工研院資通所 陳柏瑋、羅賢君、吳建達、張國強、沈志堅
透過各種唾手可得的智慧聯網產品,智慧生活已經悄悄融入我們的社會。近年在深度學習、類神經網路的快速進展之下,更是豐富了人工智慧(AI)的應用深度,尤其在多媒體應用獲得廣大的市場效應與迴響。雖然AI應用已然成形,但專用AI晶片的發展卻仍面臨量少、客製規格多、缺少設計標準,造成晶片公司投入大量生產的過程面臨艱鉅挑戰,尤其是深層神經網路需要龐大的運算與記憶體需求,運算資源和耗電量使得產品市場定位困難,亟需一套同時能適應性的客製化、提升演算法效率、提升晶片系統效率的完整解決方案,來落實AI晶片設計的產業化。
精彩內容
1. 客製化AI加速器晶片設計流程
2. AI加速器晶片架構與軟硬整合設計
3. AI系統晶片概念產品、應用展示
4. 高度適應性的AI晶片系統解決方案 |
客製化AI加速器晶片設計流程
深度學習演算法的設計是依據大量具有標示意義的資料庫進行訓練,且根據不同的應用目的如:物件分類、物件辨識、語意辨識等,所設計的演算法架構有著許多的變化,如最基本的全連接(fully connected)架構、卷積(convolution)架構、殘差(residual)架構、分支連接(concatenate)架構以及深度方向卷積(depth-wise convolution)架構等。這些架構各有特色,可有效的提升演算法精準度,或是降低演算法的參數數量以及計算量。
根據不同演算法架構,設計具有高效率的AI加速器的方向將會有所不同[1]。因此,我們整合了團隊經驗、利用開放原始碼資源、並與國內業界組成策略聯盟,提出了完整的客製化AI晶片設計流程如圖 1。這個解決方案有三大進程,首先在需求分析(analysis)的部分,我們考慮了根據演算法架構特性與硬體需求規格而歸納推薦的硬體設計參數;其次是依據此設計參數合成適當的硬體架構與演算法參數轉譯(硬體架構合成,synthesis);最後是依據系統最佳化所需呈現之應用程式介面(API)與編譯器之結果整合,完成演算法推論的加速與應用(inference)。
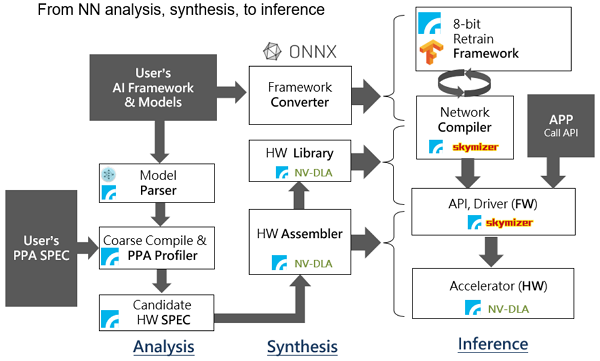 圖1 針對客製化深度學習加速器的整合設計流程,整合開源資源與廠商策略結盟。
圖1 針對客製化深度學習加速器的整合設計流程,整合開源資源與廠商策略結盟。AI加速器晶片架構與軟硬整合設計
.評估深度學習演算法在加速器上的執行效能
深度學習演算法通常擁有巨量的權重參數(weight)與數值運算,並且對於所需求的記憶體搬移頻寬(bandwidth)與計算能力(computing power)有不同需求程度。因此對於軟硬整合、演算法和加速器共同設計的第一步,就是根據加速器架構特色,預估分析深度學習演算法的實際效能,從中發現模型改良的方式。針對於此,我們發展了圖形化介面的深度學習演算效能分析軟體,這是藉由開放原始碼的netron專案[2]作為網路解析器,加入我們AI晶片架構模擬資訊之後,可提供視覺化的效能評估、網路結構融合策略、與資料流分析。在使用上,請參照圖 2,首先輸入加速器架構組態,其次輸入神經網路描述檔案,第三在載入神經網路描述之後,在[view]這個選項下,可以列出該演算法在各個硬體規格下的使用效率、推論運算時間、分層資訊,提供設計者回顧與檢視模型細部的效能表現。這套軟體有免費的體驗版本,可提供主記憶體僅有DRAM的預估效能,並支援Caffe神經網路描述模式。而商業技轉版本則提供更多資訊,包含主記憶體是SRAM與DRAM混合使用的效能,也會提供更多神經網路描述格式(ONNX、TensorFlow),以及客製化參數調整。
 圖2 根據硬體架構特性,預估演算法效能的視覺化工具,用於模型效能分析優化
圖2 根據硬體架構特性,預估演算法效能的視覺化工具,用於模型效能分析優化.客製化可重組的AI晶片架構設計
