工業技術研究院 資訊與通訊研究所 林宏軒 王莉珮 李宇哲 黃名嘉 李冠德
AI晶片與AI辨識模型皆是針對單張影像辨識出影像內的物件,而許多應用場域皆是針對監控式攝影機所拍攝的視訊影像實現即時AI辨識,達到即時監控的目的,本文將介紹對於即時拍攝的大量影像該如何有效率地以AI完成辨識。
精彩內容
1. 即時視訊辨識應用場域
2. 神經網路視訊辨識作業系統架構
3. 作業系統辨識優化效果 |
即時神經網路視訊辨識應用場域
根據Quartz的報告,2021年全球網路上傳輸的最大宗資料為視訊影像,占比高達82%,相比於2016年的占比73%,明顯成長許多,甚至在未來5G普及的時代,傳輸的影像畫面解析度與影像數量又將大幅提升,占比也將進一步提高。而當視訊影像增多的情況下,傳統以人力為主的監看行為將難以負擔並最終成為過去式,結果將是改成以AI為主的監看方式,而這邊所指的AI就是以神經網路架構所訓練而成。同時,根據Gartner的統計,全世界前百大企業有高達40%認為,AI是改變產業競爭規則的最主要原因。
而當AI成為主要視訊監控手段之後,即時性的監控需求也紛紛出現。不同於把影像儲存於伺服器,當有事情發生時才把影像取出進行回放的傳統模式,現在各種場域的影像皆開始逐漸要求即時辨識,希望在第一時間即時偵測出各種可能的不正常狀況,或是發展各種以AI主導的即時視訊新興應用。比如說以工廠、園區為主的廠區安全,進行各種人安、車安的區域安全辨識;或是以單一建築物為主,在建築物內的各處死角進行安全監控;或是針對智慧城市、智慧娛樂、智慧工廠等各類智慧化應用,發展例如城市智慧化自動收費、娛樂智慧化導播、工廠產線智慧化管理等各種新興AI即時視訊辨識應用。
以單一建築物的辨識為例,在建築物內設有大約250支監視器需要即時辨識,假設每5支監視器攝影機需要1片以高階圖形處理器(GPU)進行AI辨識運算,那麼總共需要50片高階圖形處理器,而這50片高階圖形處理器與伺服器主機的價格,估計需要將近新台幣1,000萬左右。昂貴的AI辨識硬體成本容易成為AI應用擴散的阻力,因此需要神經網路辨識作業系統,將圖形處理器的運算能力在影像辨識上的發揮達最佳化。
神經網路視訊辨識作業系統架構
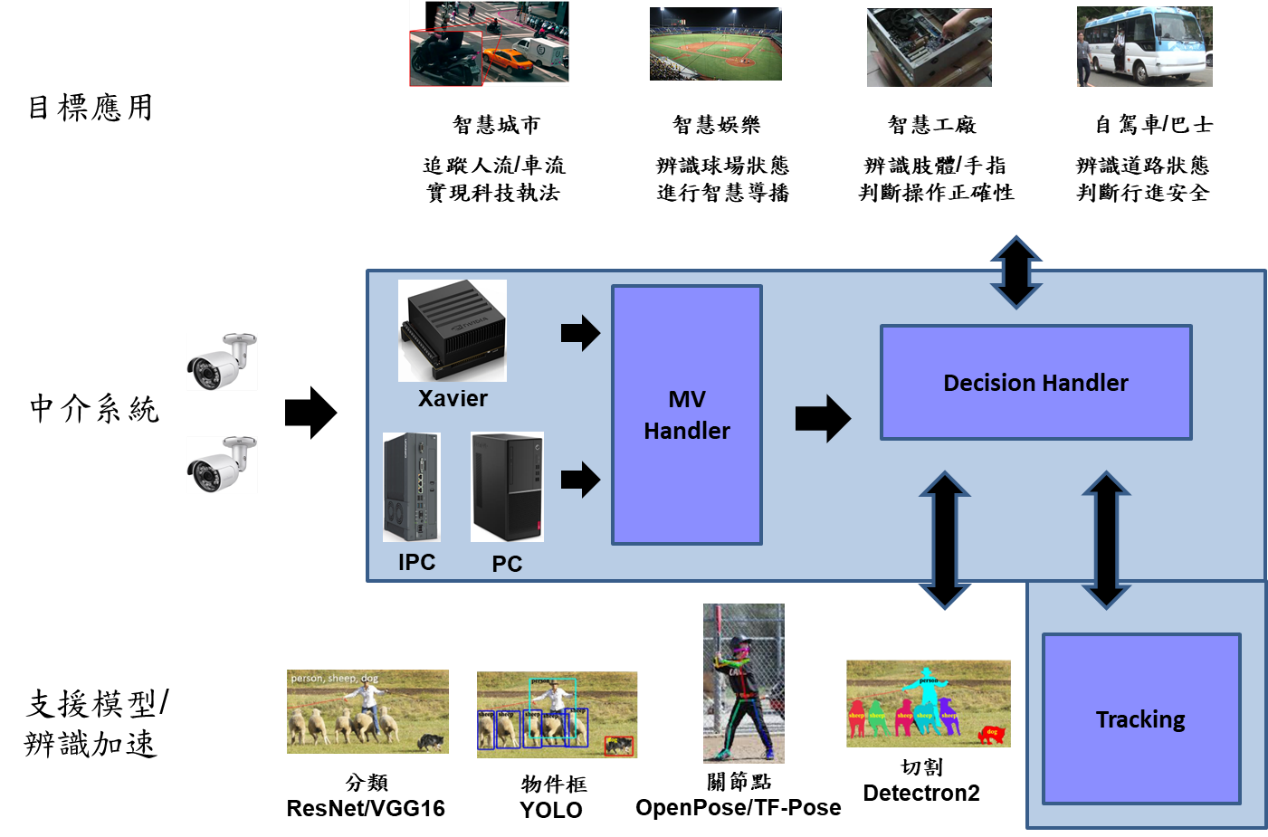
圖1 神經網路視訊辨識作業系統為一個中介軟體系統。
如上圖1所示,神經網路視訊辨識作業系統為一個中介軟體(Middleware),介於上層的應用影像與下層的AI辨識模型之間。原本從應用場域監視器所收到的影像要傳送給AI模型進行辨識時,改為傳送給神經網路視訊辨識作業系統,系統會根據當前監視器連續影像的內容與當前狀態,自動判斷目前的影像需交由AI模型辨識,或以其他較簡單的高效率方法辨識出來,而會被稱為作業系統,就是因為此系統具有排程AI辨識的能力。
