情的AI建模,包含臉型、服裝、妝容、物品、景色等等。最後介紹日本企業使用集仕多 AIGV 平台在新人招募影片製作的應用案例,讓原有需要人工多次出錯與重錄的時間,節省高達82%時間。
生成式影音平台 AIGV 簡介
AIGV 是 AI Generated Video 的簡稱,是透過人工智慧(AI)技術製作的影片,使用深度學習和 TTS 等技術,生成影片。AI生成的影片可以涵蓋多個領域,AI可以生成新的影像,包括人造場景、人物、物體或景觀,也可以將現有影像進行合成和剪輯,創建新的影片。這些影片可能基於文字或語音內容生成影片,例如根據故事、文章或語音指示創建視覺內容。AI可以創建人物動畫,例如生成虛構角色、卡通人物或簡單的動畫場景。AI可能用於影片編輯,包括特效、轉場和影片修剪等功能。這些技術通常用於製作電影、廣告、教育和娛樂等各個領域的影片。AI生成的影片通常能夠更快速、自動化地創建影片內容,提供更多創意的可能性,並在視覺和聽覺上為觀眾帶來更豐富的體驗。
以 AIGV 降低影片製作成本
近年來,影片製作成本一直是影片產業的一大挑戰。從拍攝、剪輯到特效製作,每個階段都需要龐大的資金投入。隨著科技的演進,人工智慧逐漸成為降低影片製作成本的一個關鍵因素。首先,人工智慧在拍攝階段的應用大大提高了效率;傳統上,拍攝一場戲需要大量的人力與時間,而且常常需要進行多次的取景,利用人工智慧的技術,可以在較短的時間內找到最佳的拍攝角度,減少不必要的重複取景,從而節省了製作時間和成本。其次,人工智慧在剪輯階段也發揮了極大的作用;傳統的影片剪輯需要專業的剪輯師,而且可能需要多次修改才能達到理想效果。透過人工智慧的影像辨識和分析技術,可以快速地找到最佳的鏡頭並進行自動剪輯。這不僅節省了人力成本,還提高了剪輯的效率和準確性。此外,人工智慧在特效製作方面也有顯著的貢獻;傳統的特效製作需要龐大的計算資源和專業的技術人才。透過深度學習和機器學習算法,人工智慧可以更迅速地生成高質量的特效,減少了專業技術人員的需求,同時降低了硬體投資成本。人工智慧的應用為影片製作帶來了效益。它不僅提高了製作效率,還降低了製作成本,使得更多的人有機會參與到影片製作的領域中。隨著人工智慧技術的不斷進步,我們可以預見未來影片製作成本將繼續被有效地降低,為影片產業帶來更多的創新和可能性。
AIGV 平台架構
AIGV 平台包含了資料處理層、引擎層與應用層,如下圖1。資料處理層處理 Image, Video, Text 相關的資料前處理與模型訓練,使用 PyTorch Framework 來實現,檢查和評估模型並進行測試影像生成,完成 Stable Diffusion 穩定擴散模型的訓練後,在測試資料集上進行驗證,以檢查其性能品質。引擎層增加更多商業邏輯,包含依據商業需求做模型 fine-tune。應用層則利用微調後的模型,整合其他資源,提供使用者服務。
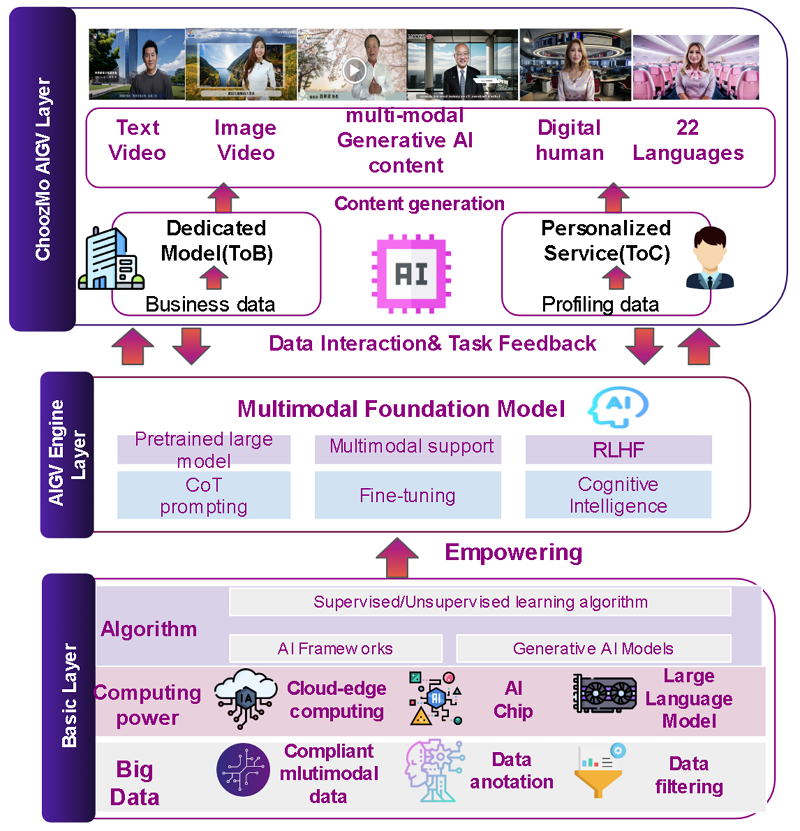
圖1 AIGV 平台架構
AIGV 模型調校,以符合在地風情
模型架構