我們的AI晶片架構是根據開放原始碼的NVDLA專案延伸設計,跟原始開源的部分比較方面,主要貢獻在於:從無到有開發應用工具, 完成神經網路組件的翻譯器(translator)、測試產生器(test generator)、修整錯誤(de-bug)並且新增重要運算功能包含深度方向卷積(depth-wise convolution)、新增有效率的上取樣(up-sampling),並完成多種典型神經網路應用展示。 在客製化可重組部分,這個AI加速器是一個協同處理器,由「四加一」處理器所構成,四大處理器分別是卷積處理器、純量處理器、池化處理器、非線性處理器,另外可選擇性再加一個客製化的處理器,以適應未來AI發展新興的演算法運算。卷積處理器可提供從64到2048不等的乘法器數目;純量處理器提供量化(quantization)、批量歸一化(batch normalization)運算、加減乘除與精確度換算等,純量處理器的可提供幾種組態給使用者挑選;池化處理器負責取樣處理,非線性處理器則是非線性函數的查表處理,此後二者處理器則是可選擇使用或捨棄。這個協同處理器透過標準的AXI和APB介面和主系統溝通,可以適用於各家族MCU和CPU。使用者須使用我們的工具鍊翻譯神經網路後,成為控制這「四加一」處理器的功能函式,並以應用程式介面包裝,由主程式以呼叫功能方式進行運算。
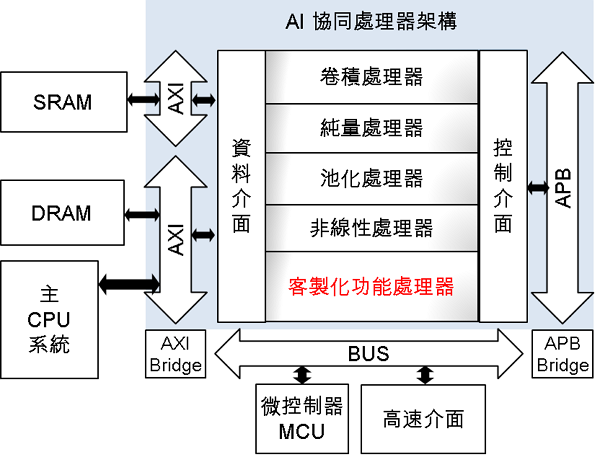 圖3 可客製化與重組修改的AI晶片系統架構
圖3 可客製化與重組修改的AI晶片系統架構.建立適用於硬體架構之模型量化轉譯服務模式
我們針對上述AI加速器架構建立了模型量化技術[7],依照客戶的經營型態,提供訓練完畢後的量化(PTQ, post-training quantization)、以及可以依據量化型態進行的重新訓練(QAT,quantization-aware training),如圖 4所述。在PTQ的流程中,客戶僅提供已訓練完成的高精度參數、以及少量的驗證資料,便可透過我們的量化工具進行加速器的參數編譯等工作,進而整合至驅動程式與硬體之中。在QAT的流程中,我們首先幫客戶建立正確的QAT訓練框架,再由客戶返回訓練私有的數據庫,如此有效萃取資料量化後的特性,使量化誤差最低。在這個高度整合加速器的量化服務中,需要依照加速器架構、融合多層的編譯結果後,在訓練框架內插入正確的量化點、數值縮放點、數位精確度飽和點等設定,使訓練框架內就可完整反映硬體整數運算的特性。
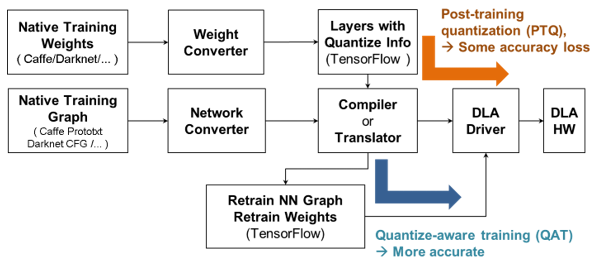 圖4 依據硬體架構的模型量化轉譯服務模式
圖4 依據硬體架構的模型量化轉譯服務模式在實驗結果方面,我們已經完成了主流演算法的架構,其準確度與原始差異列如表 1。在傳統卷積的架構中,我們測試了有名的一階段式物件辨識演算法(one-stage object detection),YOLO [3],並以物件辨識平均精確度做為比較依據。在各種重要的神經網路架構中,我們測試了殘差(residual)架構所需的逐點加法[4]、嵌入(inception)架構所需的分支連接(concatenate) 運算[5]、以及深度方向卷積(depth-wise convolution)運算[6]等,達成低誤差的量化框架建立。由於目前深度學習演算法的基礎架構大致為以上幾項運算單元的變形與組合,因此我們的解決方案已可滿足大多數現今主流深度學習演算法之應用。
表1 量化轉譯(QAT)後,各演算法構件在整數與浮點數的準確率差異
| 功能 |
General CNN |
General CNN |
Residual |
Concatenate |
Depth-wise |
| 代表模型 |
Tiny YOLO v1
|
Tiny YOLO v2 |
Resnet |
Inception
|
MobileNet |
| 比較標準 |
平均準確率(mAP) in VOC2007 |
第一名準確率 (TOP1) in ImageNet |