神經網路視訊辨識作業系統提高AI辨識效率的主要方法,是根據監視器連續性多張影像之間的相似特性,利用前一張影像的辨識結果,以物件追蹤的手法辨識出當前影像的物件所在位置,以此快速辨識出當前影像物件。但由於物件追蹤手法只能追蹤前一張影像中的既有物件,無法偵測出當前影像才出現的新進物件,因此需額外再搭配非AI的新進物件偵測技術,補足物件追蹤的缺點。在整個辨識過程中若物件追蹤或新進物件偵測有任何準確度不足的情形,也可即時改由AI辨識,避免辨識準確度下降。
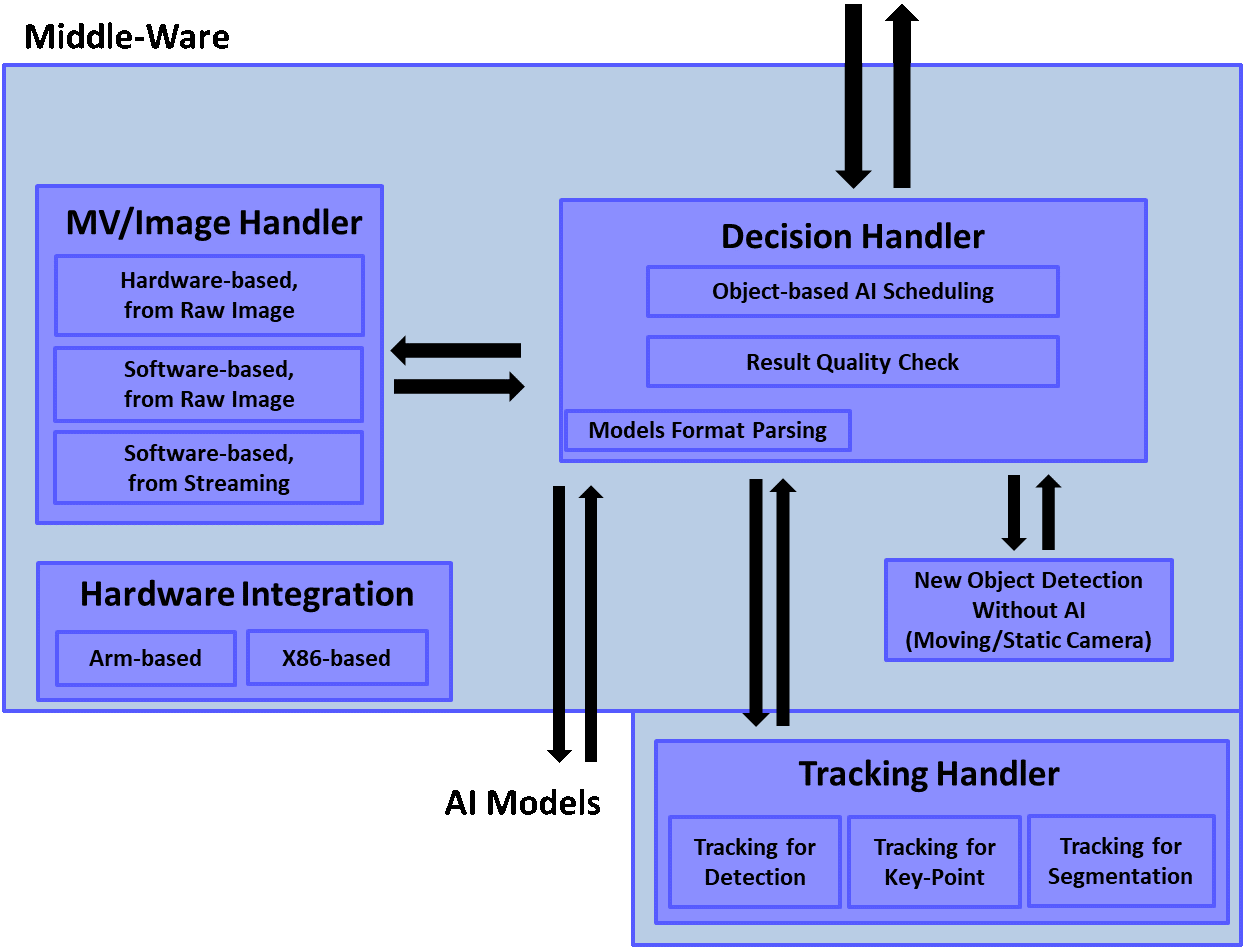
圖2 神經網路視訊辨識作業系統架構。
上圖2為神經網路視訊辨識作業系統架構,由於此辨識作業系統的辨識效率優化主要手法使用到了視訊中連續多張影像之間的相似特性,因此可使用傳統影像處理手法中的光流(Optical Flow),以及在壓縮串流影像過程中所使用到的移動向量(Motion Vector),位於上圖中的左邊模組,所取得的光流與移動向量,將提供給圖中右下方的追蹤模組,而所有大小模組之間的溝通與決策層則位於圖中的右上角。
本章的後續小節,將依序介紹光流與移動向量、物件追蹤手法、新進物件偵測、辨識排程等技術。
移動向量與影像處理程序(MV/Image Handler)
移動向量與光流皆可以針對影像畫面中指定的像素(Pixel)找出在下一張影像畫面中該像素的新位置,以此得出此像素的位移。其中光流通常僅針對單一像素做尋找,在使用時可以針對畫面中的所有像素,尋找這些像素的個別位移,也可以指定部分比較特殊或具代表性的像素,例如畫面中物件的角點、邊框等。
移動向量主要是以影像畫面中的4X4、8X8或16X16個像素所組成的巨集區塊(Macro Block)為單位,找出這些像素在鄰近影像畫面中的所在位置。移動向量是用在影像的串流壓縮,以16X16個像素為例,比起儲存這256個像素的所有像素代表值,串流中所儲存的資料只會是一個座標指到鄰近影像畫面中的所在位置,以及與該所在位置的256個像素的差異值,而由於這些差異值通常不會太大,因此可用比較少的位元儲存,達到壓縮的目的。
整體而言,光流是以1X1的像素為單位找出它的位移,而移動向量是以4X4、8X8或16X16的像素為單位找出它的位移,而物件追蹤主要就是以MXN個像素為單位(假設物件為MXN大小)找出它的位移。
在神經網路視訊辨識作業系統架構中,可支援不同的影像輸入類型,包括串流影像輸入以及尚未壓縮成串流原始影像的輸入。針對串流影像輸入,實現了以軟體的方式從串流解碼取出移動向量;針對原始影像輸入,實現了以軟體的方式從原始影像中計算出光流或移動向量,以及支援常見AI終端裝置(如Nvidia Jetson系列)所支援的應用程式介面(API),以此加快在該硬體上計算光流或移動向量的速度。