本章節介紹集仕多公司「112年新竹縣地方產業創新研發推動計畫」,「客家特色高擬真AI算圖模型建置與應用」計畫成果的模型微調方法,使用 Stable diffusion v1.5,以 LoRA為架構進行微調。Stable Diffusion 是一種生成式AI模型,是在由512×512解析度圖像組成的數據集上訓練出來的,其得以透過文字和影像提示產生獨特、逼真的影像。Stable Diffusion 有多個版本,其中 Stable Diffusion v1.5使用了預訓練的文本編碼器(CLIP ViT-L/14)。Stable Diffusion v1.5模型是 Stable-Diffusion-v1-2 模型權重的初始化版本,並在 "laion-aesthetics v2 5+"上進行了595k步的微調,解析度為512x512的圖片,以提高 CFG sampling(Classifier-free guidance sampling)的效果
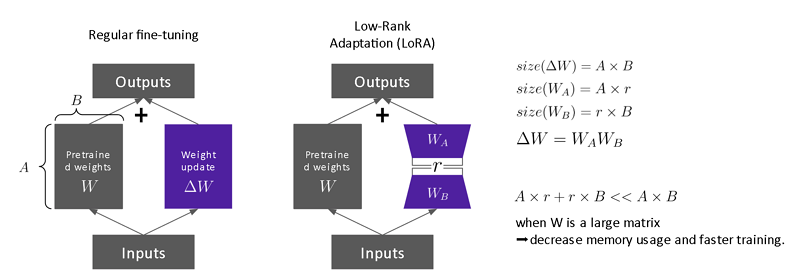
圖2 模型 Fine-tune 方法
Stable Diffusion 的架構主要包含三部分:Autoencoder(VAE)、U-Net和Text-encoder (CLIP text encoder)。Autoencoder 是一種特殊的神經網絡,用於將圖像從像素空間壓縮到低維的潛在空間,再將其解碼回像素空間;U-Net 是一種卷積神經網絡,用於圖像分割和圖像生成;Text-encoder 是一個文本編碼器,用於將輸入提示轉換為 U-Net 可以理解的向量表示。如圖2,本計畫使用 Low-Rank Adaptation(LoRA)方式做模型微調。
建立模型微調所需的資料集

圖3 客家特色食物柿餅圖片資料集範例
如上圖3,蒐集55張柿餅圖片作為模型微調使用的資料集合,並且圖片與文字說明的對應。如下表1,以 BLIP 模型生成的圖片說明文字為基礎,加入前綴詞以加強模型對於圖片的理解,包含:'Asian female'、'flat noodles'、'Hsinchu County Hsinwawu Hakka Culture conservation Area'、'Hsinchu County Qalang Smangus'、'Hsinchu County The Sinpu-Fangliao Yimin Temple'、'Lei tea Lei cha'、'dried persimmon'、'Hakka printed cloth'、'Hsinchu County old street'、'Hsinchu County tea plantation'、'indigo dye'等,舉例如下表:
表1 訓練資料集範例

生成客家特色圖片
模型微調後,下圖4左為本文模型生成的照片,可以成功生成新竹柿餅,但也會有柿餅掛在樹上的錯誤,後續可透過更多的訓練資料集來調整。下圖4右為原始stable diffusion模型,無法生成新竹柿餅這類在地特色圖片。

圖4 生成客家特色圖片
生成影像品質評估 Sampling Steps 與 CFG Scale
Stable Diffusion 藉由兩個關鍵參數:CGF scale(Classifier-free guidance scale)和 Steps(迭代次數)來調控生成過程。