| INT-8 |
38.08 |
48.03 |
67.59 |
75.64 |
61.02 |
| FP-32 |
40.86 |
49.92 |
68.96 |
78.91 |
60.93
|
AI系統晶片概念產品、應用展示
我們的AI系統晶片產品規劃有兩種型式,一種是高整合的單晶片加速器雛形,目前是用可程式化邏輯(FPGA)開發板來驗證(如圖5),未來將整合CPU與AI加速器於單晶片,可獨立包裝成一個產品。另一種則是以加速卡或加速棒的形式,搭配既有之嵌入式電腦系統,選配各種工業或家用電腦(如圖6)。展示影片請參考以下網址:https://youtu.be/CPV7HzP3apQ。使用者也可以透過我們公開的體驗套件,從以下Github公開倉庫,自行體驗合成、添加影片媒體來執行體驗三種典型的神經網路應用 https://github.com/SCLUO/ITRI-OpenDLA。這個展示在設計工具套件是商業授權模式並未開放,但在FPGA體驗部分採取開放授權,歡迎大家試用並給予我們回饋。
 圖5 高整合單晶片開發形式
圖5 高整合單晶片開發形式  圖6 加速卡/棒開發形式 for Legacy Support
圖6 加速卡/棒開發形式 for Legacy Support高度適應性的AI晶片系統解決方案
在這個應用多樣、規格多樣的AI世界裡,需要高度適應性的解決方案才能靈活產品開發。我們歷經兩年努力研發,目前已可提供:
1.客製化運算能力的AI加速器架構:提供多樣化規格,根據客戶應用規格需求,調配最適當的硬體資源。
2.神經網路工具套件:可以翻譯神經網路,成為硬體運行的API執行碼,並且可以使用通用的硬體模擬方式(verilog simulation)驗證,測試完整的神經網路運算,獲得最準確的效能數字。
3.具加速器特性的神經網路效能分析器:提供立即的效能預估,這個效能與精確硬體模擬約差10%,足以讓使用者根據加速器特色最佳化模型設計。
4.量化訓練流程諮詢與轉譯服務:提供業界透明、可進行除錯分析、搭配硬體加速器的QAT量化流程,透明的技術轉移,提供業界學習自主開發能量。並且持續更新AI的潮流與發展,冀期對台灣AI產業化能有所貢獻。
參考文獻
[1] 羅賢君等,深度學習軟硬體加速器探索,電腦與通訊期刊,174期,2018-08-02
[2] Netron: Viewer for deep learning models, https://electronjs.org/apps/netron
[3] Redmon, Joseph, and Ali Farhadi. "YOLO9000: better, faster, stronger." Proceedings of the IEEE conference on computer vision and pattern recognition. (2017).
[4] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[5] Szegedy, Christian, et al. "Rethinking the inception architecture for computer vision." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[6] Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
[7] Krishnamoorthi, Raghuraman. "Quantizing deep convolutional networks for efficient inference: A whitepaper." arXiv preprint arXiv:1806.08342 (2018).
相關連結: 回180期_AI晶片與系統專輯