追蹤處理程序(Tracking Handler)
在影像辨識模型類型中,除了物件分類以外,有給出物件位置座標的AI辨識類型可以分為以下3類:
- 辨識結果大於物件實際範圍:例如物件偵測模型(Object Detection)。
- 辨識結果等於物件實際範圍:例如物件切割模型(Object Segmentation)。
- 辨識結果小於物件實際範圍:例如關鍵點偵測模型(Key-Point Detection)。
由於在神經網路視訊辨識作業系統架構中是採用光流或移動向量進行物件追蹤,因此首先需找出物體在畫面中的所在位置,才能以物體所在位置區域範圍內所代表的光流與移動向量追蹤物體新位置。而對於辨識結果大於物件實際範圍的模型,需要先區分出辨識結果中物體的實際所在區域,才可進行追蹤,其餘兩類的模型則不用。
以移動向量實現物件追蹤辨識的情境如下圖3至下圖5所示,透過物件上的移動向量(圖中的白色與綠色箭頭)的指向,可綜整計算出物件的移動變化量,適用於物件偵測模型、物件切割模型與關鍵點偵測等模型。

圖3 基於移動向量的物件偵測追蹤。

圖4 基於移動向量的物件切割追蹤。

圖5 基於移動向量的關鍵點偵測追蹤。
以非AI方式實現的新進物件偵測(New Object Detection without AI)
在神經網路視訊辨識作業系統架構中,對於串流輸入的每張影像,部分影像會使用AI辨識,部分會使用物件追蹤,而對於物件追蹤的影像,需要輔以新進物件偵測技術,避免遺漏新出現的物件。在大部分的應用中,會需要立即在當前影像就偵測到新進物件占的比例較少,通常是需要立即反應的場域,例如自駕車。而其他的類型比如說監控型場域如園區、道路監控等,等到有進行AI辨識的影像再偵測到新進物件即可。
在自駕車場域中,會需要即時反應的新進物件大多為自主移動物件,例如從旁超車或從巷弄駛出的移動車輛等,因此新進物件偵測技術主要是偵測這些因移動而忽然進入畫面中的物件。
在整張畫面中,由於自駕車本身有在移動的原因,因此畫面中的物件即使自身沒有移動,畫面中的物件也會有相對的位移出現。這些因為自駕車本身的移動所造成的相對位移所呈現出的光流或移動向量數值,稱為背景光流或背景向量。而若畫面中的物件本身有在移動,所呈現出的則為前景光流或前景向量。
而以非AI方式實現的新進物件偵測,最主要的核心概念就是在整張畫面的背景光流或向量中,找出跟整體背景光流或向量趨勢中不同的區域,則可以判定為前景光流或向量,也就是移動物件所在的位置,以此達到偵測新進移動物件的目的。
決策處理程序(Decision Handler)的辨識排程
在辨識作業系統中,會對每個物件做物件追蹤,當畫面中有複數個物件時,有些物件可以追蹤得很準確,有些可能會追蹤不準確。追蹤不準確的原因可能有物件重疊、物件出現或消失在畫面中、物件變化較大等各種狀況。