在 Stable Diffusion 模型中,CFG scale 是一個控制提示對生成圖像影響程度的參數,意即其決定了模型多大程度上遵循使用者提供的文字提示。當 CFG scale 值較低時,模型在生成圖像過程中對使用者的提示不那麼敏感。這意味著生成的圖像可能會更加抽象,與使用者的具體提示有一定的偏差。相反,高 CFG scale 值會使模型嚴格遵循使用者的文字提示。這可以產生非常精確和與提示緊密相關的圖像,但過高的 CFG scale 也可能導致過度擬合關鍵字,使得圖像的多樣性和創造性降低,有時甚至出現品質下降的情況。
Sampling Steps 指的是模型在生成圖像過程中進行的迭代次數。每一步都是模型根據當前生成的圖像和使用者提示進行自我調整的機會。使用較少的迭代步數會使生成過程更快,但可能導致圖像細節不夠精細或與使用者提示有較大偏差。相反,較多的迭代步數意味著模型有更多機會細化和改善圖像,這通常會產生更精細、更貼近使用者提示的結果。然而,這也意味著更長的生成時間和更高的計算成本。
因此,透過適當調整 CGF scale 和 Steps,可以更好地控制圖像生成過程,以達到預期的效果。以下為根據訓練完成的客家模型實驗 Sampling Steps 和 CFG Scale 對圖像生成品質影響的結果呈現。每一行代表不同的 CFG Scale 值,每一列代表不同的 Steps。如下圖5。
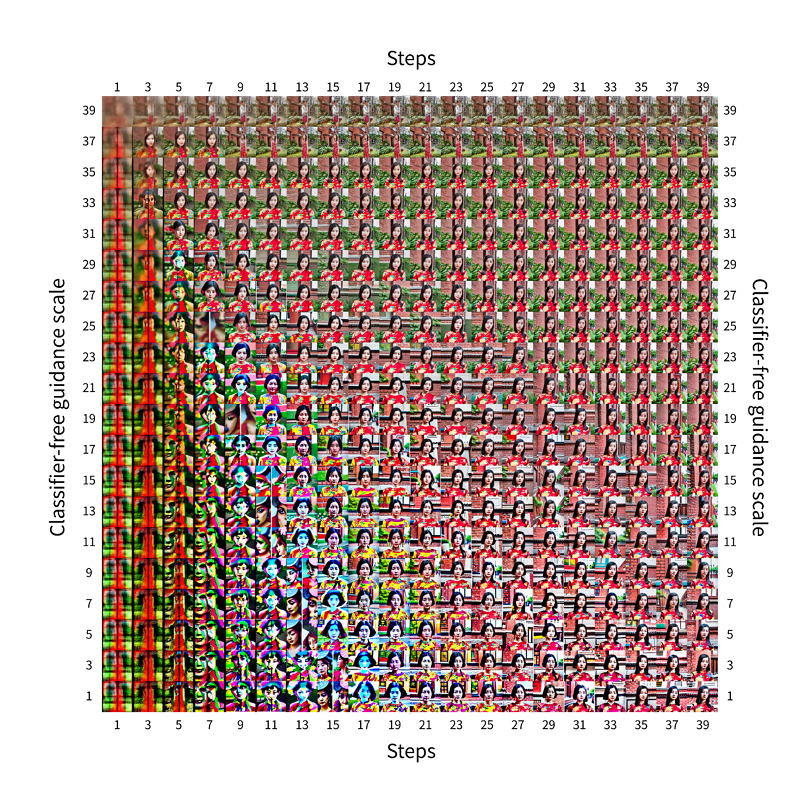
圖5 客家模型實驗 Sampling Steps 和 CFG Scale 對圖像生成品質影響的結果呈現
測試用的Prompt: real photography of beautiful young asian woman ((Hakka floral cloth style dress)) standing in front of ((the red brick building)) looking at viewer. ((full body)), best quality, photo realistic portrait, fair skin, ((symmetrical eyes)), happy. detailed skin texture and pores, detailed eyes, detailed lips, detailed mouth, detailed nose, detailed hair. Prompt: real photography of beautiful young asian woman ((Hakka floral cloth style dress)) standing in front of ((the red brick building)) looking at viewer. ((full body)), best quality, photo realistic portrait, fair skin, ((symmetrical eyes)), happy. detailed skin texture and pores, detailed eyes, detailed lips, detailed mouth, detailed nose, detailed hair.