當整張影像只有部分物件需要因為追蹤的準確度不夠高而改用AI辨識時,可僅針對該物件所在區域進行AI辨識,而不用整張畫面都重做AI辨識,而又因為AI可以專心僅在該區域辨識,因此準確度甚至有機會比整張畫面辨識時還高。而對於一張影像,該採用整張畫面辨識或部分畫面區域該採用AI辨識,以及該採用多少解析度辨識,皆以動態辨識排程技術,來根據影像與當前辨識狀態進行動態決策。
辨識作業系統優化效果
神經網路視訊辨識作業系統架構在套用到一個新場域時,僅需根據場域的影像狀態以及影像中物件的特性略做調校,即可有不錯的辨識優化效果。
在自駕車場域中,辨識道路前方物件的AI辨識速率由每秒68張提升至264張,共加速3.7倍,並且準確度維持在跟原本AI模型的準確度61%左右保持不變。而運用在辨識道路前方可行走區域範圍的AI辨識上,也可在保持準確度不變情況下加速約2.87倍。除此之外,運用在自駕巴士以8支攝影機同時辨識周遭環境情況下,也因為加速的關係降低了所需圖形處理器的所需運算量,從原本圖形處理器使用100%也無法滿足所有辨識需求的情況下,降低至僅需約40%的運算量即可滿足所有辨識需求。
在智慧娛樂的雙人桌球對戰場域中,AI辨識速率可由每秒31張提升至188張,共加速6.06倍,使單片GPU卡從可支援1台攝影機提升為可支援6台以上攝影機,節省所需GPU卡的硬體成本,並且結合辨識排程技術,將辨識準確度由42.54%提升為54.46%,共提升近12%左右,大幅提升AI導播的精確度。
結論
神經網路視訊辨識作業系統為一個中介軟體,可在既有影像辨識場域不需太大變動情況下加入使用,適用於影像物件偵測、物件切割、關鍵點等各類AI影像辨識,並且支援固定式監視器與移動式監視器等場域,適用於集中式伺服器與各類前端智慧終端裝置。
辨識作業系統可優化既有AI辨識結果,提升最高達約6倍的辨識速度,以及提升高達辨識準確度約12%,節省硬體成本最高達6倍並進一步優化AI結果。透過影像辨識的效率提升,亦可降低AI終端裝置的辨識耗電量,延長使用效率,並間接解決裝置的散熱問題。
參考資料
[1] Video traffic, from streaming services to webcams to video surveillance, will comprise 82% of internet traffic in 2021, from 73% in 2016.
https://index.qz.com/1001991/online-video-boosted-by-live-streaming-most-internet-traffic-in-five-years-will-be-video/