- 左下角(低 CFG Scale,少 Steps):圖像非常模糊和雜亂,幾乎看不出有任何明確的結構或形狀。顯示在此參數設定下,模型無法有效地按照提示生成圖像,因為它既沒有足夠的 Steps 來細化圖像,也沒有足夠的 CFG Scale 來從提示中獲得明確的指導。
- 右下角(低 CFG Scale,多 Steps):隨著 Steps 增加,圖像開始顯示更多結構,但由於 CFG Scale 仍然較低,圖像與原始提示的相關性可能仍然不高。
- 左上角(高 CFG Scale,少 Steps):即使在 Steps 較少的情況下,高 CFG Scale 也可以使圖像更接近於具體的提示,但由於迭代次數不足,圖像可能仍然缺乏細節和清晰度。
- 右上角(高 CFG Scale,多 Steps):在這裡,我們可以看到最清晰、最貼近原始提示的圖像。這是因為高 CFG Scale 確保了模型嚴格依循提示,而多個 Sampling Steps 則給予了模型足夠的機會來精細調整圖像,產生高質量的輸出。
- 最右上角的圖像對應於高 CFG Scale 與多 Sampling Steps 的組合。這樣的設定通常期望能產生高質量、與提示詞緊密相關的圖像。然而,圖片中的過度擬合使用者給予的提示詞,導致五官等細節可能變得模糊不清。
整體而言,當 CFG Scale 和 Sampling Steps 同時增加時,圖像的清晰度和與提示的相關性也增加。然而,過高的 CFG Scale 可能導致圖像的多樣性降低,而過多的 Steps 則會大幅增加計算資源的需求。從以上圖片觀察,較適合此客家模型的 CFG Scale為19~35,steps 則為23以上。
日本應用案例
集仕多 AIGV 平台與企業系統整合公司合作,透過 AIGV 平台製作內部影片。該公司有包含投資人關係影片、內部訓練影片、新人招募影片、新人訓練影片等等大量影片製作需求,目前影片以該公司內部員工自行拍攝為主,每次拍攝都需要請簡報者到特定攝影棚,內容由於專業且冗長,員工並非專業講者,時常出現錯誤 NG 需要重新拍攝,因此一段30分鐘左右的新人招募影片,包含 NG 重新拍攝,需要拍攝六至八小時,並且需要三天左右做後製與剪輯。由於員工非專業講者,講述內容時,表情有時較為生硬,多次 NG 重複錄製,也讓表情較沒精神。導入 AIGV 平台使用數位人物取代真人,流程如下圖6,進行人物模型建置與聲音模型建置,模仿該員工製作內部訓練影片。
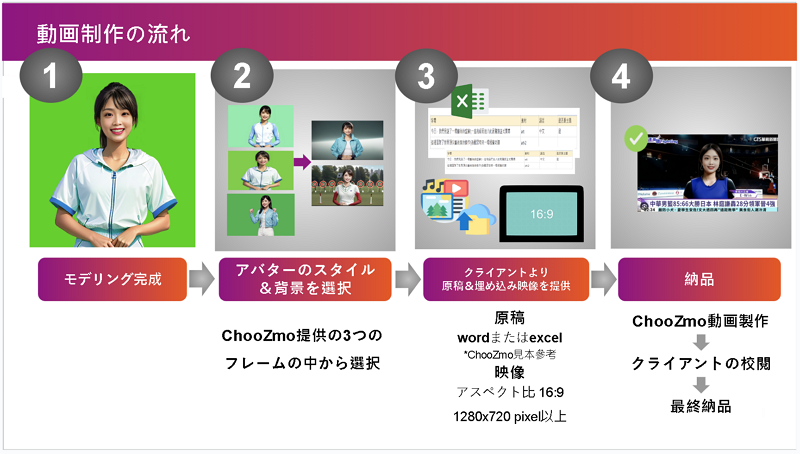
圖6 人物模型客製化流程
最終成果如下圖7,下圖左為原始28分鐘版本影片,由內部員工拍攝,下圖右為需要三天左右做後製與剪輯。由於員工非專業講者,講述內容時,表情有時較為生硬,多次 NG 重複錄製,也讓表情較沒精神。導入 AIGV 平台使用數位人物取代真人,流程如下,進行人物模型建置與聲音模型建置,模仿該員工製作內部訓練影片。下圖右為 AIGV 平台製作支影片,由於使用 text-to-speech,所以全長增長為31分鐘,比較人工拍攝與 AIGV 平台影片製作時間,使用 AIGV 之後,製作影片節省了82%時間。

圖7 左為原始人工拍攝影片,右為 AIGV 生成人物重製之影片
結論
短影音、長影音已經成為民眾日常生活最頻繁接觸的媒體之一,但影片拍攝與製作成本遠高於一般圖文格式的文章寫作,所以對海內外中小企業而言,需要投入一定資源才能製作出企業內部或是對外宣傳影片。導入 AIGV 後,可節省影片製作時間,並且可用於多種語言與多個國家,本文介紹集仕多公司協助日本公司導入 AIGV 技術將新人招募影片的製作時間減少82%,預期將可應用於更多其他影片,包含知識介紹、內部訓練、技術傳承等等多語言與多國應用。
參考文獻
[1] Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2] Ruiz, Nataniel, et al. "Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[3] Lu, Haoming, et al. "Specialist Diffusion: Plug-and-Play Sample-Efficient Fine-Tuning of Text-to-Image Diffusion Models To Learn Any Unseen Style." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[4] Wu, Jay Zhangjie, et al. "Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Fan, Ying, et al. "Reinforcement learning for fine-tuning text-to-image diffusion models." Advances in Neural Information Processing Systems 36 (2024).
[6] Ma, Jian, et al. "Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning." arXiv preprint arXiv:2307.11410 (2023).